
C++从零开始(十二):Linux系统编程入门
🌟《C++从零开始》 系列,毕业论文初稿写完三个月过去,终于又开始更新了…🥗

Linux系统编程作为《C++从零开始》三部曲之一,自有其极其重要的地位。
如果将Linux比作为一台性能出众的跑车,我们一定不会只满足于驾驶它上下班,只会挂挡、踩油门和控制方向之类的基本操作。我们想要更加了解它,挖掘更多的潜能。
学习系统编程便是让你做到这一点。
Linux系统内容纷繁复杂,在学习过程中《Linux系统编程手册》使我受益良多。在本部曲中,我将尽量用简洁的语言进行总结和扩展。
好了,轻松一点,让我们先从Linux的前身——UNIX历史说起吧。
UNIX历史
UNIX和C简史
- 1969年,bell实验室(隶属AT&T电话公司),Ken Thompson,开发出了首个 UNIX 系统。
- UNIX 是MULTICS(多信息及计算服务,Multiplexed Information and Computing Service)一词的双关语。
- 1970年,AT&T 的工程师,在Digital PDP-11 小型机以汇编语言重写了UNIX。
- 1971年,Thompson 在 bell 实验室的同事,Dennis Ritchie设计实现了C语言。
- C 语言由于其高效、灵活、功能丰富、表达力强和较好的可移植性等特点,迅速风靡起来。
- 1973 年,UNIX 已经被移植到了 PDP-11 小型机上,并以 C 语言对UNIX进行了重写。
- 1977年,因为法律禁止 AT&T销售 UNIX,AT&T公司允许高校使用UNIX,极大促进了UNIX的发展。第七版 UNIX 发布的重要意义还在于,从该版本起,UNIX 分裂为了两大分支:BSD 和 System V。
- 1979年,伯克利发布首个完整的,属于自己 UNIX 发布版 3BSD(伯克利软件发布,Berkeley Software Distribution)诞生。
- 在此期间,随着 AT&T 不再对电信市场形成垄断,该公司被获准销售 UNIX。这也就催生出了另一种 UNIX 的变种—System V,日后,它也成为了某些商业 UNIX 实现的基石。
- 1983 年,加州大学伯克利分校的计算机系统研究组(Computer Systems Research Group)发布了 4.2BSD。
- 该版本的发布意义深远,因为其包含了完整的 TCP/IP 实现,其中包括套接字应用编程接口(API)以及各种网络工具。
Linux简史
在当时UNIX时代,计算机软件的消费者不但无权阅读自己所购软件的源码,而且还不能复制、更改及重新发行所购软件。Stallman认为,这只会造成程序员之间勾心斗角、敝帚自珍的局面,无法实现工作协同和成果共享。
- 1984年,MIT 的程序员Richard Stallman,发起了 GNU 项目(“GNU’s not UNIX”的递归缩写形式)。
- GNU 项目由此制定了 GNU GPL协议:以 GPL 许可协议发布的软件不但必须开放源码,而且应能在 GPL 条款的约束下自由对其进行重新发布。可以不受限制的修改以 GPL 许可协议发布的软件,但任何经修改后发布的软件仍需遵守 GPL 条款;
- GNU 项目还开发出了Emacs 文本编辑器、GCC、bash shell 以及 glibc(GNU C 语言库),只要再拥有一个能够有效运作的内核,就能使 GNU 项目开发出的UNIX 系统“功德圆满”。
- 1991 年,Linus Torvalds,开发出UNIX内核“雏形”,可以编译并运行各种 GNU 程序。
- 为了传承 UNIX 历史悠久的光荣传统,总以字母“X”结尾,人们最终将这一内核命名为 Linux。
应 Torvalds 之邀,许多其他程序员也加入到了改进内核的行列中。随着时光的流逝,在一干程序员的不懈努力下,Linux 逐渐发展壮大,并被移植到了多种硬件架构之上。
标准化过程
20 世纪 80 年代末,UNIX 和 C 语言的实现“百花齐放”,所引发的可移植性问题迫使人们开展针对以上两者的标准化工作。
C 语言和 UNIX 系统的标准化进程也显得愈发重要。
C标准
C 语言标准独立于任何操作系统,换言之,C 语言并不依附于 UNIX 系统。
- 1989 年,美国国家标准委员会ANSI的C 语言标准(C89标准)获批。
- 这份标准在定义 C 语言语法和语义的同时,还对标准 C 语言库操作进行了描述,这包括 stdio 函数、字符串处理函数、数学函数、各种头文件等等。
- 随之于 1990 年,C89标准被国际标准化组织ISO采纳;
- 1999年,ISO 对 C 语言标准的修订版,C99标准正式被批准。
- 对 C 语言及其标准库的一系列修改,诸如,增加了 long long 和布尔数据类型、C++风格的注释(//)、受限指针以及可变长数组等。
操作系统接口
- 1989年,操作系统标准化的“第一次吃螃蟹”便催生出了 POSIX.1。
- 术语“POSIX(可移植操作系统 Portable Operating System Interface 的缩写)”;
- 符合 POSIX.1 标准的操作系统应向程序提供调用各项服务的 API,POSIX.1 文档对此作了规范。凡是提供了上述 API 的操作系统都可被认定为符合 POSIX.1 标准。
- 1988 年和 1990 年,IEEE 和 ISO 先后将 POSIX.1 采纳为标准。
- 2001 年,POSIX 1003.1-2001 标准颁布,取代了 SUSv2、POSIX.1、POSIX.2 以及大批的早期 POSIX 标准。
- 2008 年,人们继续完成对POSIX标准和 SUS 规范的修订,于是,合二为一的
POSIX 1003.1-2008 和 SUSv4 标准浮出水面。
对Linux发展历史有了简单了解后,我们再来了解Linux系统编程的一些基本概念吧。
一、基本概念
在本章中,主要将介绍Linux&系统编程的基本概念,以期更好地理解后续章节。
1.1 Linux基本概念
1.1.1 操作系统与内核
操场系统与内核表现为包含关系。
- 操作系统,指完整的软件包,这包括用来管理计算机资源(即CPU、RAM和设备)的核心层软件,以及附带的所有标准软件工具,诸如命令行解释器、图形用户界面、文本编辑器等;
- 内核,则特指管理资源的核心层软件。
内核有什么用?
