
C++从零开始(九):面对对象(下)继承和虚函数
🌟《C++从零开始》 系列,开始更新中…

七、继承和虚函数
7.1 继承
面对对象三大特性:封装、继承、多态,继承在面对对象中的重要性不言而喻。
本章主要探讨的问题:
- 为什么需要继承?
- 继承的访问权限和成员访问权限的区别?
- 继承的派生类出现和基类同样(函数签名、返回类型一致)的函数,会发生什么?
- 派生类对象构造时,是如何进行构造的?
- 多重继承优缺点及菱形问题。
7.1.1 为什么需要继承?
想象这么一个问题:如果存在一些简单、基本的对象,如何来创建一个新对象?
通常我们使用对象组合和对象继承两种方式。
-
对象组合。这符合我们最直观的认知,适合新对象与基本对象之间存在
has-a关系。例如,一个房间有一张桌子和凳子。我们创建一个
ClassRoom类,然后组合table和chair构成ClassRoom。1
2
3
4
5
6
7
8class ClassRoom // 教室
{
private:
Table _table; // 桌子
Chair _chair; // 椅子
public:
ClassRoom(Table table,Chair chair):_table(table),_chair(chair){}
}; -
对象继承,也是本节的重点。与对象组合通过组合其他对象来创建新对象不同,继承直接获取其他对象的属性和行为,然后进行扩展来创建新对象。
下面的
ClassRoom便继承了Room,获取了Room的price、area属性,然后再进行扩展。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class Room
{
private:
double _price;
double _area;
public:
Room(double price,double area):_price(price),_area(area){}
};
class ClassRoom: public Room
{
private:
Table _table; // 桌子
Chair _chair; // 椅子
public:
ClassRoom(Table table,Chair chair,double price,double area):
_table(table),_chair(chair),Room(price,area){}
};
上例的例子很好地展示了继承的作用:派生类通过继承来重用被继承类(基类),然后派生类可以添加、修改或隐藏相关功能来进行扩展。
这使得继承:
- 提高了代码的复用性、维护性
- 类与类之间产生了联系,这是多态的前提
不过另一方面,继承有违开发原则“高内聚、低耦合”,因为继承会增加类的耦合性(类与类之间关系变得紧密)。
whatever,善用继承是熟练运用OOP(Object Oriented Programming,OOP)思想的重要体现。
上面的例子也带来一些思考:
-
继承访问权限是什么?和之前的类成员访问权限有什么不同吗?
1
class ClassRoom: public Room
-
派生类怎么添加、修改或隐藏基类相关功能?
-
派生类实例化时,构造函数、析构函数的顺序有什么讲究吗?为什么存在这么一个顺序?
-
很多语言如Java是不允许多重继承的,而C++为什么要允许多重继承,多重继承会带来什么问题吗?
带着问题来和我一起认识一下吧。
7.1.2 继承相关概念
继承权限和访问符
先从类成员访问符说起,类成员访问控制符实现了类的封装。
1 | class Base |
回顾一下private、public访问符:
- private:私有成员,该成员仅在类内可以被访问,在类体外(包括派生类)是隐藏状态;
- public:公有成员,该成员在类内、类外也都可以被访问,是类对外提供的可访问接口。
在继承中,我们引入了第三种访问修饰符:
- protected:保护成员,和私有成员类似,不过在派生类可以被访问。
回到我们本小节的重点:继承权限的访问符。
派生类隐式包含了基类的副本。不同继承权限的访问符,本质就是修改基类副本的公有成员、保护成员,在派生类中的访问权限(私有成员不受影响)。
核心概念强调:
- 派生类并非是修改了原有类(基类)成员的访问权限,而是修改派生类持有基类的副本原本的访问权限;
- 继承方式对私有成员无影响。
不同继承权限的基类副本访问权限修改规则:
- public继承:所有基类成员副本都保持原有权限;
- private继承:所有基类成员副本被修改为private;
- protected继承:所有基类成员副本被修改为protected;
public继承是使用最常用继承方式,其次是private继承,protected继承基本不使用。
我们来实际验证下上述结论(protected继承不举例,因为基本不用)。
public继承。
注意到,派生类中的基类副本成员访问权限和基类一致。
1 | class Base |
private继承。
注意到,派生类中的基类副本成员的访问权限都被修改为private。
1 | class Base |
using修改访问权限
通过继承权限设置,虽然可以修改派生类基类副本原本的访问权限,但也有局限性:
- 不能修改基类副本单个成员访问权限,只能全部修改;
- 无法修改private成员权限(比如为private→public)。
using弥补了这个缺陷。
例如,我们可以只将基类某个公共成员设为私有(通常用来隐藏基类中某个功能):
1 |
|
自然,也可以将私有设为公有(不过这破坏了类的封装性,慎用):
1 |
|
函数重写
前面我们提到过继承的好处:“派生类通过继承来重用被继承类(基类),然后可以通过添加、修改或隐藏相关功能可以进一步扩展” 。
这里的:添加、修改或隐藏相关功能,是如何做到的?
答案是通过函数重写。
理解这个问题,首先要明白派生类对象是如何调用一个函数的(不考虑虚函数):
- 编译器首先查看该成员是否存在派生类中,如果不存在转2;
- 沿着继承链往上走,查看是存在任何父类定义中,如果不存在转3;
- 不存在该函数,调用失败。
函数重写便是利用这个调用顺序:在派生类中定义一个和基类完全一致(不止同名,而且函数签名、返回类型完全一致)的函数,在函数体对原有功能进行修改,达到添加、修改、隐藏相关功能。因为编译器首先调用的会是派生类中的函数。
看一个实例吧。
下面派生类中对基类的print 实现了隐藏,你永远无法通过派生类访问到基类的print方法。
1 | class Base |
输出:
1 | Derived |
完全隐藏基类的方法也许并不是你所需要的,但你还可以对基类的print添加功能。
1 | class Derived : public Base |
输出:
1 | Base |
同时,我们应该注意到函数重载和函数重写的异同。
- 函数重写分别位于基类、派生类,而函数重载位于同一类中。
- 函数重写的函数签名完全一致(不止同名),而函数重载仅仅是同名,函数签名并不同。
- 函数重写是运行时多态的一种体现(一个方法在不同的子类中表现出不同的行为),为了能对基类的功能实现修改、隐藏等而生,而函数重载是为了解决命名空间污染问题而生。
7.1.3 派生类构造函数
我们知道派生类继承至基类,那派生类进行实例化时:
-
基类部分由谁负责初始化?是基类构造函数吗?
