
C++从零开始(开源):一文读懂muduo
🌟《C++从零开始》 系列,工作快一年,终于又开始更新了…🥗

在学校接触C++比较少,主要是用Java 、Python较多。入职腾讯前,为了恶补下C++网络相关基础,读了一些经典的demo级 开源库,如 Tinyhttpd 、Zavar 等。入职后大多数时候在业务屎山上玩耍,内部也有封装好的网络框架,但一直对网络通信底层挺感兴趣。
疫情过后,所在的业务收缩(千万PCU–>百万PCU),并发数下降了一个量级。也算有了难得的时间,来静下来心来读一些工业级别的开源库。经过调研,锁定在muduo-cpp11 、brpc 两个项目,先花了一周先读完了相对简单的muduo,写篇文章给自己总结回顾,也给后来者一份全面清晰地参考吧。
一、Muduo整体架构
注意,muduo 源码@chenshuo基于boost,本文代码引用@S1mpleBug基于C++11改写的muduo-cpp11。
1.1 从EchoServer说起
1.1.1 快速开始
下好源码后,我们编译一下项目中EchoServer示例:
1 | git clone https://github.com/S1mpleBug/muduo_cpp11 |
一个简单“复读机”服务器便诞生了:

1.1.2 “复读机“服务器业务层实现
muduo的接口使用相当方便和精简:
-
首先定义一个EchoServer类
该类主要有如下功能:
- 封装了TcpServer类对象
server_,在muduo中,TcpServer是整个框架逻辑层面的入口; - 用户注册自定义的事件(新客户端连接、客户端消息响应)回调函数,也即是业务层面逻辑处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
class EchoServer
{
public:
EchoServer(EventLoop *loop, const InetAddress &addr, const std::string &name)
: server_(loop, addr, name) // TcpServer server_; TcpServer对象初始化
, loop_(loop)
{
// 注册回调函数
server_.setConnectionCallback( // onConnection,打印下连接的客户端ip+port
std::bind(&EchoServer::onConnection, this, std::placeholders::_1));
server_.setMessageCallback( // onMessage:将客户端发来的信息原样返回send
std::bind(&EchoServer::onMessage,
this,
std::placeholders::_1,
std::placeholders::_2,
std::placeholders::_3));
// 设置合适的subloop线程数量
server_.setThreadNum(3);
}
void start()
{
server_.start();
}
private:
// 连接建立或断开的回调函数
void onConnection(const TcpConnectionPtr &conn)
{
if (conn->connected())
LOG_INFO("Connection UP : %s", conn->peerAddress().toIpPort().c_str());
else
LOG_INFO("Connection DOWN : %s", conn->peerAddress().toIpPort().c_str());
}
// 可读写事件回调
void onMessage(const TcpConnectionPtr &conn, Buffer *buf, Timestamp time)
{
std::string msg = buf->retrieveAllAsString();
conn->send("muduo: " + msg);
// conn->shutdown(); // 关闭写端 底层响应EPOLLHUP => 执行closeCallback_
}
EventLoop *loop_;
TcpServer server_;
}; - 封装了TcpServer类对象
-
启动服务器
EchoServer对象start(),main loop开启事件循环loop()。整个服务器便顺利启动了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15int main()
{
// 1.用户自定义的loop作为main loop
EventLoop loop;
// 2. 对socket编程中的sockaddr_in进行封装
InetAddress addr(8002);
// 3.EchoServer初始化
EchoServer server(&loop, addr, "EchoServer");
// 4.启动服务器server
server.start();
// 5.开启main loop事件循环:epoll_wait等待listenfd的accpet连接事件
loop.loop();
return 0;
}
即使你目前对上述出现loop 、事件循环 等概念还一无所知。但足够简洁的API接口,做业务层的开发,却已经可以实现一个自己的高性能“复读机”服务器了!
1.2 整体架构:Multi-Reactor
1.2.1 高并发之网络IO模型
高并发即我们所说的 C10K(一个 server 服务 1w 个 client), C10M(一个 server 服务 1M 个 client) 。这节将主要循序渐近地,介绍如何设计出一个高并发网络 IO 框架:
- 传统同步阻塞 IO 模型的缺陷
- 针对传统同步阻塞 IO 模型缺陷的改进
- IO 多路复用
- Reactor模型
传统同步阻塞 IO 模型的缺陷
在该小节我们重点关注以下两点:
- 传统同步阻塞 IO 模型有哪些缺陷?
- 传统同步阻塞IO 模型阻塞点有哪些?
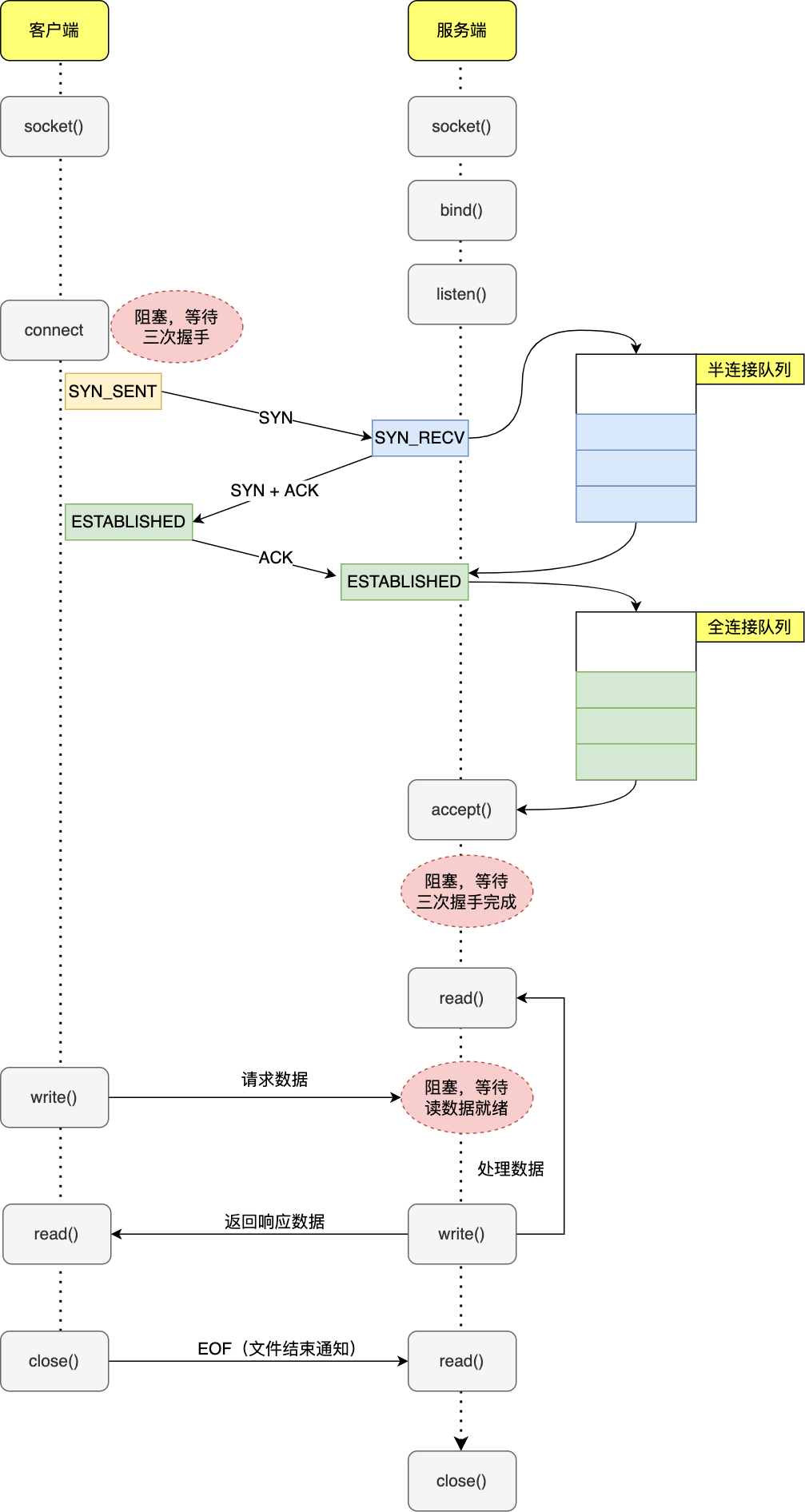
先重温下客户端和服务端的基于TCP的通信流程:
| 客户端和服务端TCP通信流程 | 伪代码 |
|---|---|
 |
 |
-
服务端:server 调用
socket()创建监听 socket 后,执行bind()绑定 IP 和端口,然后调用listen()监听,代表 server 已经准备好接收请求了,listen 的主要作用其实是初始化半连接和全连接队列大小; -
客户端:server 准备好后,client 也创建 socket ,然后执行
connect()向 server 发起连接请求,这一步会被阻塞,需要等待三次握手完成:-
第一次握手完成,服务端会创建 连接socket,将其放入半连接队列中;
连接socket与监听socket区分?