内核所提供的核心层软件,一般执行以下主要任务:
-
进程调度,即用于控制进程对CPU使用。
CPU在一时间段只能执行一个任务,而Linux属于抢占式多任务操作系统,这意味着多个进程(一个运行中的程序我们称之为“进程”)可同时驻留在内存。分配CPU何时给哪些进程使用,以及每个进程能使用多长时间,都需要内核进行进程调度。
-
进程通信,用于多进程之间进行通信。
-
内存管理,而物理内存(RAM)仍然属于有限资源,内核必须以公平、高效地方式在进程间共享这一资源。
Linux通常采用虚拟内存管理机制,它有以下好处:
- 内存隔离,进程与进程之间&进程与内核之间隔离。因此一个进程无法读取其它进程或内核的内容。
- 只需将进程一部分保存在内存中。不但降低了每个进程对内存的需求量,而且还能在 RAM 中同时加载更多的进程
-
文件系统,内核在磁盘之上提供了文件系统。
-
IO设备访问,如键盘、打印机等。
-
网络连接,内核以用户进程的名义收发网络消息(数据包)。
-
提供系统调用应用编程接口(API):进程可利用内核入口点(也称为系统调用)请求内核去执行各种任务。
以上内容每一部分都将后续扩展开来分析探讨。
内核态和用户态
CPU 可在用户态和核心态两种不同状态运行,对应地将虚拟内存区域划分(标记)为用户空间部分或内核空间部分。
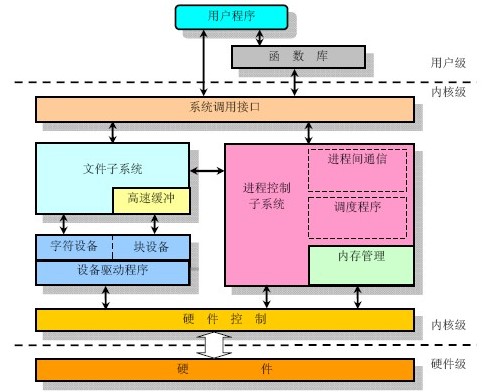
- 用户态,CPU 只能访问被标记为用户空间的内存,无法执行不利于系统运行的操作。
- 核心态,CPU 既能访问用户空间内存,也能访问内核空间内存,也能执行一些核心操作如:执行宕机(halt)指令去关闭系统,访问内存管理硬件等。
这样做保证了系统的安全和效率。
1.1.2 shell
shell 也称之为命令解释器,主要用于读取用户输入的命令,并执行相应的程序以响应命令。
纵观 UNIX 历史,出现过以下几种重要的 shell(按时间顺序):
- Bourne shell (sh),历史最为悠久,由Steve Boume编写。Bourne shell 包含了在其他 shell 中常见的许多特性,I/O 重定向、管道、文件名生成(通配符)、变量、环境变量处理、命令替换、后台命令执行等。
- C shell(csh),由 Bill Joy编写而成,控制语法与C语言有很多相似之处而因此得名。C shell 与 Bourne shell 并不兼容,且包含一些极为实用的特性,如命令历史记录,命令编辑等。
- Korn shell(ksh),由David Korn 编写,不但兼容了sh还吸收了csh相关特性。
- Bourne again shell(bash),这款 shell 是 GNU 项目对 Bourne shell 的重新实现,提供了与 C shell 和 Korn shel 所类似的交互式特性。
不过,设计 shell 的目的不仅仅是用于人机交互,对 shell 脚本(包含 shell 命令的文本文件)进行解释也是其用途之一。为实现这一目的,每款 shell 都内置有许多通常与编程语言相关的功能,其中包括变量、循环和条件语句、I/O 命令以及函数等。
1.1.3 用户和组
系统会对每个用户的身份做唯一标识,用户可隶属于多个组。
用户
系统的每个用户都拥有唯一的登录名(用户名)和与之相对应的整数型用户ID(UID)。
在系统文件/etc/passwd 显示了更具体的信息。
1 | [root@roy-cpp cpp-learn]# cat /etc/passwd |
以上7个字段分别对应:用户名:口令:用户标识号:组标识号:注释性描述:主目录:登录Shell 。下面对其中部分字段进行解释:
-