-
派生类构造函数只负责初始化派生类扩展部分吗?
-
基类和派生类构造函数执行顺序是怎么样的?
构造顺序
上述答案分别是:
- 基类部分初始化由基类构造函数负责;
- 派生类构造函数只负责派生类扩展部分初始化;
- C++ 分阶段构造派生类,从最基类(在继承树的顶部)开始,到最子类(在继承树的底部)结束。
验证一下。
1 | class A |
输出:
1 | 构造 A: |
可以看到,
- C++ 总是首先构造“第一个”或“最基”类,然后它按顺序遍历继承树并构造每个派生类;
- 基类构造函数和派生类构造各自负责相应的部分。
顺便一提,析构函数执行顺序恰恰和构造函数相反。
为什么要按这种构造顺序?
子类继承了父类,了解父类的一切,且经常需使用父类的成员或函数,但父类对子类一无所知。为了安全,首先实例化父类可以确保父类成员在被派生类使用前,就已经准备好了。
另一方面,迄今为止,派生类实例化时的基类构造函数都是隐式调用的。
- 如果我们想在派生类初始化基类成员,该如何实现?
- 能不能直接显式调用基类构造函数初始化?
初始化基类成员
为了方便说明,先将基类成员m_id 声明为public,试想如何在派生类中对其初始化?
1 |
|
既然m_id已被声明为public,容易想到两种初始化方式:
- 派生类构造函数成员列表初始化;
- 派生类构造函数体内赋值。
但第一种方式不被C++允许,因为第一种成员列表方式会导致m_id 在基类和派生类初始化两次,而初始化只能有一次。
1 | class Derived: public Base |
第二种方式是允许的,因为这是重新赋值,不是初始化:
1 | class Derived: public Base |
但这有两个问题:
- 不够优雅,是重新赋值,而不是直接初始化;
- 如果
m_id是private/const/引用,这种方式也无法使用。
如果可以在派生类直接调用基类构造函数初始化,那该多好呀!
现在我们在派生类的构造函数成员列表中,显示调用了基类构造函数。
1 |
|
输出:
1 | In base, m_id = 1 |
以上完美解决了初始化基类成员的需求,但注意:
-
基类构造函数
Base{ id }只被执行了一次,依旧是从继承链顶部往下构造,派生类只是指定了基类构造函数的参数; -
成员列表的基类构造函数
Base{ id }的顺序无关紧要,无论如何,基类构造函数总是率先执行的:- 首先执行基类构造函数(根据派生类中指定的参数);
- 然后执行派生类构造函数成员列表初始化;
- 最后执行派生类构造函数体内代码。
7.1.4 多重继承
多重继承优缺点
在前面我们提到:
很多语言如Java是不允许多重继承的,C++为什么要允许多重继承,多重继承会带来什么问题吗?
这是个很有意思的问题,我们来说说多重继承的优缺点。
多重继承的优点很明显:简单,清晰,更有利于复用。
但它的缺点同样明显:
-
二义性。如果两个基类(B、C)具有同名的方法(do()),在派生类中必须指定此方法来源于哪个基类。如下图:
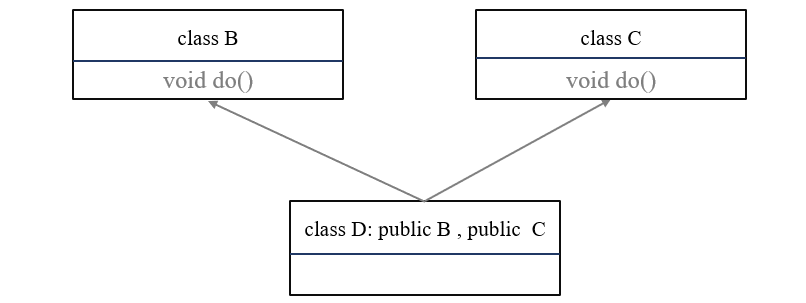
1
2
3D d{};
d.do(); // error
d.B::do(); // ::范围限定,ok -
菱形继承。但如果是菱形继承,不但会带来二义性问题,还会使得派生类中具有重复拷贝的问题。
如下图:
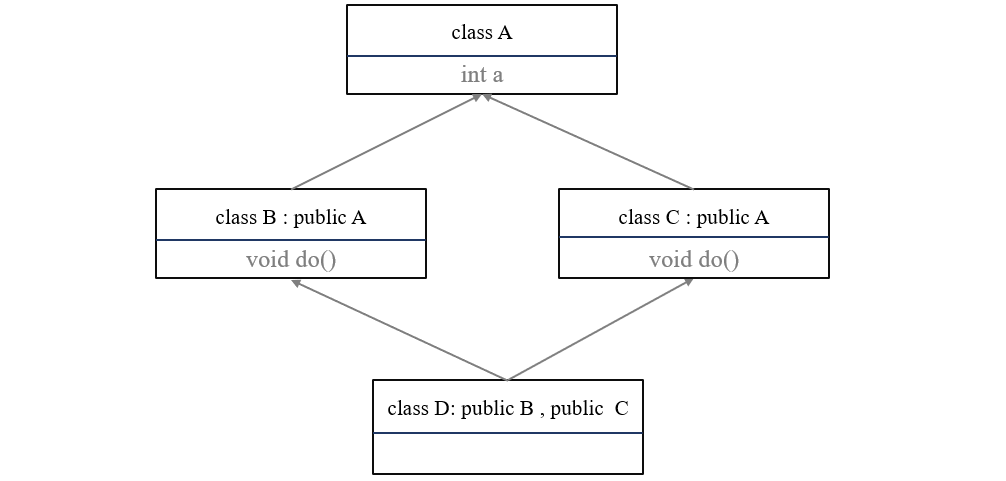
派生类D中拷贝了两份A的副本!另一方面这也加重了二义性问题,因为
a也存在了二义性问题,虽然它只在A中被定义了一次。1
2
3D d{};
d.a(); // error
d.B::a(); // ::范围限定,ok范围限定虽然能解决,但终究不是好方法,不够优雅,重复数据拷贝的问题也依旧存在。