- 监听socket,即服务端调用
socket()返回的监听 socket ,负责特定客户端和服务器的等待连接、建立连接,不负责数据传输; - 连接 socket,即accept后返回的连接 socket, 负责在连接完成后与指定客户端完成一对一的数据传输。
二者各司其职。
- 监听socket,即服务端调用
-
第三次握手完成,系统会把 连接socket 从半连接队列摘下放入全连接队列中,然后 accept 会将其从全连接队列中摘下,之后此 连接socket就可以与客户端 socket 正常通信了,默认情况下如果全连接队列里没有 连接socket,则 accept 会阻塞等待三次握手完成。
-
-
read/业务处理/write,该过程也往往发生阻塞,比如:
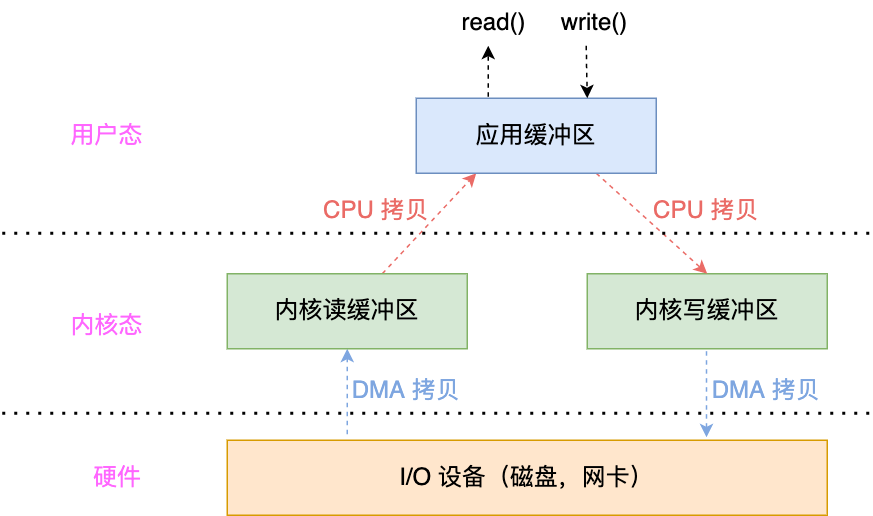
- read/write需要等待内核缓冲区数据就绪/有空间可写等;
- 业务处理过程也往往会发生阻塞。
开头的问题也就很好回答了,对于传统同步阻塞 IO:
- 阻塞点:传统的socket通信会阻塞在connect,accept,read/write 这几个操作上。
- 缺陷点:性能低下,如单进程/线程,只要 server 阻塞,就不能处理其他 client 。
针对同步阻塞IO模型缺陷的改进
针对上面的阻塞点,我们可以做如下进行改进。
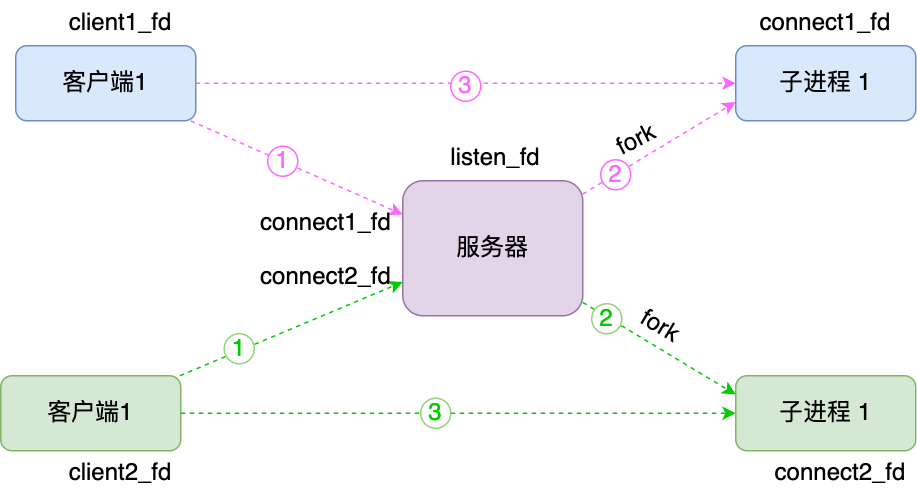
多进程/线程:避免read/业务处理/write阻塞
如果 server 是单进程/线程,connect/accept & read/业务处理/write 这几个操作很容易发生阻塞,只能串行执行,如果把read/业务处理/write 交给子进程/线程处理?这一定程度上提高了服务器并发。
一般是使用多线程,因为多进程相对多进程负担更大:
要考虑“子进程善后”:当「子进程」退出时,实际上内核里还会保留该进程的一些信息,也是会占用内存的,如果不做好“回收”工作,就会变成僵尸进程,慢慢耗尽我们的系统资源;因此,父进程要在子进程退出后回收资源,分别是调用
wait()和waitpid()函数。进程的上下文切换不仅包含了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的资源;
进程创建/开销大。
-
父进程/线程负责 accept(listenfd)等待客户端新连接, 有新连接fork一个子进程/创建一个线程,把accept返回的connfd 交给子进程/线程处理;
父进程中accept依旧会阻塞等待连接就绪。
-
子进程/线程负责read(connfd)/write(connfd)等待connfd读写,这样就算子进程/线程read/业务处理/write阻塞了,但不影响父进程/线程处理client连接。
| 多进程IO | 伪代码 |
|---|---|
 |
 |
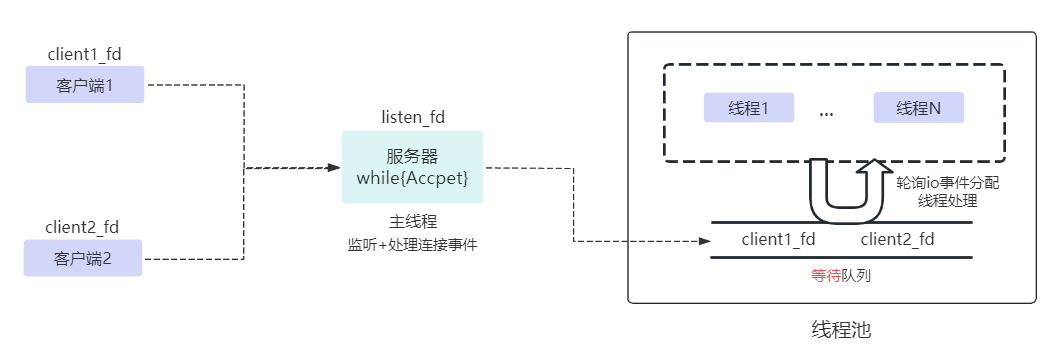
同步阻塞IO优化1:线程池
无论是多进程还是多线程,进程/线程创建、销毁的开销其实并不小。因此我们还会往往用进程池or线程池进行管理。
需要注意的是,等待队列是全局的,每个线程都会操作,为了避免多线程竞争,线程在操作这个队列前要加锁。
同步阻塞IO优化2:设置非阻塞
对于同步多线程阻塞模型,为了线程io(read/业务处理/wirte)阻塞不影响处理下一个连接,我们虽然使用了多线程+线程池来提高服务的吞吐,但如果上万个连接同时到来,服务器资源还是很容易遇到瓶颈。
想象一下,如果有1w个客户端同时发生连接,:
-
主进程开始处理client1:主进程阻塞等待connect/accept就绪,连接建立==>返回连接socket connfd1给子进程1处理==>子进程1开始阻塞等待read/wirte就绪;
-
主进程开始处理client2:…
…
-
主进程开始处理clientN:…
不难发现,过多的阻塞等待浪费了服务器性能:
- 对于主进程:大量时间浪费在等待connect/accept就绪,如果当前连接未就绪完全可以去先处理下一个连接;
- 对于子进程:大量时间浪费在等待reda/write就绪,当前connfd如果read/write未就绪,可以先去处理下一个connfd。
- 对于子进程:大量时间浪费在等待read阻塞到可读/业务处理完成/write阻塞上,等待read/write就绪过程,也可以处理其它事情。
因此,我们设置为非阻塞:
-
对于进程的阻塞操作(connect,accept,read/write),改为非阻塞:
-
如果相应的事件未准备好,就立马返回 EWOULDBLOCK 或 EAGAIN 错误,不阻塞进程;
-
使用 fcntl 可以可以将 socket 设置为非阻塞 。
1
2
3
4connfd = accept(listenfd);