口令,一些系统中,存放着加密后的用户口令字,但这存在安全隐患。因此,在Linux使用了shadow技术,使用
x或*进行替代,而把真正的加密后的用户口令字存放到/etc/shadow文件中。 -
用户标志号,即UID,为一个整数,范围为0~65535。0是超级用户root的标识号,1-99由系统保留,作为管理账号,普通用户的标识号从100开始。
-
组标志号,即GID,记录用户所属的用户组,对应着/etc/group文件中的一条记录。
-
注释性描述,记录着用户的一些个人情况,但并没有什么实际的用途。
-
主目录,用户在登录到系统之后所处的目录,各用户对自己的主目录有完整的读(r)、写(w)、执行(x)权限。
-
登陆shell,用户登录到系统后运行的命令解释器,即shell。
在/etc/passwd我们也注意到,除了我们熟知的root账户,还有一些其它系统账户:bin(拥有可执行的用户命令文件)、sys(拥有系统文件)、adm(拥有帐户文件)。
组
出于管理目的,比如为了控制对文件和其他资源的访问,将多个用户分组是非常实用的做法。
每个用户组都对应着系统组文件/etc/group 中的一行记录:
1 | [root@roy-cpp cpp-learn]# cat /etc/group |
以上4个字段分别对应, 组名:口令:组标识号:组内用户列表。
- 其中组内用户列表,是属于这个组的所有用户的列表,不同用户之间用逗号
,分隔。
1.1.4 目录与文件
目录
Linux目录具有以下特点:
-
单根目录结构,Linux内核维护一套单根目录结构,存放系统所有文件。这和我们熟知Windows系统不同,它的每个磁盘(如C盘)都有各自的目录层级。
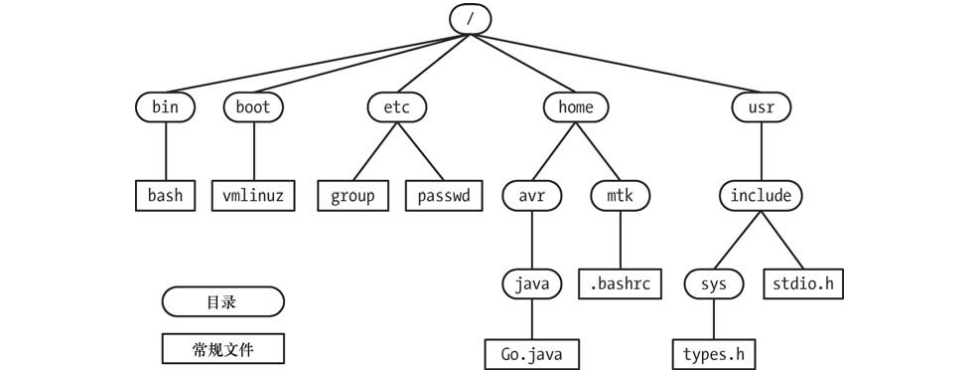
-
绝对路径与相对路径。
- 绝对路径以
/开始,如上图中/etc/passwd; - 相对路径不以
/开始,如上图中,在usr目录下,include/sys/types.h、../home/mtk/.bashrc分别可引用文件types.h和.bashrc。
- 绝对路径以
文件
Linux文件主要值得关注以下三点:
-
文件类型,在Linux文件系统内,“一切皆为文件”。这意味着文件类型不仅包含普通文本文件,还包含:设备、管道、套接字、目录、符号链接等。
-
文件名,文件名最长可达 255 个字符。文件名可以包含除
/和空
字符(\0)外的所有字符。此外,还应避免以连字符
-作为文件名的起始字符,因为一旦在 shell 命令中使用这种文件名,会被误认为命令行选项开关。 -
文件IO模型,UNIX 系统 I/O 模型最为显著的特性之一是其 I/O 通用性概念。
也就是说,同一套系统调用(open()、read()、write()、close()等)所执行的 I/O 操作,可施之于所有文件类型,包括设备文件。
另外,值得注意的是,UNIX系统本质只提供字节流文件,因此没有“文件结束符”的概念。UNIX系统read()如何判断文件结束?读取文件时如无数据返回,便会认定抵达文件末尾。
1.1.5 进程
进程是正在执行的程序实例。
执行程序时,内核会将程序代码载入虚拟内存,为程序变量分配空间,建立内核记账(bookkeeping)数据结构,以记录与进程有关的各种信息(比如,进程 ID、用户 ID、组 ID 以及终止状态等)。
进程内存布局
下图展示了一个虚拟进程(程序)内存空间运行时分布布局。高地址的1GB(Windows默认2GB)空间分配给内核,也称为内核空间;剩下的3GB分给用户,也称用户空间(程序使用的)。
一个进程本质是由代码段、数据段、堆、栈四部分组成的 。
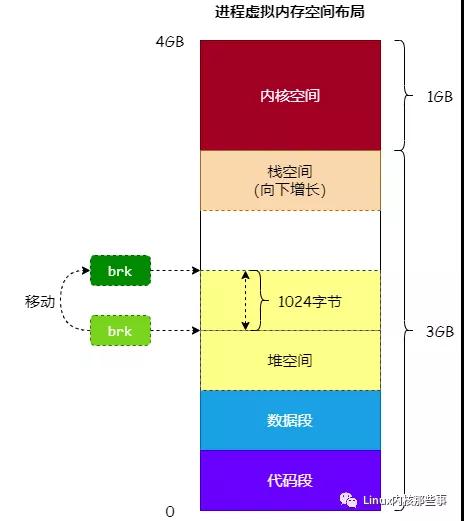