这也是为什么C#和Java中不支持类多继承,而是使用类单继承和接口多继承设计替代类多继承。
既然C++选择了多重继承,我们来看看二义性和重复拷贝的问题如何解决:
- 二义性:可通过范围限定符
::消除二义性; - 重复拷贝:存在菱形继承中,通常使用虚继承来解决。
虚继承
类通过虚继承可以指出它希望共享的虚基类,对于虚基类,无论在派生层次中被继承多少次,都只存在一份共享的基类子对象。
在上例中,我们可以让类B、C都虚继承A,这样A在D中只会有一次拷贝。
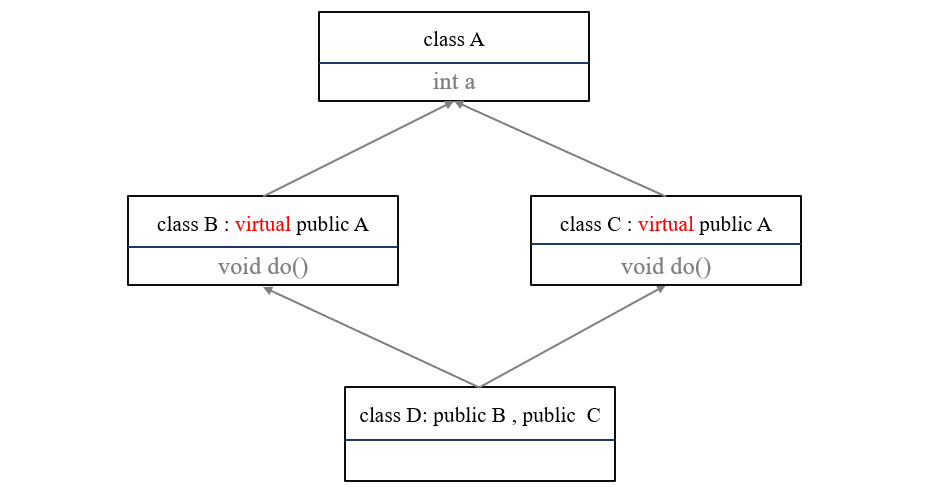
实际编码验证:
1 | class A |
B、C、D共享了同一份A的副本。
注意,虚继承只是避免了重复拷贝的问题,并没有消除二义性,B、C中doSomething 依旧存在二义性问题。
我们熟悉的istream和ostream 也是虚继承于ios :
1 | class istream : virtual public ios {...}; |
最后我们再来探讨下,虚继承和非虚继承方式的构造函数执行顺序:
- 非虚继承,构造函数执行顺序:A→B→A→C→D;
- 虚继承,构造函数执行顺序:A→B→C→D。
可见非虚继承中,A被初始化了两次,虚继承中A确实只被初始化了一次。
析构函数执行顺序恰相反:
- 非虚继承,析构函数执行顺序:D→C→A→B→A;
- 虚继承,析构函数执行顺序:D→C→B→A。
最佳实践
事实证明,大多数可以使用多重继承解决的问题,也可以使用单继承来解决。
另一方面,很多现代编程语言,如 Java 和 C#,将类限制为普通类的单继承,只允许接口类的多继承。
所以,我们应该尽量避免在C++中使用多重继承,除非:
- 这个时候多继承是最好的选择;
- 被多继承的类是设计良好的接口类。
7.2 虚函数
首先回忆下C++的多态性行为表现:对象在不同上下文环境会表现出不同的特性。
这有点抽象,我们具体一点。
C++支持两种多态:
- 编译时多态(静态多态):通过重载函数实现,函数地址早绑定,编译期间就可以确定函数的链接地址;
- 运行时多态(动态多态):通过虚函数实现,函数地址晚绑定,运行期间根据虚表来确定函数链接地址。
重载的同名函数,在函数签名不同(不同的上下文环境),会调用不同的函数(表现不同的行为)。
虚函数的作用便体现在C++的动态多态性上,可以根据调用函数的对象的类型(不同的上下文环境),会执行不同的虚函数(表现不同的行为)。
其大致实现过程如下:
- 首先,在基类的函数前加上virtual关键字,也就是虚函数,同时在派生类中重写该函数;
- 然后,声明基类类型的指针(或引用),该指针(或引用)会指向派生类对象;
- 最后,使用基类指针(或引用)调用该虚函数,如果指向对象类型是派生类,就调用派生类的函数;如果指向对象类型是基类,就调用基类的函数 。
这便通过虚函数实现了C++动态多态性,下面我们开始具体探讨:
- 基类指针/引用指向派生类对象,会发生什么?
- 虚函数是什么?虚函数实现多态的原理?
- 析构函数、构造函数和虚函数之间的一些问题?
- 基类指针/引用↔和派生类指针/引用之间的转换是安全的吗?(上行转换和下行转换)
- 对象切片引发的一些编码问题。
7.2.1 指向派生类对象的基类指针和引用
认识基类指针和引用
我们了解到,派生类由两部分组成:
- 继承的基类部分;
- 自身扩展的部分。
好了,愉快地接受这个设定后。下面类实例内存布局就很容易接受了:
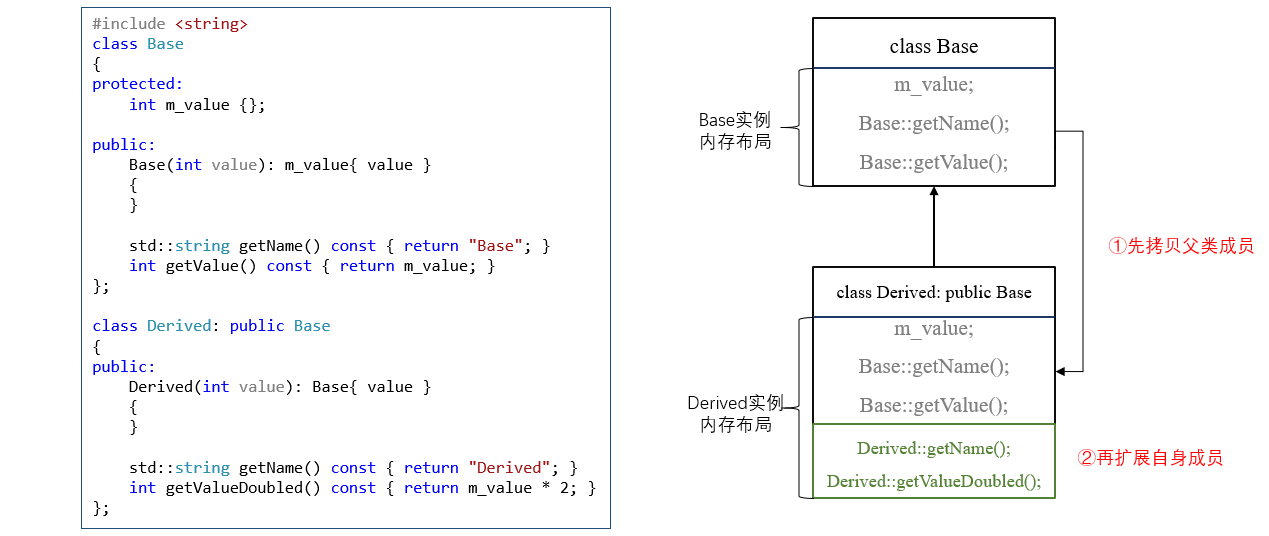
注意,派生类Derived实例化后内存布局:先拷贝基类部分,再扩展了自身部分,所以基类部分在前。
现在有一个很有意思的问题:
理论上,派生类对象是包含基类部分的,那基类指针或引用能指向派生类对象吗?如果能,基类指针能使用派生类扩展部分的成员吗?