fcntl(connfd, F_SETFL, O_NONBLOCK);
// 此时 connfd 变为非阻塞,如果数据未就绪,read 会立即返回
int n = read(connfd, buffer) != SUCCESS;
-
-
对于业务处理阻塞 ,可以新开一个线程去处理,不影响主流程。
如此,减少了大量不必要的阻塞等待,没有就绪就立即返回,服务器的性能得到进一步榨干。
而且,现在一个线程就可以处理多个连接,两种实现:
-
一个线程不断轮询所有描述符:
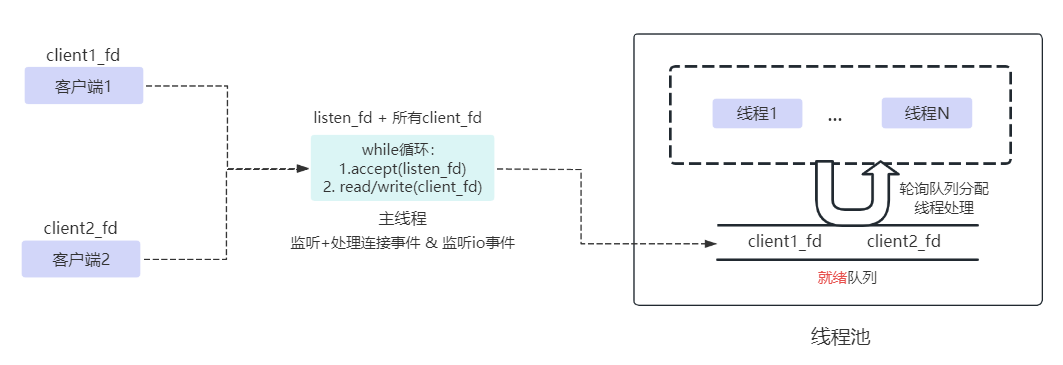
- 遍历listenfd & connfd ;
- 如果是listenfd ,accept是否有返回connfd,是通知用户程序处理,不是也不阻塞立即返回;
- 如果是connfd,read/write 是否就绪,是则通知用户程序处理,不是也不阻塞立即返回 ;
- 重复以上。
-
基于I/O多路复用,向内核注册后,一个进程可以监听多个描述符fd,一旦某个描述符就绪(连接就绪/读就绪/写就绪),内核通知用户程序进行相应的处理。
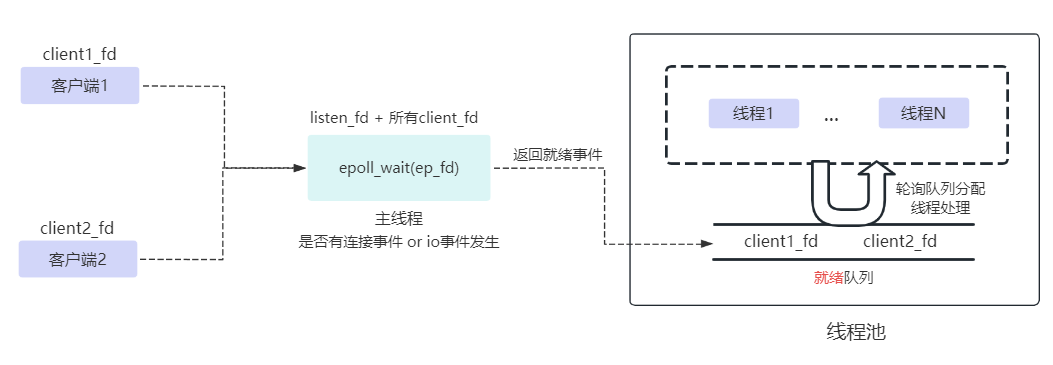
第一种同步非阻塞IO模型实现基于循环+非阻塞,即用户需要不断循环进行系统调用read/write查询fd状态,虽然用户线程每次发起IO请求后可以立即返回,但是为了等到数据,仍需要不断地轮询、重复请求,消耗了大量的CPU的资源。一般很少直接使用这种模型。
第二种I/O多路复用,避免同步非阻塞IO模型中不断轮询和大量系统调用accpet/read/write,直接向内核注册fd感兴趣的事件,不必须设置非阻塞(但I/O多路复用往往是结合非阻塞),基于事件机制通知用户程序。
IO多路复用:select/poll/epoll
目前支持I/O多路复用的系统调用有select,pselect,poll,epoll。与多进程和多线程技术相比,I/O多路复用技术的最大优势是可以,在内核注册事件后,可以在一个进程/线程高效地监听多个客户端fd 。
在以前的个人博客,详细分析过,这里简单放下select/poll/epoll伪代码比对:
select: ①每次一个fd可读需遍历所有;③描述符有上限 ;③ 大量描述符数组被整体复制于用户态和内核态的地址空间;④ ;poll:①每次一个fd可读需遍历所有;② 描述符无上限 ;③大量描述符数组被整体复制于用户态和内核态的地址空间;epoll:①只需遍历就绪的fd; ②描述符无上限; ③有mmap映射高效缓冲区,没有大量描述符从用户态和内核态直接的复制。
为了便于阅读,以下代码均未展示线程池来处理io事件。
| select | poll | epoll |
|---|---|---|
 |
 |
 |
Reactor模式:继续优化多路IO
我们已经知道 IO 多路程复用是用一个进程来管理多个 socket 的, 那么是否还有优化的空间呢?
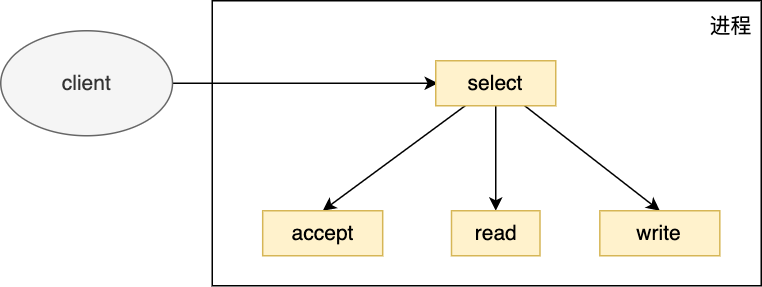
以最简单的select为例:
- 调用 select 来监听连接,读写事件;
- 收到事件后判断是否是监听 listenfd 上的连接事件,是的话调用 accept() ;
- 否则判断是否是已连接 connfd 上的读写事件,是的话调用 read()/write() 。
| select流程图 | select伪代码 |
|---|---|
 |
|
上面的写法没啥问题,但是逻辑过于耦合,如果:
- select单独一个子逻辑,负责监听;
- listenfd上的连接事件,单独拆分一个子逻辑;
- connfd 上的读写事件,单独拆分一个子逻辑。
这样会不会更好?
单进程/线程&单Reactor模式
为了提高扩展性&避免耦合性,我们将IO多路复用模型再拆分为三个模块:
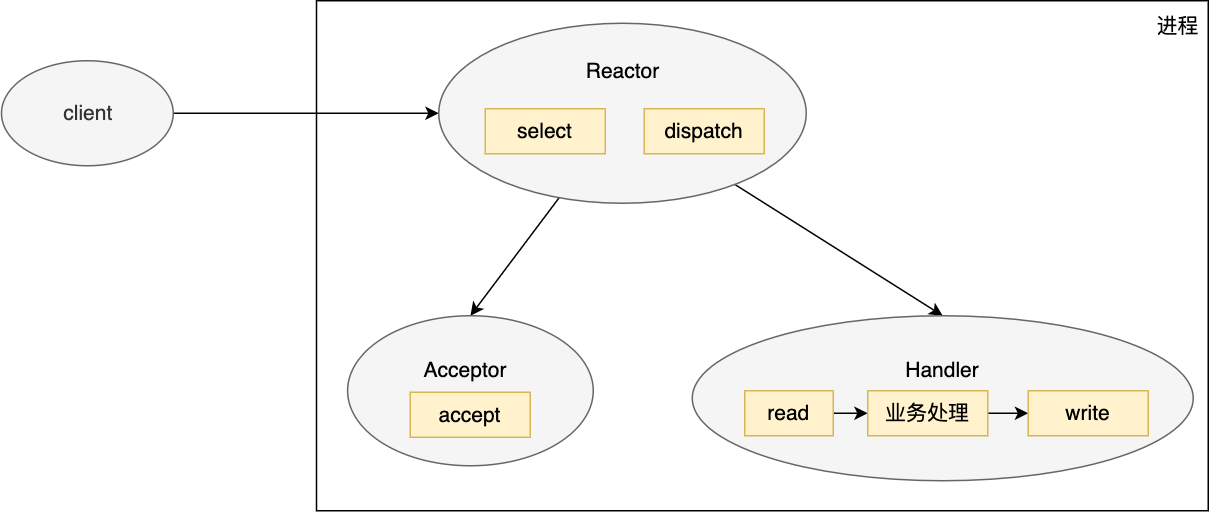
- Reactor, 对象首先调用 select 来监听 listenfd/connfd事件,收到事件后会通过 dispatch 分发;
- Acceptor,如果是连接建立事件,则由 Acceptor 处理,Acceptor 通过调用 accept 接收连接,并且会创建一个 Handler 来处理后续的读写等事件;
- Handler,如果不是连接建立事件,则 Reactor 会调用连接对应的 Handler 进行响应,handler 会完成 read/业务处理/write 的完整业务处理流程。
以上这些操作其实和之前的 IO 多路复用一样,所有的操作还是在一个进程/线程进行,只不过进行更细分拆解。
但是:
- 单进程/线程也没有充分利用多核优势;
- 业务处理耗时较长,那么进程/线程就会被阻塞。
那么改成多进程/线程,会不会更好?