作为程序员,我们更关注的是用户空间中的内容,也就是:
-
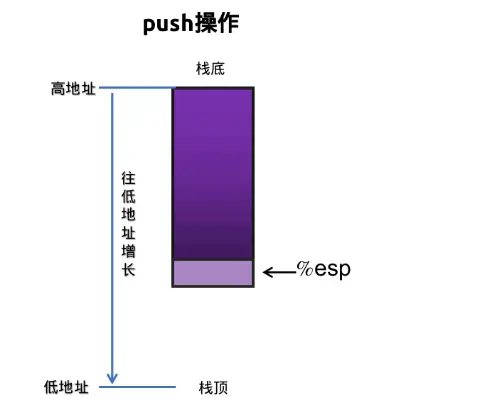
栈(Stack):存储代码中调用函数、定义局部变量(但不包含static修饰的变量)、保存的上下文等;
-
特点:存放的数据从栈顶(低地址)压入,也是从栈顶(低地址)弹出,所以有人说栈是向下生长的。函数退出时,所有数据会自动释放内存(出栈)。
-
-
文件映射区域 : 栈和堆中间那个空白区域。动态库、共享内存等映射物理空间的内存,一般是
mmap函数所分配的虚拟地址空间。 -
堆(Heap):存储那些生存期与函数调用无关的数据,如动态分配的内存。堆(动态)分配的接口通常有malloc()、calloc()、realloc()、new等。
- 特点:相对于栈,堆是向上生长的;堆空间需要主动释放,否则会依然存在。
-
数据段(.data):保存全局变量、常量、静态变量的内容的一块内存区域。
-
代码段(.text & .init):
.text用于存放整个程序中的代码,.init用于存放系统中用来初始化启动你的程序的一段代码 。
进程创建、执行及终止
-
进程创建调用fork()函数,新创建进程被称为子进程。正如“fork”所暗示的,
- 子进程会复制父进程数据段、堆、栈等的副本并可以进行修改;
- 代码段在内存被标记为只读,则由父、子进程共享。
-
进程执行往往指的是,1)执行父进程共享代码其它函数,或2)调用execve()去加载执行全新程序。
- execve()会销毁所有代码段、数据段及堆栈内容,并根据新段创建新段进行替换;
- 以execve()为基础,C语言库提供以“exec”打头的相关函数。
-
进程终止往往可通过,1)调用_exit()函数,或2)向进程传递信号杀死。
根据惯例,终止状态为 0 表示进程“功成身退”,非 0 则表示有错误发生。
特殊进程
init进程
系统引导时,内核会创建一个名为 init 的特殊进程,其主要任务是创建并监控系统运行所需的一系列进程。
- 1生万物,init 进程的进程号总为 1,且总是以超级用户权限运行,系统的所有进程不是由 init(使用 frok())“亲自”创建,就是由其后代进程创建。
- 与日同辉,谁(哪怕是超级用户)都不能“杀死”init 进程,只有关闭系统才能终止该进程。
守护进程
守护进程指的是具有特殊用途的进程,系统创建和处理此类进程的方式与其他进程相同,但以下特征是其所独有的:
- 长生不老,守护进程通常在系统引导时启动,直至系统关闭前,会一直“健在”。
- 后台运行,且无控制终端供其读取或写入数据。
守护进程中的例子有 syslogd(在系统日志中记录消息)和 httpd(利用 HTTP 分发 Web 页面)。
环境列表
每个进程都有一份环境列表,即在进程用户空间内存中维护的一组环境变量。这份列表的每一元素都由一个名称及其相关值组成。
由 fork()创建的新进程,也会继承父进程的环境副本。
在大多数shell中,我们使用export命令进行创建环境变量:
1 | [root@roy-cpp cpp-learn]# export myval='hello unix' |
我们还可以打印已预定义的环境变量:
- PATH,用户输入命令后,shell搜索的目录列表;
- HOME,用户登陆目录的路径名。
1 | [root@roy-cpp cpp-learn]# echo $PATH |
这些预定义的变量也很好地可以直接被shell脚本和程序进行访问。
进程通信
Linux 系统上运行有多个进程,有些进程必须相互合作以达成预期目的,因此彼此间需要通信和同步机制。