答案分别是:能,不能。
1 | int main() |
另一方面,你可能会说这个例子很傻:“当我能使用派生对象时,为什么要使用指向派生对象基类的指针或引用?”
这涉及到多态的“接口重用原则”:不论传递过来的究竟是类的哪个对象,函数都能够通过同一个接口调用到适应各自对象的实现方法。
我们举例说明。
为什么需要基类指针和引用?
假设有多个派生类:Derived、Derived1、Derived2…等都派生于Base。现在外部有一个函数printName要求打印它们的名字:
1 | void printName(Derived* pd) |
但是这个函数只能打印Derived的名字,Derived1等不能打印,因为Derived和Derived1等是不同类型:
1 | Derived d; |
所以,为了Derived1、Derived2…DerivedN,都能被打印,我们不得不再定义N个基本一样的printName函数:
1 | void printName(Derived1* pd) |
这肯定会让你有点无奈,幸运的是,我们知道基类指针(或引用)可以接受派生类对象。于是一切便不用这么麻烦:
1 | void printName(Base* pBase) |
但细心的你也注意到,打印全都是基类的名:即调用的是基类的getName函数,而不是派生类的getName 函数。显然,此时并没有体现类的动态多态性,因为getName函数的链接地址在编译时便确定了,链接的是基类的getName函数地址。
这也就是早绑定,如下图。
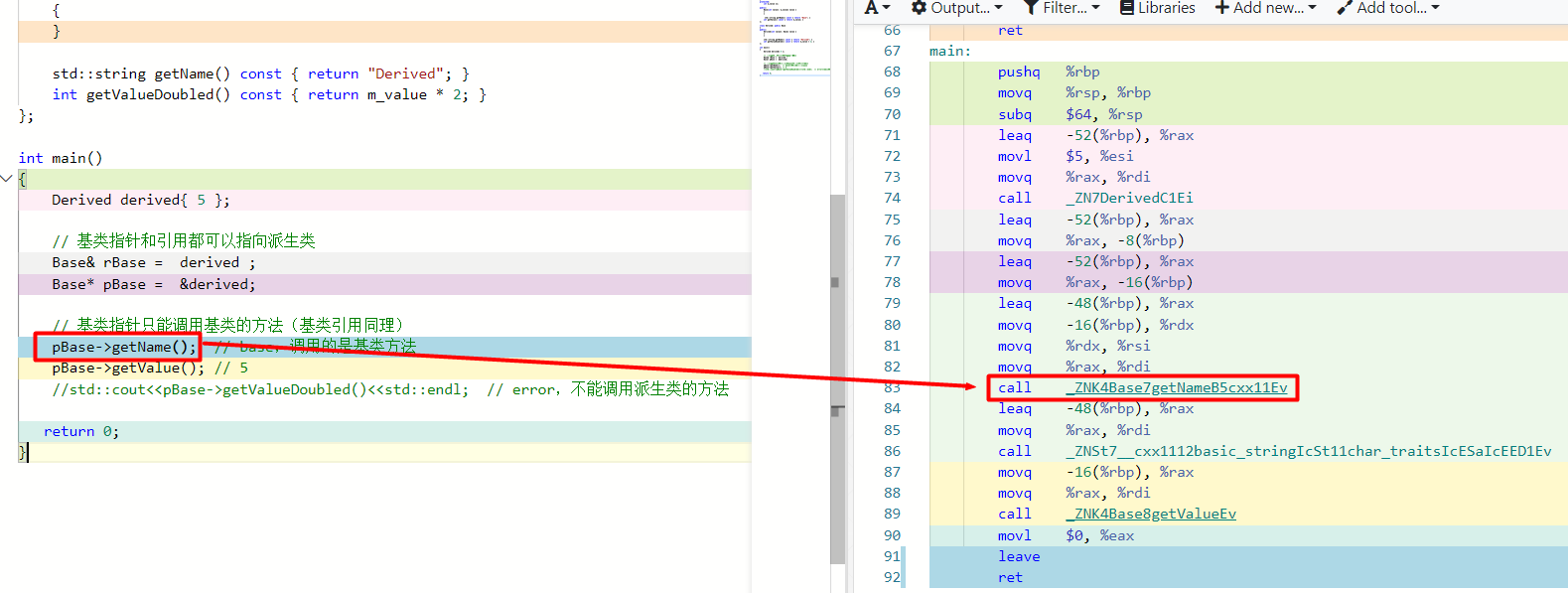
↑可以看到,编译之后,getName 在汇编代码中已被替换为符号: _ZNK4Base7getNameB5cxx11Ev ,对应调用地址为400c02。
但如果getName是虚函数一切开始变得不一样。
如果基类的getName函数被声明为虚函数,其地址便会在运行时绑定为调用的派生类对象的getName函数地址。进而实现下面效果:
1 | printName(d); // ok, 打印:Derived |
我们将从类实例化内存布局变化角度进行剖析。
7.2.2 虚函数和多态
虚函数实现多态
继续前面的例子,我们看看虚函数如何实现多态吧。
为了方便描述,这里只展示了派生类Derived、Derived1,注意派生类的签名、返回类型要和基类完全一致!