多进程/线程&单Reactor模式
于是人们又提出了 单 Reactor 多线程模型:
-
主进程依旧负责处理:Reactor(监听 listenfd/connfd)、Accpetor(accpet连接&创建Handle处理)、Handle(处理read/write,业务逻辑不再处理);
-
每个Handler的业务处理,改为分配一个线程处理。
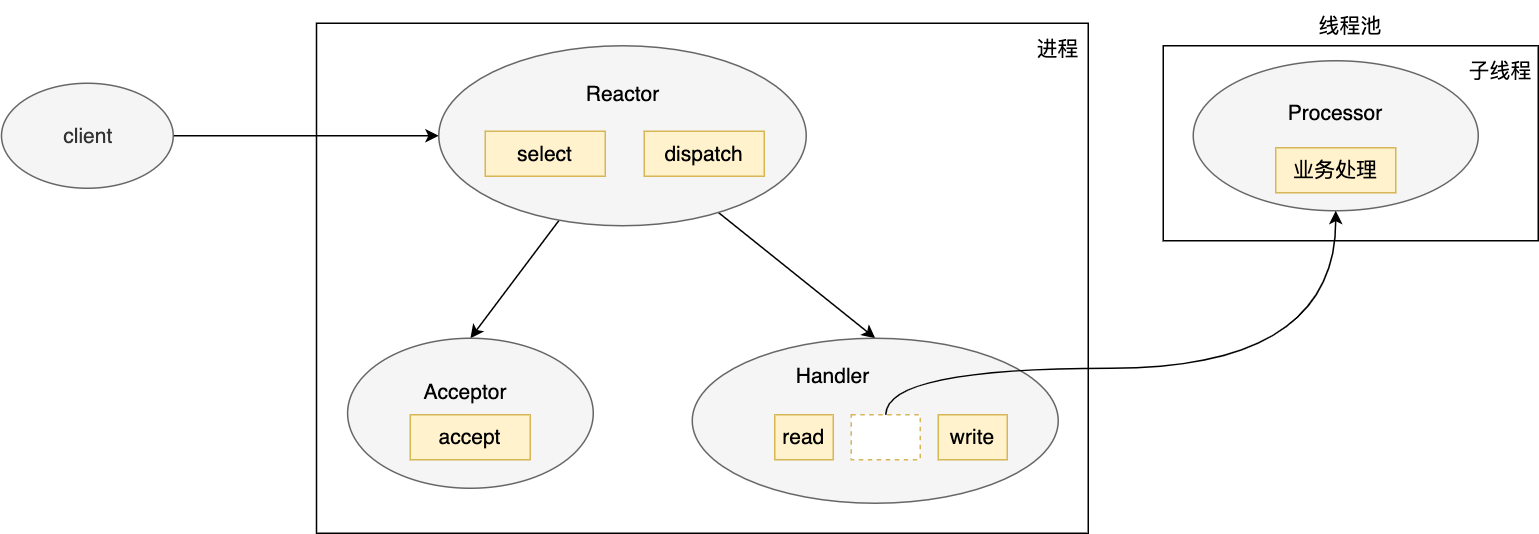
但依然有如下两个瓶颈点:
-
子线程处理好业务数据后需要将其传回 handler进行发送处理,这涉及到共享数据的互斥和保护机制;
Handler能不能在一个线程全部处理read/业务逻辑/write,避免跨进程/线程通信?
事实上,zaver就是这么做的,参考之前画的流程图:
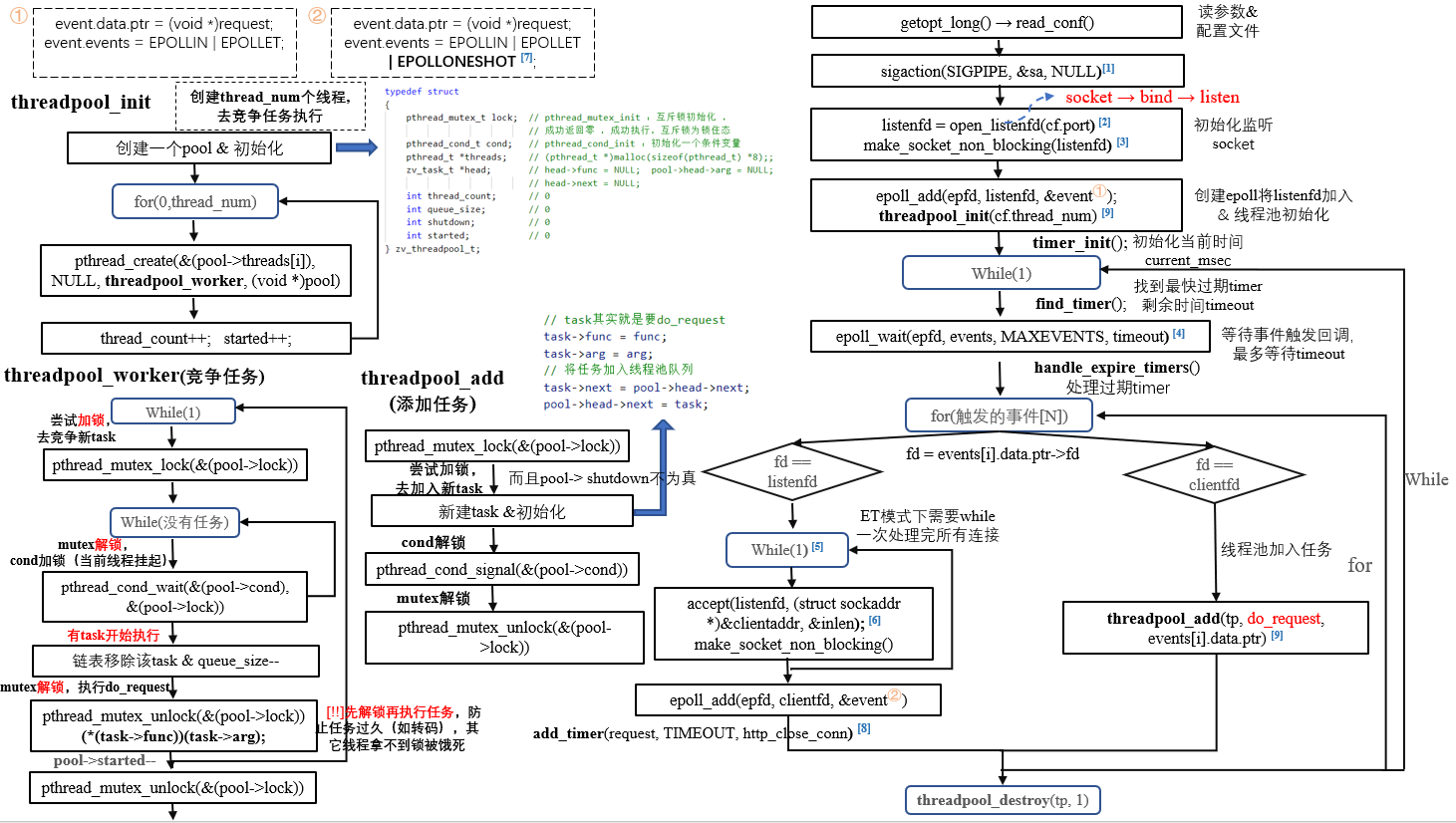
不过这里的主要瓶颈我认为是第二点。
-
主进程单个Reactor负责监听所有fd(listenfd & clientfd)io事件,在客户端瞬时大并发,会出现性能瓶颈。
其它Reator分担一些事件监听如io事件等,那该多好?这也是主要瓶颈所在。
多进程/线程&多Reactor模式
基于以上逻辑考虑,多进程/线程&多Reactor模式诞生了:
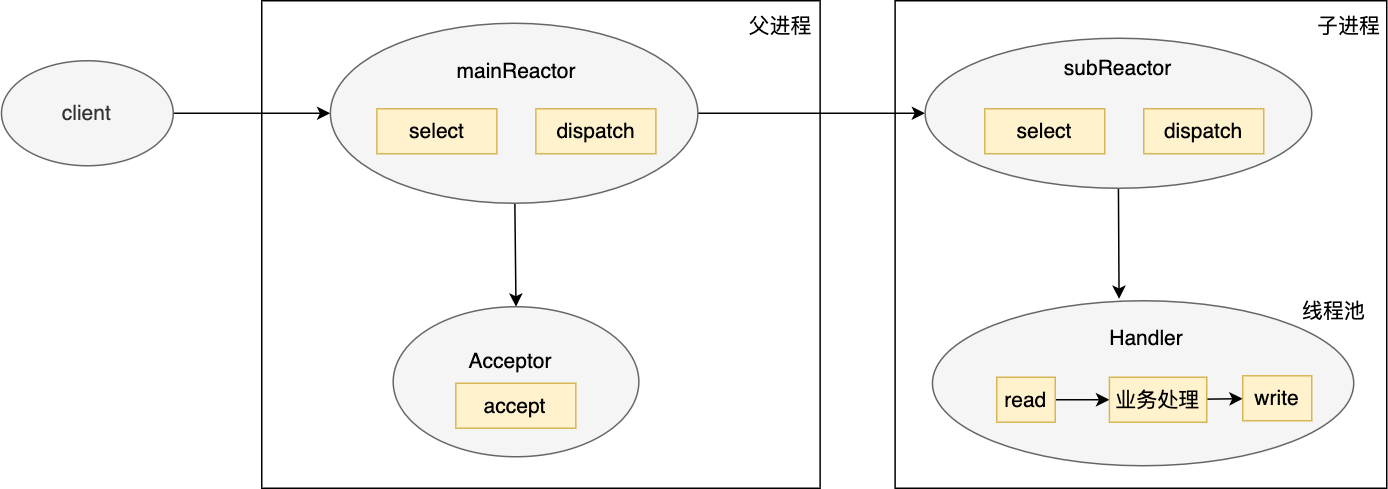
工作原理如下:
- 主进程负责处理:Mian-Reactor(只监听listenfd)、Accpetor(accpet连接&创建Handle处理),接收connfd后会将其传给 subReactor;
- 子进程负责处理:Sub-Reactor(只监听connfd的io读写事件),将其连接加入连接队列中来监控;
- Handler,一起处理read/业务逻辑/write,每个Handler一个线程。
以上介绍的只是标准的 Reactor 模型,但实际上生产上应用的 Reactor 不一定完全遵照这些标准。
一起看看muduo怎么做的!