- 读写磁盘文件中的信息,来进程间通信是一种容易被接受且简单可行的办法。
但这种方法既慢又缺乏灵活性。因此,像所有现代 UNIX 实现那样,Linux 也提供了丰富的进程间通信(IPC)机制,如下所示。
- 信号(signal),用来表示事件的发生。
- 管道(亦即 shell 用户所熟悉的“|”操作符)和 FIFO,用于在进程间传递数据。
- 套接字,供同一台主机或是联网的不同主机上所运行的进程之间传递数据。
- 消息队列,用于在进程间交换消息(数据包)。
- 信号量(semaphore),用来同步进程动作。
- 共享内存,允许两个及两个以上进程共享一块内存。当某进程改变了共享内存的内容时,其他所有进程会立即了解到这一变化。
1.1.6 内存映射
内存映射(Memory-mapped,mmap),即将一个文件或者其他对象映射到进程的地址空间,实现文件磁盘地址和应用程序进程虚拟地址空间中一段虚拟地址的映射关系。
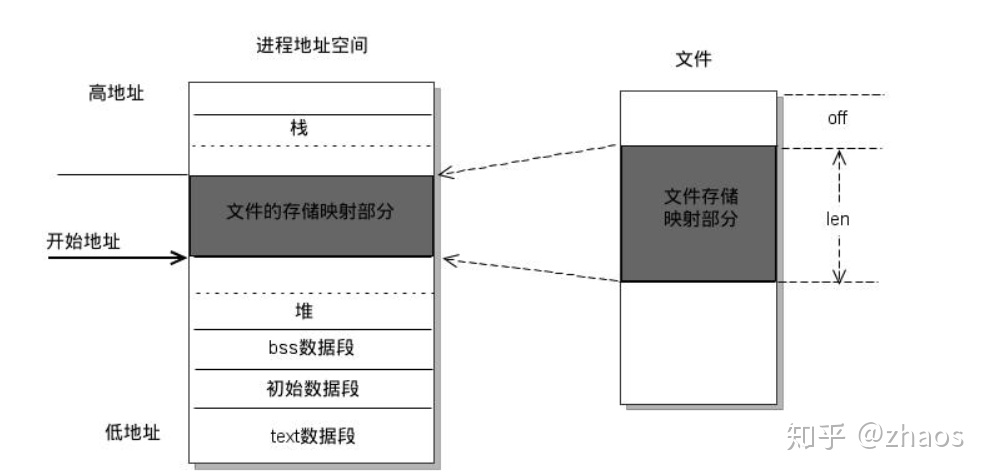
特别的,由某一进程所映射的内存可以与其他进程的映射共享。
有两种方式可以做到这一点:
- 两个进程都针对某一文件的相同部分加以映射;
- 由 fork()创建的子进程自父进程处继承映射。
但这也由此引发了一个问题:某个进程对共享页面内容的改动一定会为其他进程所见吗?
其实这取决于创建映射时所传入的标志参数。
- 若传入标志为私有,则某进程对映射内容的修改对于其他进程是不可见的,而且这些改动也不会真地落实到文件上;
- 若传入标志为共享,对映射内容的修改就会为其他进程所见,并且这些修改也会造成对文件的改动。
内存映射用途很多,如文件 I/O(即映射内存 I/O)以及进程间通信(通过共享映射)。在后续我们还会更深入的探讨。
1.1.7 信号
尽管1.5.5将信号视为 IPC 的方法之一,但其在其他方面的广泛应用则更为普遍。
人们往往将信号称为“软件中断”。进程收到信号,就意味着某一事件或异常情况的发生。
信号的类型很多,每一种分别标识不同的事件或情况。采用不同的整数来标识各种信号类型,并以 SIGxxxx 形式的符号名加以定义。
-
信号发送,内核、其他进程(只要具有相应的权限)或进程自身均可向进程发送信号。
发生下列情况之一时,内核可向进程发送信号:
- 用户键入中断字符(通常为 Control-C)。
- 进程的子进程之一已经终止。
- 由进程设定的定时器(告警时钟)已经到期。
- 进程尝试访问无效的内存地址。
在 shell 中,可使用
kill命令向进程发送信号。在程序内部,系统调用 kill()可提供相同的功能。 -
信号回复,收到信号时,进程会根据信号采取如下动作之一:
- 忽略信号。
- 被信号“杀死”。
- 先挂起,之后再被专用信号唤醒。
就大多数信号类型而言,程序可选择不采取默认的信号动作,而是忽略信号或者建立自己的信号处理器。信号处理器是由程序员定义的函数,会在进程收到信号时自动调用,根据信号的产生条件执行相应动作。
1.1.8 线程
在现代 UNIX 实现中,每个进程都可执行多个线程。
什么是线程?
线程是操作系统能够进行运算调度的最小单位,被包含在进程之中,是进程中的实际运作单位。
- 每个线程都会执行相同的程序代码,共享同一数据区域和堆;
- 每个线程都拥有属于自己的栈,用来装载本地变量和函数调用链接信息。
为什么需要线程?
线程的主要优点:
- 协同线程之间的数据共享(通过全局变量)更为容易、自然;
- 多线程创建、销毁等开销小;
- CPU利用率高,如果一个子任务阻塞,程序可以将CPU调度到另外一个子任务进行工作。这样CPU还是保留在本程序中,而不是被调度到别的进程去。这样,提高了本程序所获得的CPU时间和利用率。
线程之间如何通信?