1 |
|
类似的:
1 | Base* pBase = &derived; |
和前面非虚函数getName编译器早在编译期绑定了基类函数地址不同,虚函数采用晚绑定(动态绑定):编译器检查到基类的getName函数是虚函数,不会早早绑定函数getName到特定入口地址。
下图说明了这个不同。
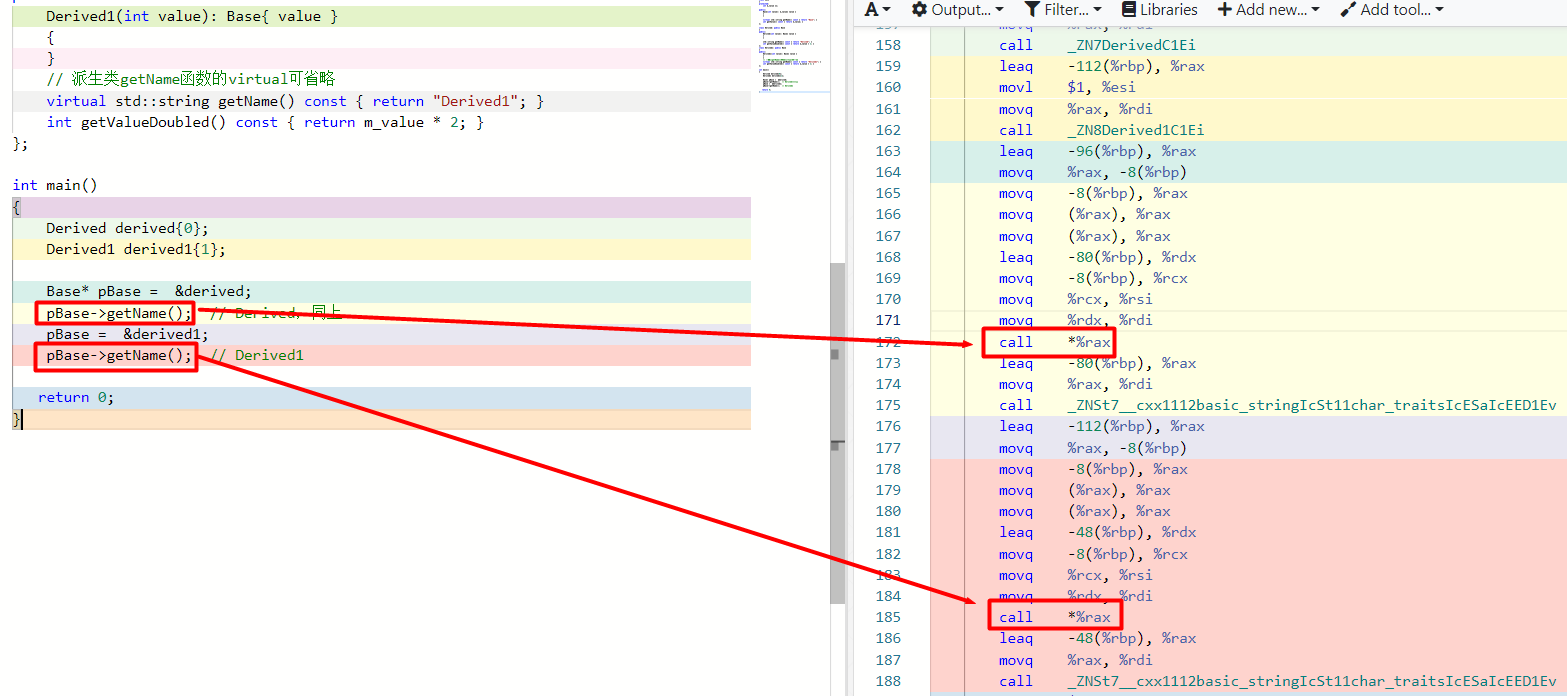
↑此时getName 函数的地址是通过寄存器rax的值确定的,rax 存放的便是派生类的虚表中getName 函数地址,也就是所谓的晚绑定。
早绑定和晚绑定
本节对早绑定和晚绑定进行更全面的总结。
编译程序时,编译器会将 C++ 程序中的每条语句转换为一行或多行机器语言,遇到函数则是转换为一个可用地址。
1 | # 对应代码:add(1,2) |
但在编译期间,我们不一定能确定要调用哪个函数,必须要在运行时才能确定。由此区分出了早绑定和晚绑定:
- 早绑定:在编译器期间就可以直接确定的调用函数,会将其转换为一个调用地址,这就是早绑定;
- 晚绑定:在编译期间不可以直接确定的调用函数,运行期间才转换为具体调用的地址,便是晚绑定。
下面这个例子:我们通过函数指针根据操作符指向相应运算函数,但操作符是在运行期间由用户确定的。
晚绑定一般通过函数指针实现。
1 |
|
注意到,(1)、(2)都是晚绑定。
对于(1),编译器同样无法在编译期间确定,函数指针pFcn1指向的是哪个函数。因为函数指针:
- 需要先读取
pFcn1保存的函数地址 - 才能再跳转到相应函数
显然,“读”这个操作在编译期间是无法完成的,所以pFcn1 无法确定指向哪个函数。
最后,我们再来直观对比下早绑定和晚绑定调用(3)、(4)、(5)时的不同。
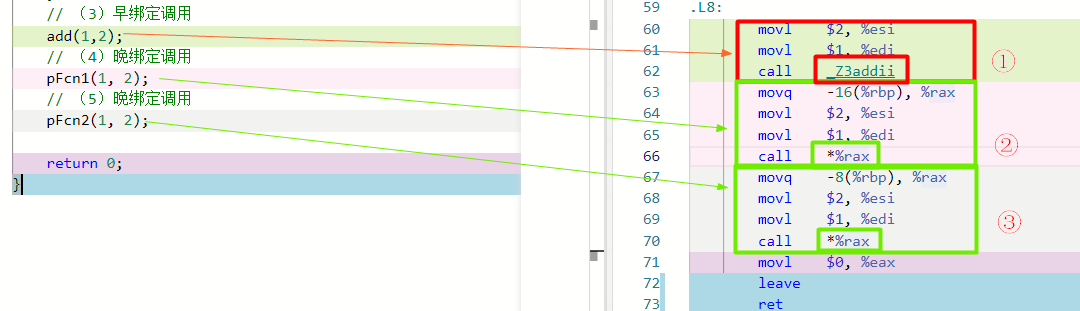
- 早绑定(①处):因为
add(1,2)函数可直接被调用,所以在编译期间就被替换为函数入口地址_Z3addii(0x400877); - 晚绑定(②处):
PFcn1无法被直接调用,先将指针PFcn1保存的函数地址(地址-16(%rbp)中的值,这个值是运行时计算的)存入寄存器rax中,最后才根据寄存器保存的函数地址进行调用。 - 晚绑定(③处):同②。
有了这些概念,我们可以开始探讨虚函数动态绑定实现的过程和原理,这不可避免涉及到虚表。
虚表
为了实现虚函数,C++ 使用了一种特殊形式的后期绑定,称为虚表(vtable)。
每个使用虚函数的类(或派生自使用虚函数的类)都有自己的虚表:
- 虚表是编译器期间设置的静态一维数组,数组每一个条目都是一个函数指针,它指向该类的虚函数;
- 每个类还有个隐藏指针
*__vptr,它可以被继承:- 在创建类实例时,对象的虚表会被创建,
*__vptr会被类构造函数初始化指向该类的虚表(准确来说是在构造函数体进入前初始化的,也就是成员列表中); - 相比
*this指针,*__vptr是一个真正的指针,它使得每个类的对象都增加了一个指针的大小(4字节或8字节)。
- 在创建类实例时,对象的虚表会被创建,
- 虚表和虚表指针是在构造函数中进行创建和初始化的。
看一个简单的例子。
1 | class Base |
根据7.2.1 节我们知道,理论上基类指针dPtr只能“看到”派生类对象d1的基类部分。但这里却成功调用了d1 的成员虚函数function1 。
下图类实例布局形象地说明了原因:
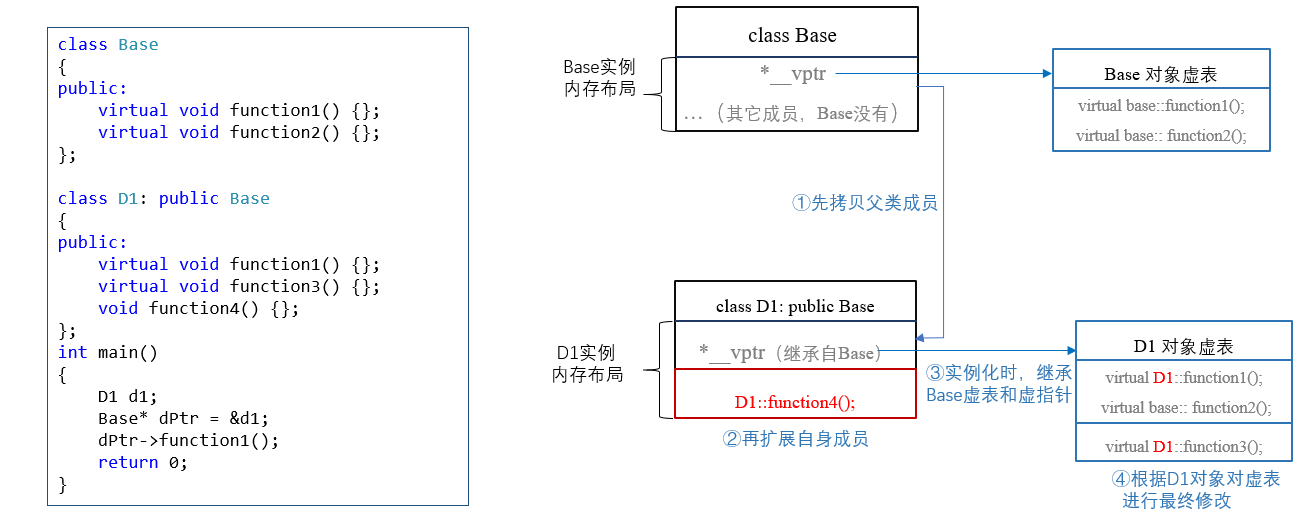
- 创建派生类D1的实例
d1时,先构造了基类Base对象部分,然后用基类构造函数进行初始化,这个过程设置了基类对象的虚指针和虚表; - 然后构造派生类扩展部分,派生类构造函数进行初始化:
- 原来继承的基类虚表,修改
base::function1→ 为Derived::function1; - 增加派生类自己的虚函数
Derived::function3; - 完成其它初始化工作。
- 原来继承的基类虚表,修改
- 实例
d1构建完成(内存布局如上图)。
现在我们再来解释下面这行代码发生了什么:
1 | dPtr->function1(); |
- 编译器识别出
function1是虚函数,开始分析此时调用对象,来确定使用哪个类对象的虚指针,进而确定虚表来找到相应虚函数指针地址; - 指针
dPtr比较特殊,它是基类的指针(引用同理),但指向的是派生类对象d1——这种情况,是根据指向派生类对象确定; - 所以,最终根据
dPtr->d1.*__vptr来查找对象d1的虚表(上图的D1对象虚表),从而调用了D1::function1。
调用function2类似:
1 | dPtr->function2(); |