1.2.2 Muduo与Reactor模式
Muduo采用的便是多线程&多Reactor模式。
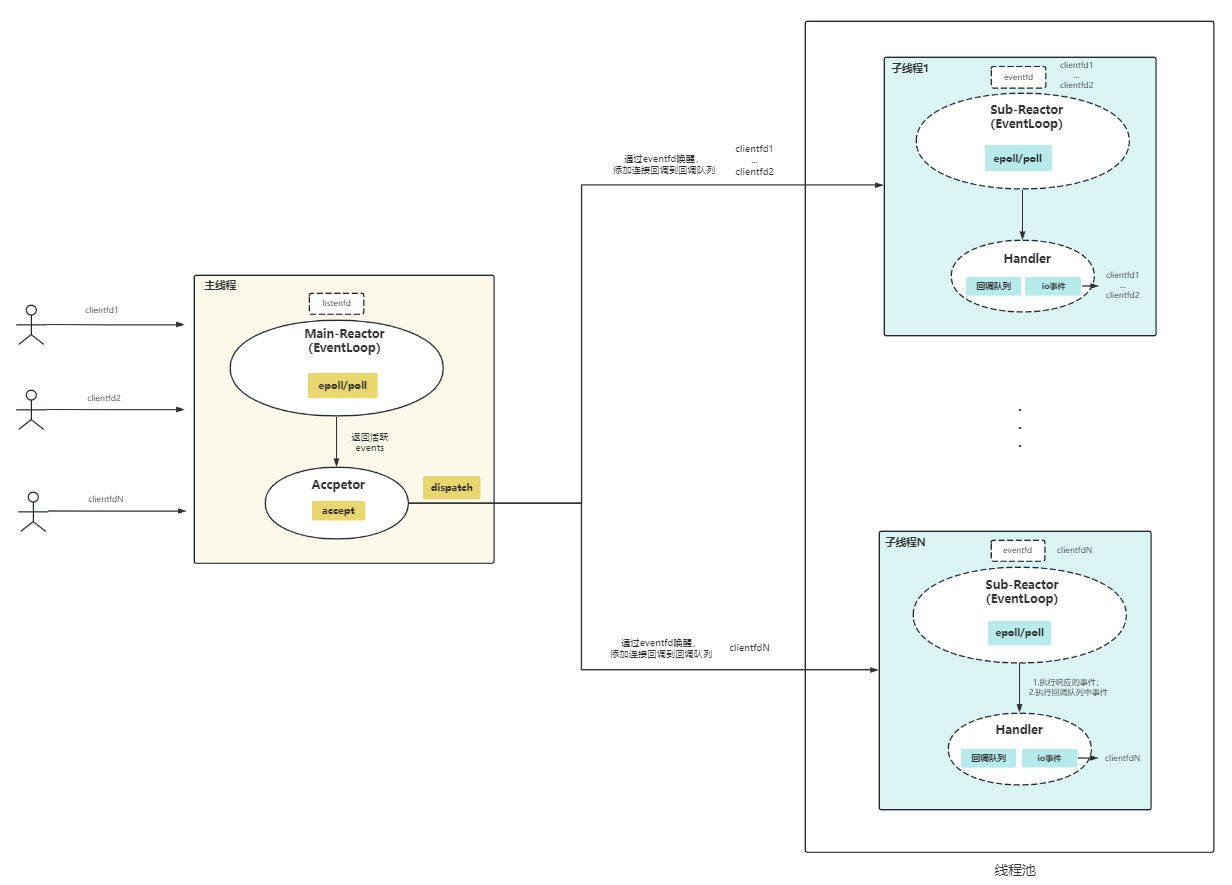
- 主进程中,Main-Reactor负责监听listenfd,等待连接事件;Accpetor负责accpet连接返回connfd(注意在muduo,dispatch逻辑实际也在Accpetor中:用于分配一个Sub-Reactor&绑定/注册返回connfd)。
- 子进程中(1~N),每个子进程运行一个Sub-Reactor,负责监听已注册的connfd等待io读写事件。
在muduo中,每个Main-Reactor/Sub-Reactor抽象为EventLoop对象,且运行在一个线程中。这也是one loop per thread的由来。
仅仅通过上图,也能发现muduo不少特别之处:
- 每个Sub-Reactor都会负责监听一部分connfd的io事件,提高了服务器处理连接能力;
- Sub-Reactor和Main-Reactor通信,是通过更高效eventfd,而不是像Main-Reactor使用socket listen()和客户端通信;
- Sub-Reactor不仅要①处理其负责的connfds的io事件;②还要处理回调队列中的事件。
上面的Reactor/Accpetor/…概念,又是在muduo代码中怎么抽象实现?一起看看!
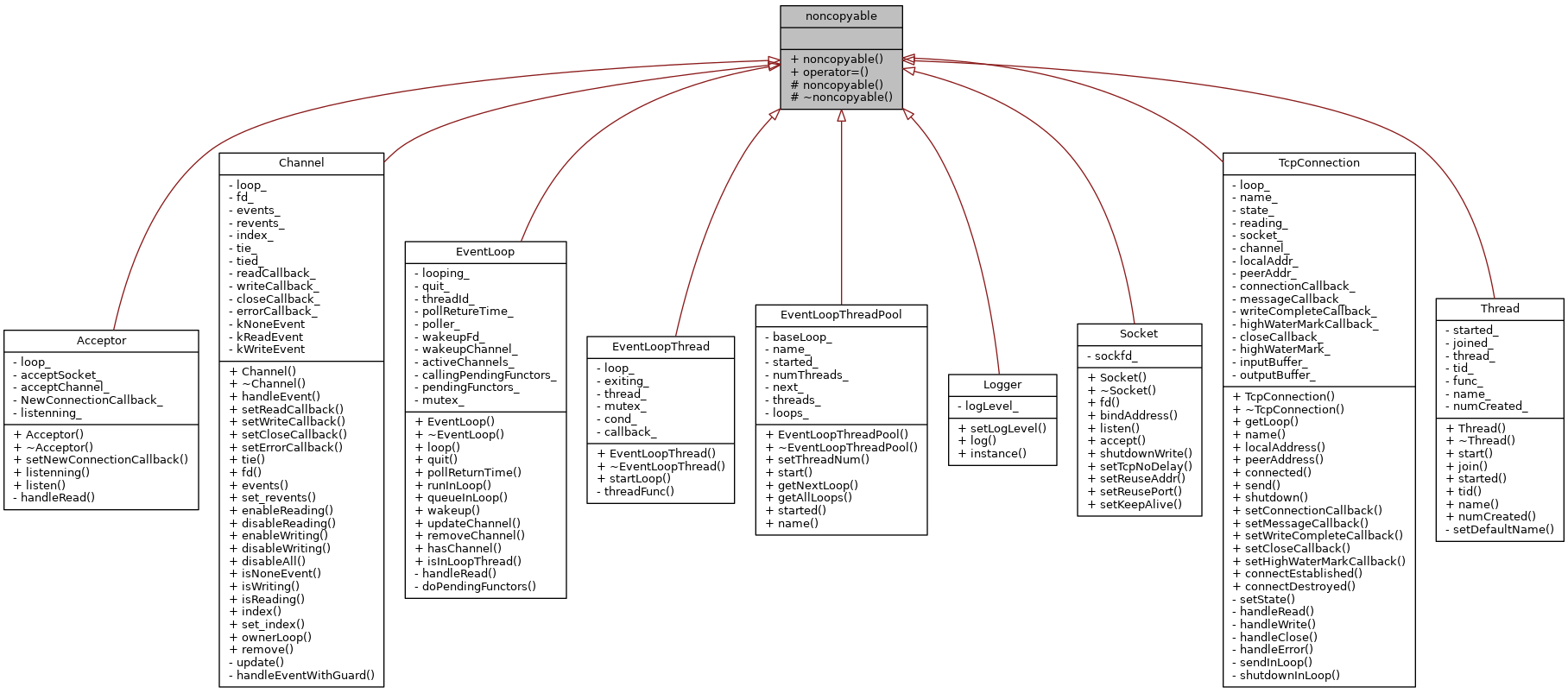
1.3 Muduo核心类
Muduo核心类的结构如下:
为什么要继承NonCopyable基类?