- 利用前述进程之间的通信方式(IPC);
- 利用共享的全局变量进行通信,借助于线程 API 所提供的条件变量和互斥机制,进程所属的线程之间得以相互通信并同步行为。
1.1.9 会话、控制终端和控制进程
会话、控制终端和控制进程之间概念和关系如下。
会话
会话是一个或多个进程组的集合,会话中的所有进程都具有相同的会话标识符。
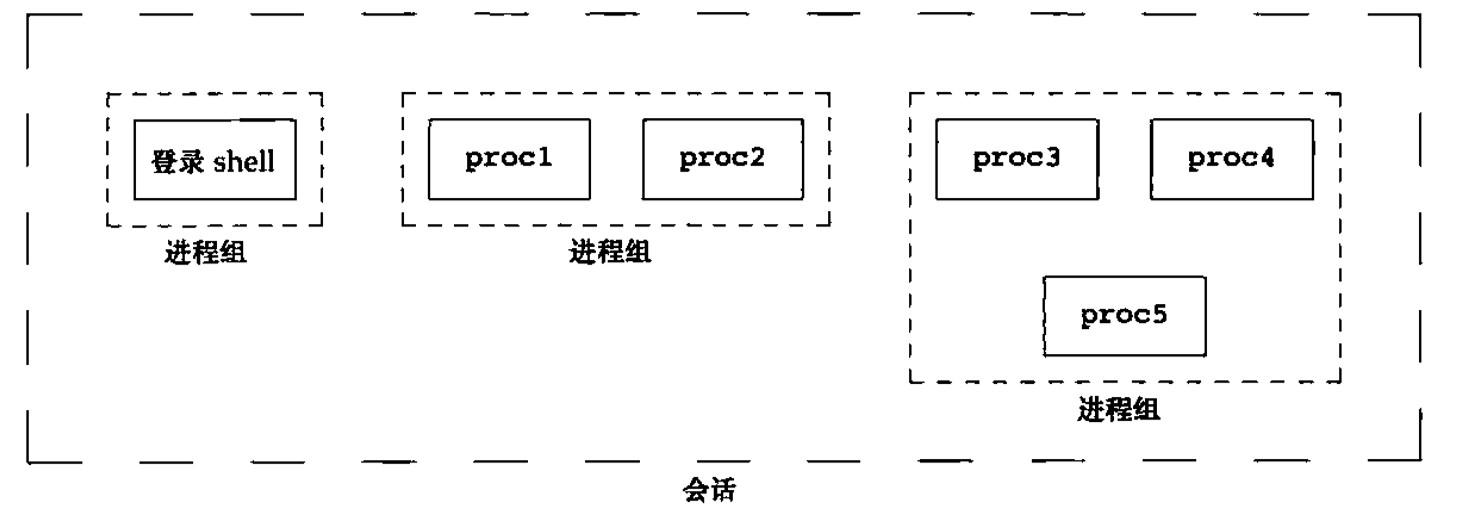
会话与shell的关系?
使用会话最多的是支持任务控制的 shell,由 shell 创建的所有进程组与 shell 自身隶属于同一会话,shell 是此会话的会话首进程。
控制终端
当一个终端与一个会话相关联后,那么这个终端就称为该会话的控制终端,建立与控制终端连接的会话首进程(一般是shell)被称为控制进程(controlling process)。
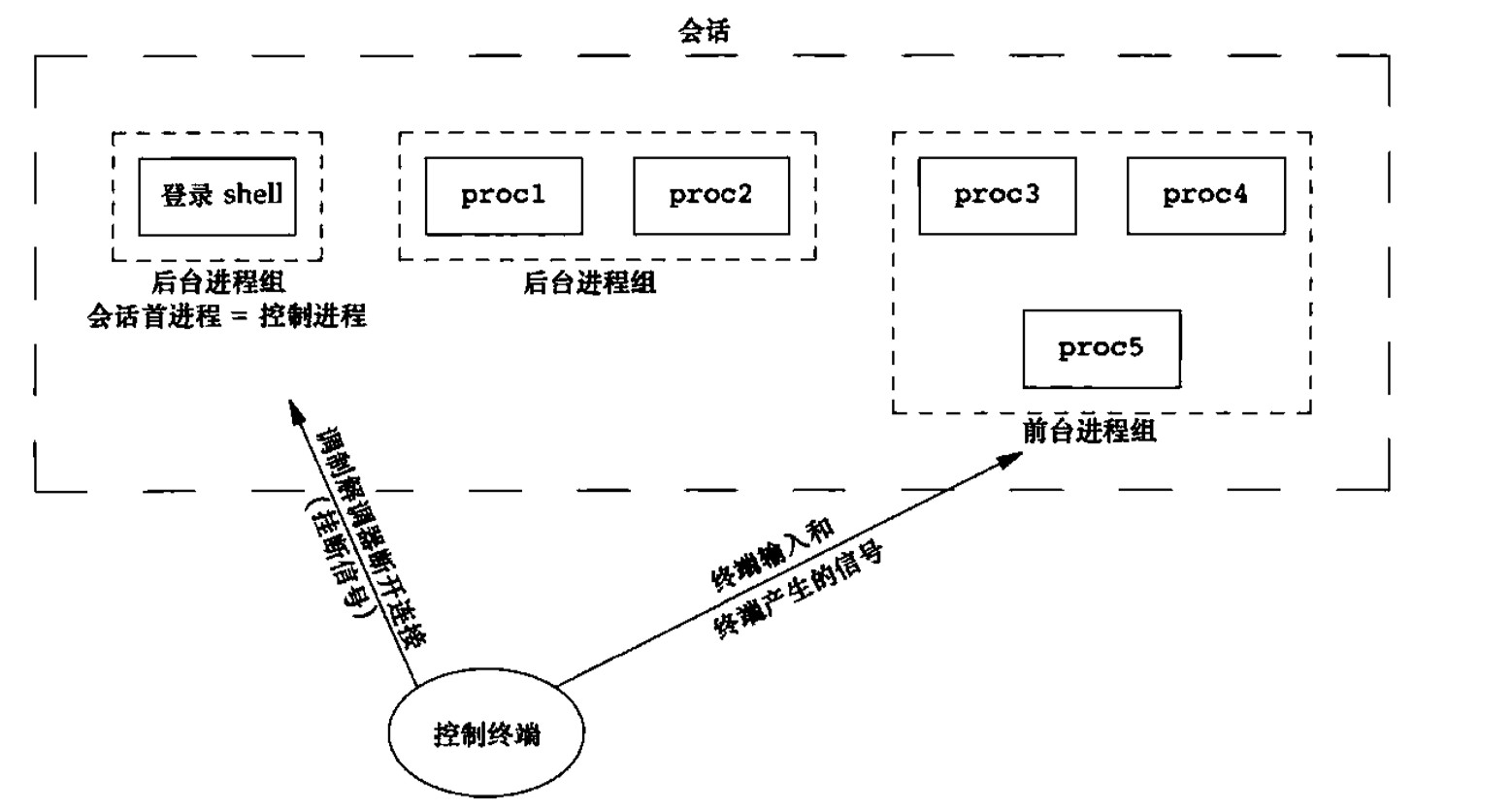
控制终端关闭时,会话中各个进程的变化?