- 编译器识别出
function2是虚函数 ,同时确定了当前调用对象是d1; - 根据
d1虚指针查找d1的虚表,进而找到function2函数指针,不过这个指针保存的是Base虚表的function2函数地址; - 最终调用了
Base::function2。
从汇编角度来验证上述过程(精简了些代码,不影响阅读):
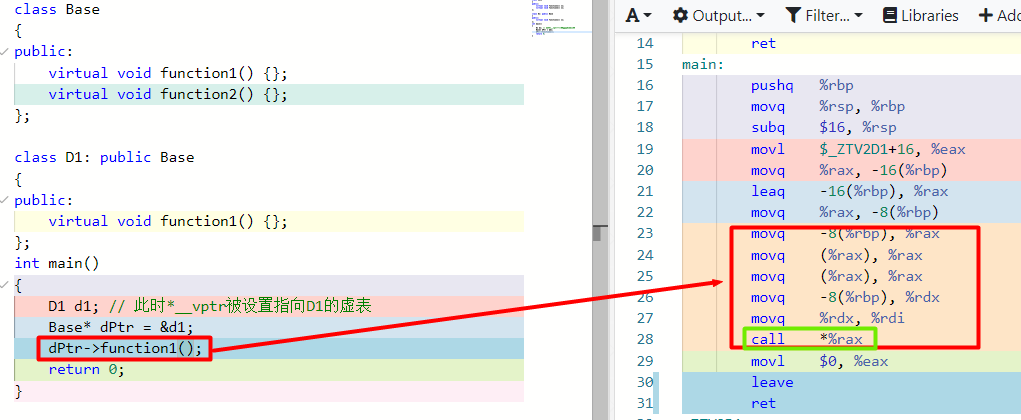
注意右侧红框处的汇编代码:1.确定对象类型→2.根据虚指针找到虚表→3.根据虚表和偏移计算虚函数指针地址→4.根据虚函数指针获取虚函数调用地址→5.调用函数。
1 | # 1.-8(%rbp)是堆上d1内存首地址,存入寄存器rax中 |
虚函数性能问题
迄今为止,我们介绍了三种函数调用方式:
- 早绑定方式:直接调用;
- 晚绑定方式:函数指针与虚函数。
其中,直接调用方式只需1次就可以找到调用的函数;函数指针需要两次:读取函数指针保存的函数地址→调用函数;而虚函数需要三次:读取虚指针*__vptr 找到虚表→读取虚表中要调用的虚函数指针保存的函数地址→调用函数。
显然这带来了额外的时间开销。
另外,任何使用虚函数的类对象都有一个 虚指针*__vptr ,所以创建对象也需要多余内存存储该指针,这还带来额外空间开销。
所以,虚函数虽好但不要过度哦。
7.2.3 虚函数二三事
override、final及协变类型
本节我们将主要介绍override、final及协变返回类型:
- override:在派生类函数标记该函数重写了基类的虚函数,以避免重写时派生类函数的返回类型、函数签名和基类虚函数不一致的书写错误;
- final:显式标记某个函数不希望不重写,如果被重写编译器会报错;
- 协变返回类型:基类函数返回类型是基类的指针(或引用),派生类返回重写函数的返回类型可以是派生类的指针(或引用),此时依旧视为重写。
先从override说起。
我们知道,派生类虚函数只有在其签名和返回类型完全匹配时才被视为重写。
一不留神可能就会出错:
1 |
|
所以,为了能让编译器帮我们自动检查,我们可以考虑在派生类B中,使用override关键字。
1 | class B : public A |
此时程序产生了编译错误。
使用override说明符没有产生性能损失,所以在派生类中的重写函数请尽量使用override说明符。
final说明符比较简单仅仅希望某个函数不会被重写。
和override说明符在同一位置使用(函数体前),二者也可以同时存在。
1 |
|
final也可以修饰类表示无法继承。
1 | class test final // 其它类无法继承test |
最后是协变返回类型。
如果基类返回类型是基类的指针或引用,那么派生类重写函数的返回类型可以是派生类的引用或指针。此时依旧视为重写。
不过,下面这个例子藏了点玄机。
1 |
|
输出:
1 | 调用 Derived::getThis() |
结果分析:
-
b->getThis(),因为getThis是虚函数,所以getThis在运行时才会被确定,b是d的指针,查找对象d虚表最终调用输出:1
调用 Derived::getThis()
-
b->getThis()虽然返回了Derived*,但因为C++是静态语言,而printType又未声明为虚函数,所以printType调用对象类型其实在编译时就已经确定为Base。所以最终
Derived*只能向上转型为Base*,调用Base::printType输出:1
Base
析构、构造函数与虚函数
析构、构造函数与虚函数之间需记住以下两点:
- 不要在构造函数或析构函数中调用虚函数;
- 析构函数可声明为虚函数,构造函数不能声明为虚函数。
我们先来讨论第一点:不要从构造函数或析构函数调用虚函数。
要解释这一点,我们需要回忆两个知识点:
- 每个类对象虚指针指向当前类虚表,虚指针根据当前调用的对象确定;
- 创建派生类对象时,先调用基类部分构造函数,再调用派生类构造函数;销毁派生类对象时,析构函数执行顺序和构造函数恰相反。
设想下,我们从基类的构造函数调用虚函数会发生什么?
- 创建派生类对象,开始调用基类构造函数;
- 进入基类构造函数调用虚函数,即:this->虚函数(),当前this对象是基类对象而不是派生类对象 ,所以最终使用的是基类对象虚指针,在基类的虚表中调用了基类的虚函数版本而不是派生类中的;
- 最后再调用派生类构造函数。
类似的错误存在析构函数中:
- 销毁对象,开始调用派生类析构函数;
- 派生类部分被销毁,接着调用基类析构函数;
- 进入基类析构函数调用虚函数,同样的,此时对象是基类对象而不是派生类对象,所以虚函数始终解析为该函数的基类版本。