好处:强制只能以指针的方式使用, 不能以拷贝类的方式来使用, 避免反复拷贝内存空间消耗。
具体实现:这个类将拷贝和赋值构造函数给delete掉,提供了一个不可拷贝的基类
2
NonCopyable &operator=(const NonCopyable &) = delete;
1.3.1 Reactor:Poller、EventLoop、EventLoopThread、TcpConnection、Channel
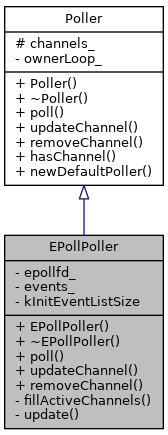
Poller类 & EPollPoller类
Poller类底层封装epoll & poll,它还会被EPollPoller继承,EPollPoller是epoll的封装类。整体实现比较简单。
其中:
- updateChannel()、removeChannel() ,等函数是封装
EPOLL_CTL_ADD、EPOLL_CTL_DEL; - Poller,构造函数owerLoop标识了当前Poller对象所属Loop;析构函数,默认;
- EollPoller构造函数,执行Poller构造函数,创建epollfd;析构函数关闭epollfd。
| Poller & EPollPoller成员及继承关系 | EPollPoller构造函数&析构函数 |
|---|---|
 |
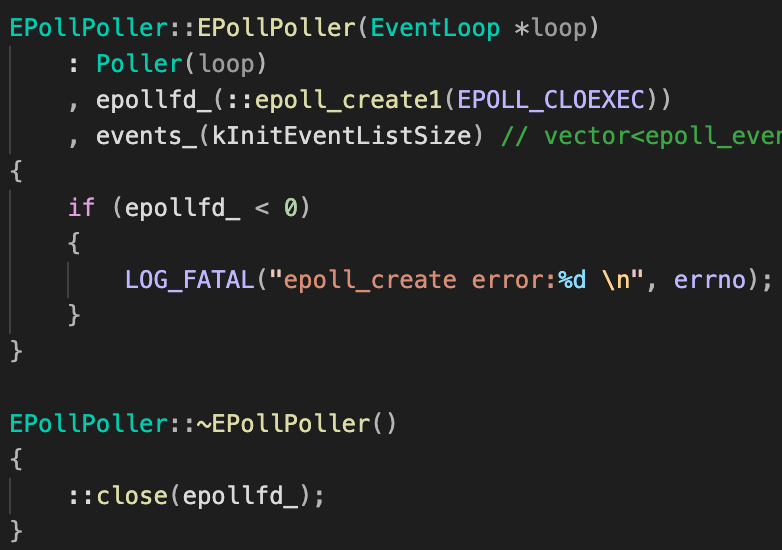 |
EventLoop类
EventLoop类进一步封装了Poller类,通过调用Poller::poll()进行I/O复用,返回活跃事件列表,然后遍历该列表,依次调用每一个活跃Channel的事件处理函数handleEvent(),而handleEvent其实就是根据事件响应类型(EPOLLIN、EPOLLOUT等),最终调用TcpConnection注册过来的回调函数。
| EventLoop类成员 | EventLoop类构造函数&析构函数 |
|---|---|
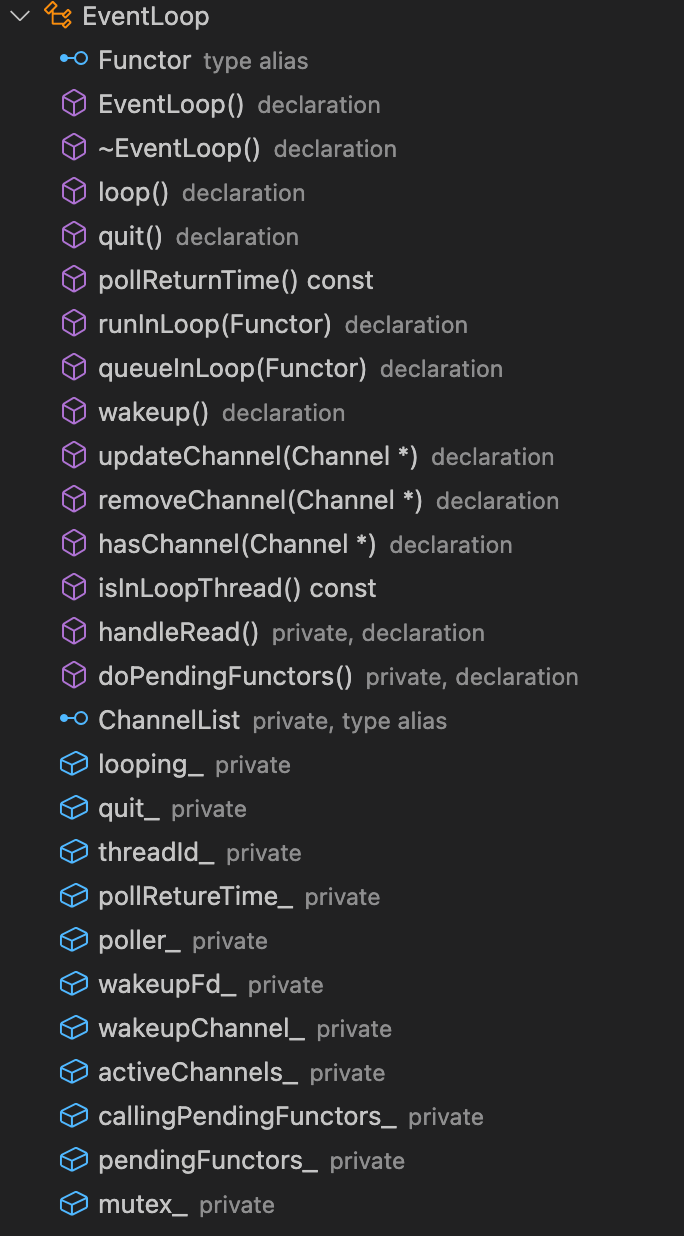 |
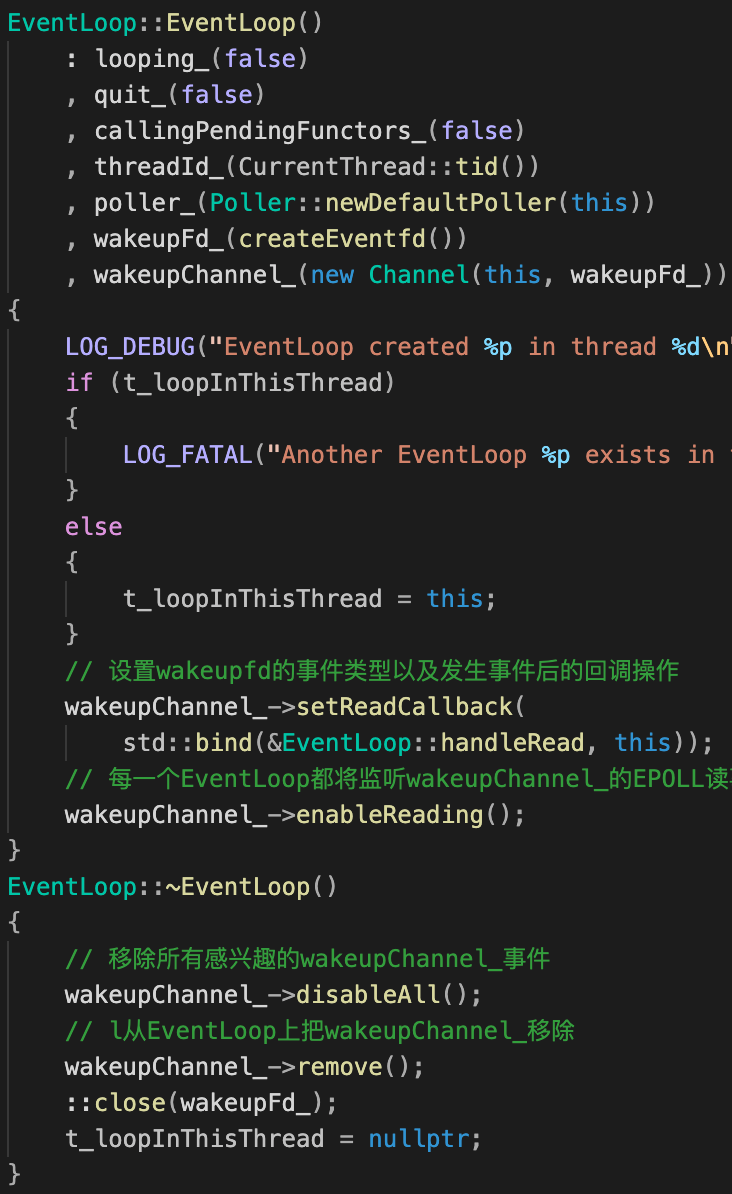 |
作为muduo的核心类,EventLoop类值得分析的地方很多。 本文将在2.1部分,串讲整个流程加深理解。
从构造函数看:wakeupFd设计与tie初识
这里,我们先来看看wakeupFd设计。
想想这么一种情况:Sub-Reactor(EventLoop)开启事件循环后,阻塞在epoll;此时如果有新连接clientfd待注册,Main-Reactor(Accpetor)如何通知Sub-Reactor?