简单来说,shell进程和前台所有进程会退出,后台无终端输出进程退出。
- 首先会发一个挂断信号SIGHUP给会话首进程(一般为shell),即shell进程退出。
- 当会话首进程shell退出时,挂断信号(SIGHUP)还会继续发送给前台进程组和后台有终端输出的所有进程。
若进程未对挂断信号(SIGHUP)进行处理时,所有收到该信号的进程将被终止。
如何让进程在终端关闭时,不受其影响进行执行?
根据前述,若想进程在终端关闭时不受影响:
- 如果该进程无终端输出,让该进程成为后台进程;
- 如果该进程有终端输出,还忽略SIGHUP信号;
- 让程序对挂断信号SIGHUP进行处理。
针对1、2我们可以使用命令:
1 | nohup <command> & |
- nohub,忽略所有挂断(SIGHUP)信号;
- &,程序进程进入后台运行。
实例:nohub python run.py & 。
针对3,我们还可以让程序自动具备防退出功能。
1 |
|
1.10 /proc目录
Linux系统上的/proc目录是一种文件系统,即proc文件系统。 /proc是一种伪文件系统(也即虚拟文件系统),存储的是当前内核运行状态的一系列特殊文件,用户可以通过这些文件:
- 查看系统有关(1)硬件及当前(2)正在运行进程的信息;
- 更改其中某些文件来改变内核的运行状态。
例如,查看磁盘信息:
1 | [root@roy-cpp proc]# cat /proc/devices |
1.2 系统编程基本概念
什么是系统编程?
系统编程,是指进程(或者说程序)以API形式,去调用系统内核提供的一系列服务如:
- 创建进程
- 执行IO
- 进程通信
- …
等来完成程序编写。
可以看到前述核心过程是调用系统内核服务,也就是我们常说的系统调用。
1.2.1 系统调用
在深入系统调用的运作方式之前,请务必牢记以下几点:
- 检测返回状态,无论何时,只要执行了系统调用或者库函数,检查调用的返回状态以确定调用是否成功,这是一条编程铁律。
- 核心态切换,系统调用将处理器从用户态切换到核心态,以便 CPU 访问受到保护的内核内存。
- 每个系统调用由数字标识,系统调用的组成是固定的,每个系统调用都由一个唯一的数字来标识。
- 每个系统调用都有对应参数。
现在我们来以具体的硬件平台x86-32为例,来分析系统调用发生时的步骤:
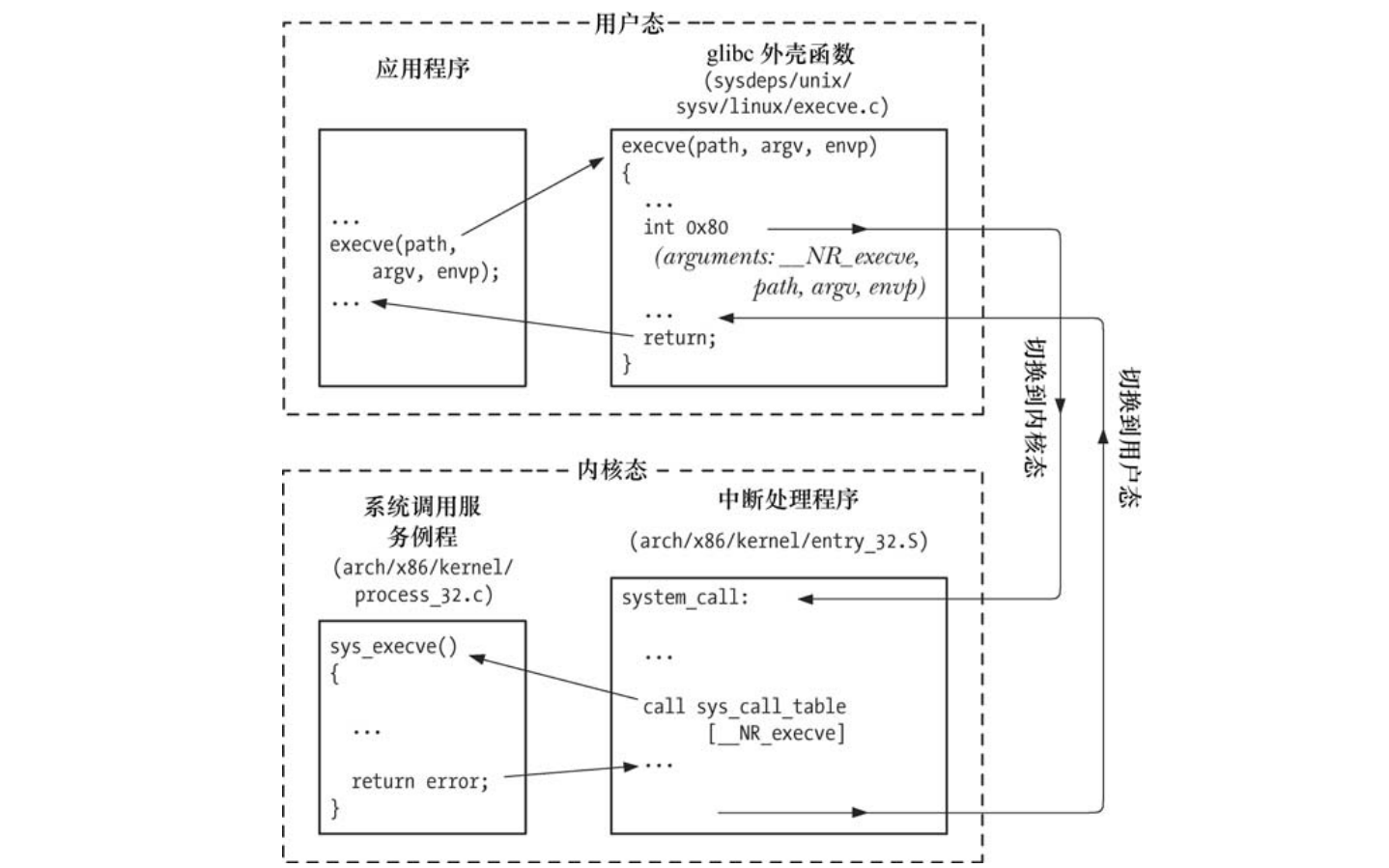
-
调用外壳函数,应用程序通过设置相应的参数来调用 C 语言函数库中的外壳函数,然后发起系统调用;
-
参数传入寄存器,内核希望将这些函数参数置入特定寄存器,因此,外壳函数会将上述参数复制到寄存器;
-
系统调用编号传入寄存器
%eax,由于所有系统调用进入内核的方式相同,内核需区分每个系统调用,为此,外壳函数会将系统调用编号复制到一个特殊的 CPU 寄存器(%eax)中; -
执行中断,外壳函数执行中断机器指令(int 0x80)→处理器从用户态切换到核心态→执行系统中断 0x80;
-