我们再来讨论第二点:析构函数可声明为虚函数,构造函数不能声明为虚函数。
析构函数声明为虚函数,特别是明确要作为基类中的析构函数,可以避免派生类内存没有被释放产生内存泄漏。这样释放基类内存时,会执行派生类析构函数,而派生类析构函数执行后还会调用基类析构函数,确保了内存被析构完全。
下面这个例子帮助理解:
注意,基类指针base 指向了new动态分配在堆上的派生类对象内存,所以只能我们显式delete管理堆内存释放。
1 |
|
最终输出:
1 | 调用 ~Base() |
因为base指向的是堆上的派生类对象,所以这个对象离开作用域也不会自动释放,只能我们使用delete显式删除。
但此时只有基类部分执行了析构函数,派生类析构函数没有执行,导致m_array 持有的内存发生泄漏。
为了解决这个问题,需要将基类的析构函数声明为虚函数。修改如下:
1 | virtual ~Base() // 虚函数 |
再次执行输出:
1 | 调用 ~Derived() |
这样,派生类的析构函数执行完还会执行基类的析构函数(反之不行)。
不过,构造函数不能声明为虚函数。
很好理解,因为这破坏了构造函数执行顺序:先基类构造函数→再派生类构造函数。
当基类构造被声明为虚函数时:先派生类构造函数ok,但基类构造函数永远等不到执行,派生类构造函数并没有义务调用基类构造函数。
综上所述:
- 永远不要从构造函数或析构函数调用虚函数;
- 当前类如果打算作为基类,请将析构函数声明为virtual(如果不打算作为基类,析构函数不用声明为virtual,但类最好标记为final);
- 永远不要把构造函数声明为virtual。
纯虚函数、抽象基类与接口类
迄今为止,我们编写的虚函数都有函数体。C++允许我们创建一种特殊的函数,纯虚函数,它没有实体由派生类实现具体定义。
由此还引申出其它几个概念:
- 抽象基类:具有纯虚函数的类便是抽象基类;
- 接口类:没有成员变量,只有纯虚函数的类。
要创建一个纯虚函数,只需为函数赋值0即可。
1 |
|
这里我们声明了一个Animal 只作为基类,因此:
Animal构造函数被声明为protected,避免其被外部被实例化;但是不要声明为private,否则派生类无法实例化。- 内部我们声明了纯虚函数
speak(),因为我们只希望它在派生类中被实现,基类实现没有意义。
此时Animal 因为包含纯虚函数,所以也被称为抽象基类。抽象基类不能被实例化,所以这里的Animal 构造函数,直接声明public也可以:
1 |
|
纯虚函数还有几个特质:
-
纯虚函数必须被派生类实现(重写);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Cow: public Animal
{
public:
Cow()
{
}
// const char* speak() const override { return "咪"; }
};
int main()
{
Cow cow{};
std::cout << cow.speak() << '\n'; // error,派生类Cow没有实现纯虚函数speak()
return 0;
} -
纯虚函数可以有函数体,不过只能在类外实现(不常用)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class Animal
{
protected: // 保护成员
Animal()
{
}
public:
// 纯虚函数,=0
virtual const char* speak() const = 0;
// 默认构造函数
virtual ~Animal() = default;
};
const char* Animal::speak() const // 只能类外实现
{
return "???"; // "???"是字符串常量,在常量区
}
最后值得一提的是,抽象类仍然具有虚表。
虚基类
7.1.4节中多重继承导致的“菱形问题”,我们最终解决方案是通过虚继承解决:
此时A被称为虚基类。
-
虚基类对象,在继承树中被所有对象共享,也就是只会构造一次;
-
派生虚基类最多的类,负责创建虚基类;
在上图中,B、C都只派生了一次虚基类A,而D派生了两次,所以由D负责构建虚基类A(调用虚基类的构造函数一次)。
7.2.4 动态转换与对象切片
上行转换和下行转换
基本概念:
- 上行转换:派生类指针或引用转换为→基类指针或引用,C++可以隐式地进行,这种转换是安全的;
- 下行转换:基类指针或引用转换为→派生类指针或引用 ,这种转换是不安全的,最好通过dynamic_cast 或 static_cast 显式完成。
下行转换既然是不安全的,为什么还要存在?