这个时候便需要wakeupFd“唤醒”。聪明的你想到:Accpetor绑定的listenfd是通过listen()来监听客户端请求,Sub EventLoop也可以通过listen()来监听Main-Reactor请求?
⚠️ 回忆
listen():
listen()只是让套接字进入监听状态,并没有真正接收客户端请求,listen() 后面的代码会继续执行,直到遇到 accept();accept()返回一个新fd来和客户端通信,会阻塞程序执行(后面代码不能被执行),直到有新的请求到来。
但在muduo中,使用的是更高效的eventfd。注意到上表右侧EventLoop构造函数:
eventfd是linux的一个系统调用,为事件通知创建文件描述符,eventfd()创建一个“eventfd对象”,这个对象能被用户空间应用用作一个事件等待/响应机制,靠内核去响应用户空间应用事。
-
首先,创建wakeFd & wakeupChannel:
不同于常规使用socket跨线程通信,muduo使用eventfd(事件驱动更快,8字节缓存区也更省)。wakeupChannel_随后对eventfd进行封装。
1
2wakeupFd_(createEventfd())
wakeupChannel_(new Channel(this, wakeupFd_))1
2
3
4
5
6
7
8
9int createEventfd()
{
int evtfd = ::eventfd(0, EFD_NONBLOCK | EFD_CLOEXEC);
if (evtfd < 0)
{
LOG_FATAL("eventfd error:%d\n", errno);
}
return evtfd;
} -
随后wakeupChannel_设置Read回调事件
EventLoop::handleRead:注意区分后面会提到的:
Acceptor::handleRead函数。1
2wakeupChannel_->setReadCallback(
std::bind(&EventLoop::handleRead, this));很简单,
EventLoop::handleRead(this)只是有写事件(Main-Reactor为了唤醒往wakeupFd_写)时,读出数据,基本啥也没干。1
2
3
4
5void EventLoop::handleRead() // 删除read判错逻辑
{
uint64_t one = 1;
ssize_t n = read(wakeupFd_, &one, sizeof(one));
} -
Sub-Reactor(EventLopp)注册wakeFd事件开始监听:
Channel::enableReading()核心逻辑是,注册fd事件到当前调用Channel所绑定的EventLoop的epoll上。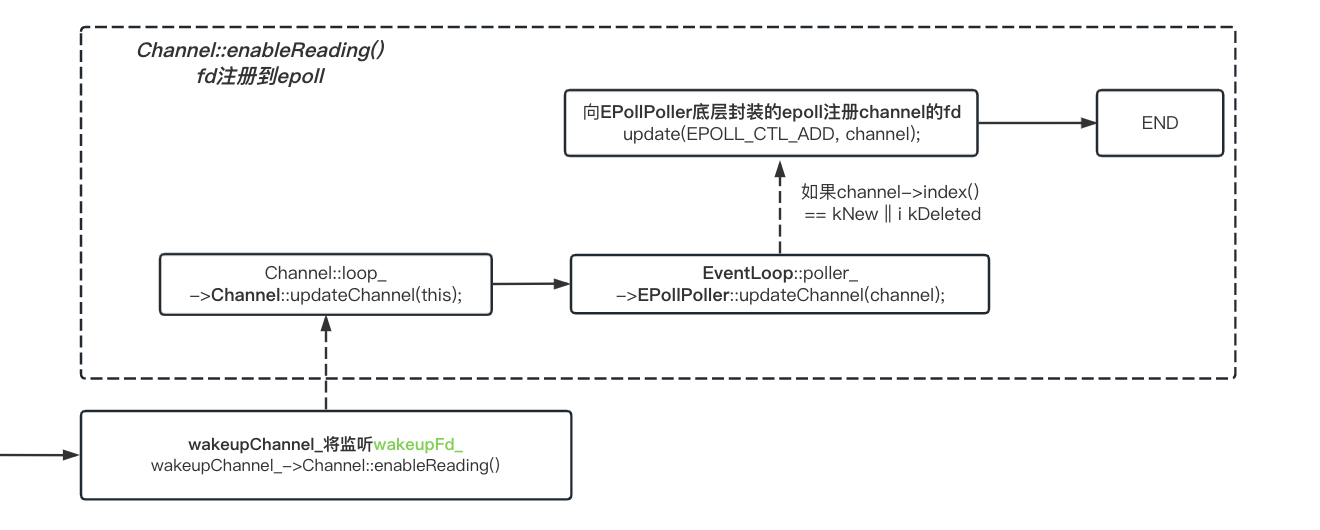
1
wakeupChannel_->enableReading();
这样Main-Reactor需要唤醒Sub-Reactor时:
-
将新连接建立的回调事件(TcpConnection::connectEstablished,),压入Sub-Reactor的回调队列 ;
1
2
3
4
5
6
7/*in TcpServer.cc*/
void TcpServer::newConnection(int sockfd, const InetAddress &peerAddr)
{
// .... 省略
ioLoop->EventLoop::runInLoop
(std::bind(&TcpConnection::connectEstablished, conn));
} -
只需简单
wakeup(), Sub-Reactor便不再阻塞在epoll;1
2
3
4
5
6// 用来唤醒loop所在线程 向wakeupFd_写一个数据 wakeupChannel就发生读事件 当前loop线程就会被唤醒
void EventLoop::wakeup()// 删除write判错逻辑
{
uint64_t one = 1;
ssize_t n = write(wakeupFd_, &one, sizeof(one));
} -
随后Sub-Reactor被唤醒,遍历处理队列中的回调事件。
TcpConnection::connectEstablished 做了什么?
不难分析中,当新连接到来时,我们至少需要它可以完成以下工作:
- 我们需要新连接的clientfd注册到Sub-Reactor,进行后续监听;
- 我们需要执行用户自定义的连接回调;
- …
其实现便呼吁而出:
1 | // 连接建立 |
但这里出现了一个奇怪的东西:tie 这是什么?
简单来说,tie避免了这么一种情况:
- Channel所属的TcpConnection对象(简称
T)已经不存在,但Channel还在处理clientfd回调事件&调用Channel的回调方法; - 而且Channel回调方法里又往往调用了
T的方法成员,如send()等处理数据收发; - 最后,调用不存在的对象
T导致程序崩溃。
在后面的EventLoop::loop()介绍中,我们还会详细解释分析tie调用流程。
析构函数
EventLoop析构函数负责:
- ①epoll上移除wakeupChannel_相关事件;
- ②移除从epoll上把wakeupChannel_所管理的fd;
- ③调用系统函数关闭fd。
loop() 函数
loop() 函数用来开启事件循环,说人话便是:
- 启动底层epoll_wait监听感兴趣事件 ;
- 感兴趣事件处理,如:①for循环处理可读、可写、错误等事件;②doPendingFunctors函数处理回调队列中的事件。
1 | // 开启事件循环 |
这个函数有两个地方值得注意:
Channel::handleEvent实现逻辑,特别是其中tie相关逻辑;EventLoop::doPendingFunctors()实现逻辑,特别是其中的线程同步加锁逻辑。
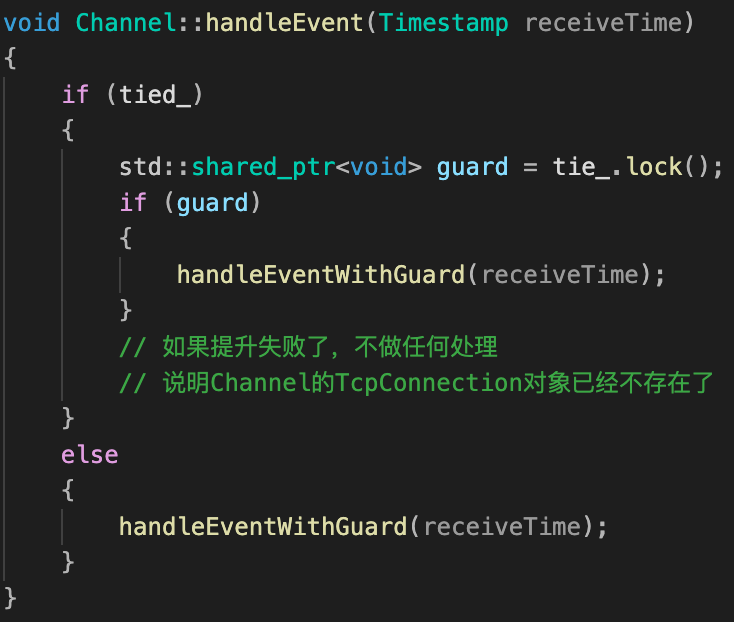
Channel::handleEvent实现
Channel::handleEventWithGuard 作用:当epoll返回可读、可写、错误等事件,去调用TcpConnetion类给Channel设置的回调函数进行处理。
这里又出现了那个奇怪的tie ?