响应中断,保存寄存器值→审核系统编号有效性→查询服务列表sys_call_table→执行系统调用→返回状态参数给sys_call();
- 关于sys_call_table,在 Linux/x86-32 上,execve()的系统调用号为 11(__NR_execve)。因此,在 sys_call_table 向量中,条目 11 包含了该
系统调用的服务例程 sys_execve()的地址。
- 关于sys_call_table,在 Linux/x86-32 上,execve()的系统调用号为 11(__NR_execve)。因此,在 sys_call_table 向量中,条目 11 包含了该
-
结束中断,内核栈中恢复各寄存器值→系统调用返回值置于栈中→处理器切回用户态。
-
返回值错误处理,若系统调用服务例程的返回值表明调用有误,外壳函数会使用该值来设置全局变量 errno。
1.2.2 C语言函数库glibc
GNU C 语言函数库[glibc](http://www.
gnu.org/software/libc/),是 Linux 上最常用的实现。
查看一下我们机器上的glibc版本吧:
1 | [root@roy-cpp TLPI]# /lib64/libc.so.6 |
动态库libc.so.6 可视为可执行文件,输出当前glibc版本,一般位于目录/lib64/libc.so.6 或 /lib/libc.so.6 下。
1.2.3 处理返回的错误
不检查状态值,少敲几行代码听起来的确诱人,但实际却得不偿失。
每个系统调用和库函数都会返回某类状态值,要了解调用是否成功,必须坚持对状态值进行检查。
这能节约我们大把的程序调试时间。
处理系统调用错误
绝大部分系统检查调用错误信息步骤:
- 先检查系统调用返回值是否错误(为-1),如果错误转2;
- 继续检查 errno号,来确定具体错误。
下面举一个例子。
1 | cnt = read(fd,buf1,len); |
检查errno号也可以直接替换使用perror(char* str) 函数,其会打印我们输入字符串str + 当前error对应的错误信息。
以下是一个更完整的例子展示。
1 |
|
输出:
1 | [root@roy-cpp TLPI]# g++ -g chap3.cpp -o chap3.out |
处理库函数调用错误
库函数调用和系统调用错误有些不同。
- 和系统调用一致:返回值为-1,配合error号进行检查;
- 出错返回值不一定为-1,如
fopen出错返回NULL指针,配合error进行检查; - 部分库函数根本不使用error。
在本章,主要介绍了Linux发展历史,以及Linux&系统编程的基本概念。在下一章,我将主要介绍文件I/O相关知识。
更新记录
- 第一次更新
参考文献
[1] linux的控制终端: http://shareinto.github.io/2016/11/17/linux-terminal/
[2] 黑马程序员教程:https://book.itheima.net/course/223/
 微信
微信 支付宝
支付宝