我们经常会有这种需求:虽然只有基类指针,但还是想根据基类指针访问派生类相关的信息。
在这之前,我们已经有了解决方案:在基类声明和派生类函数一致的虚函数。但虚函数并非万灵药,因为:
- 这给基类带来了额外的负担,不得不在基类重复声明了一个虚函数。
考虑下面这个例子,说明了上述问题。
使用基类指针访问派生类getName方法。
1 |
|
虽然最终成功访问到派生类的getName方法,但是不得不在基类额外定义一个虚函数:即使它对基类是毫无作用的。
另一方面,考察这行代码:
1 | Base* b{ getObject(true) }; |
getObject(true)返回的是Derived类型指针;- 然后上行转换为Base指针,。
也就是说Base指针b 保存了Derived对象的内存地址,只不过只能访问基类部分。但也天生具备了访问Derived对象的“潜质”,Derived对象的其它部分依旧存在。
我们可以利用dynamic_cast强制转换发掘这种潜力:
1 | // 此时基类的虚函数getName已被删除 |
输出:
1 | Derived |
最后强调一下dynamic_cast 失败时的处理:
- dynamic_cast失败返回NULL(如果是引用,返回
std::bad_cast异常),(最佳实践)请编码时务必进行判断,确保你的下行转换成功; - static_cast 失败也不返回NULL,因此不建议使用static_cast,它过于粗暴不够安全。
下行转换还是虚函数?
一般来说,使用虚函数应该优于向下转换。但是,有时向下转换是更好的选择:
- 当不能修改基类添加虚函数时(例如,基类是标准库的一部分);
- 当需要访问特定于派生类的东西时(例如,仅存在于派生类中的函数);
- 向基类添加虚函数没有意义时(例如,基类函数体没有实现的必要)。
不过能使用下行转换是建立在:你使用的基类指针或引用是否具有转换下行转换的潜质——指向的是派生类对象?
如果不具有的话,比如指向的是一个基类对象,强行转换会出错。
1 | int main() |
输出:
1 | [root@roy-cpp test]# ./test.out |
对象切片
在此之前,我们都是利用基类的指针或引用 指向了一个派生类对象,大概类似下面这样:
1 | int main() |
上面的ref、ptr 虽然只能“看到”derived的Base部分,但derived其它部分依旧是存在的。
如果不用指针或引用指向呢?就像这样:
1 | int main() |
上面base 复制了Derived 对象的 Base 部分,而 Derived 对象其它部分已被丢弃,不再存在 ,这就是对象切片。
对象切片很容易导致一些意料之外的问题,比如函数参数值传递时。
假设此时Base有一个虚函数getName,它的作用是打印出“Base”;派生类getName进行了重写,不过它打印的是“Derived”。
函数printName接受一个Base类型参数,是值传递方式,它主要任务是调用getName函数。
1 | void printName(const Base base) // 不是引用或指针传递 |
输出:
1 | Base |
因为发生了对象切片,即使getName是虚函数也不会调用Derived::getName,而是调用基类版本Base::getName(这也是为什么我们建议函数的类类型参数尽量声明为引用或指针)。
最后,我们再举一个例子来说明对象切片带来编码问题:使用vector实现多态时,发生了对象切片。
1 |
|
输出:
1 | Base |
与前面的示例类似,因为 std::vector 被声明为 Base 类型的向量,所以当将 d添加到向量时,d被切片了。
-
而且,尝试使用引用传参也不起作用:
1
std::vector<Base&> v{};
会发生编译错误,因为
std::vector的元素必须是可分配的,而引用不能重新分配(仅能初始化)。 -
最终解决方案是声明为指针传参:
1
2
3
4std::vector<Base*> v{};
v.push_back(&b);
v.push_back(&d);重新编译,输出正常:
1
2Base
Derived
综上所述:尽管 C++ 支持通过对象切片将派生对象分配给基类对象,但这是个让人感到头疼的行为。
- 所以,请尽量避免使用切片;
- 确保函数参数是引用(或指针)。
下章我们开始介绍模板相关知识。
更新记录
- 第一次更新
参考资料
- 1.What is the difference between "IS -A" relationship and "HAS-A" relationship in Java? ↩
- 2.【C++基础之二十一】菱形继承和虚继承:https://blog.csdn.net/jackystudio/article/details/17877219 ↩
- 3.多重继承的优缺点:https://blog.csdn.net/woodforestbao/article/details/4500406 ↩
- 4.C++ 多态 :https://zhuanlan.zhihu.com/p/37340242 ↩
- 5.C++基类的析构函数为何要声明为虚函数 :https://zhuanlan.zhihu.com/p/148290103 ↩
- 6.C++类对象的内存结构 :https://blog.csdn.net/MOU_IT/article/details/89045103 ↩
 微信
微信 支付宝
支付宝