| Channel::handleEvent | Channel::handleEventWithGuard |
|---|---|
 |
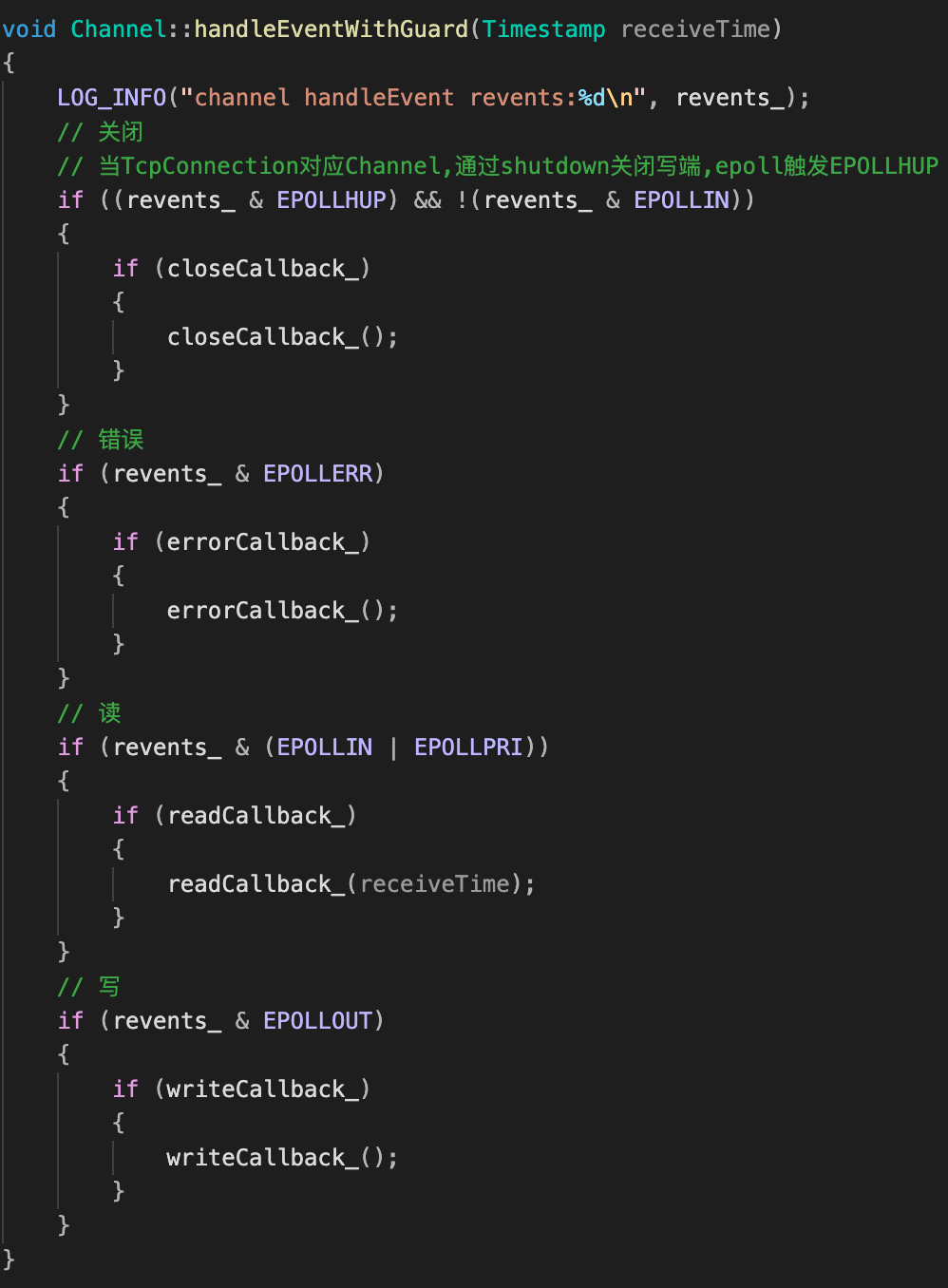 |
tie深入理解
前面简单提到:
tie避免了这么一种情况:
- Channel所属的TcpConnection对象(简称
T)已经不存在,但Channel还在处理clientfd回调事件&调用Channel的回调方法;- 而且Channel回调方法里又往往调用了
T的方法成员,如send()等处理数据收发;- 最后,调用不存在的对象
T导致程序崩溃。
所以,我们需要tie:保证先让Channel回调函数先把数据发送完,再释放TcpConnection对象的资源。
整个过程复盘如下:
-
如前提到,Main-Reactor需要唤醒Sub-Reactor时,首先会将新连接回调事件(TcpConnection::connectEstablished,),压入Sub-Reactor的回调队列 ;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20/*in TcpServer.cc*/
void TcpServer::newConnection(int sockfd, const InetAddress &peerAddr)
{
// .... 省略
ioLoop->EventLoop::runInLoop
(std::bind(&TcpConnection::connectEstablished, conn));
}
/*in TcpConnection.cc*/
void TcpConnection::connectEstablished()
{
setState(kConnected);
// 1.解决TcpConnection对象已经不存在了,还能感知到Poller的通知并调用Channel的回调方法的问题
channel_->tie(shared_from_this());
// 2.向poller注册channel的EPOLLIN读事件
channel_->enableReading();
// 3.新连接建立:执行用户自定义的回调
// TcpConnection::connectionCallback==EchoServer::onConnection
connectionCallback_(shared_from_this());
}此时是在
TcpConnection对象T中,shared_from_this()返回的是shared_ptr指针指向T。Channel::tie使用weak_ptr 即tie_绑定了T:1
2
3
4
5
6
7std::weak_ptr<void> tie_;
/***** Channel.cc ******/
void Channel::tie(const shared_ptr<void>& obj)
{
tie_ = obj;
tied_ = true;
} -
这样,如果epoll监听事件触发,执行
Channel::HandlerEvent:1
2
3
4
5if(tied_){
shared_ptr<void> guard = tie_.lock();
if (guard)
HandleEventWithGuard(receiveTime);
}-
首先判断一下当前Channel是否生命绑定了一个TcpConnection对象(貌似是一定成立的?) ;
-
然后重头戏,使用
tie_.lock()将tie_这个weak_ptr提升→shared_ptr ,该shared_ptr执行TcpConnection对象;参考here:weak_ptr不改变shared_ptr实例的引用计数,可能存在weak_ptr指向的对象被释放掉这种情况,如何判断weak_ptr指向对象是否存在呢?C++中提供了lock
()来实现该功能。如果对象存在,lock()函数返回一个指向共享对象的shared_ptr(引用计数会增1),否则返回一个空shared_ptr。
-
如果
guard不为null,则说明共享的TcpConnection对象还存在,可以放心地继续往下执行Channel::handleEventWithGuard;否则不做处理。
-
至此,tie的作用便已了然于胸:保证在Channel对象执行回调时,TcpConnection对象一定存在。
doPendingFunctors() :结合runInLoop()理解回调队列中的多线程同步
如前提到,在事件循环loop()中,epoll被触发时,需执行两类事件:
- 处理事件1:遍历处理响应的EPOLLIN、EPOLLOUT等事件,这类事件处理基本是用户自定义业务回调函数处理;
- 处理事件2:遍历执行回调队列中的回调事件(函数),如框架中预定义的TcpConnection::shutdownInLoop、TcpConnection::connectEstablished() 等。
第2类事件处理,便在doPendingFunctors()中实现。其中的多线程设计难点,要结合runInLoop()函数理解:
| EventLoop::runInLoop() | EventLoop::doPendingFunctors() |
|---|---|
 |
 |
-
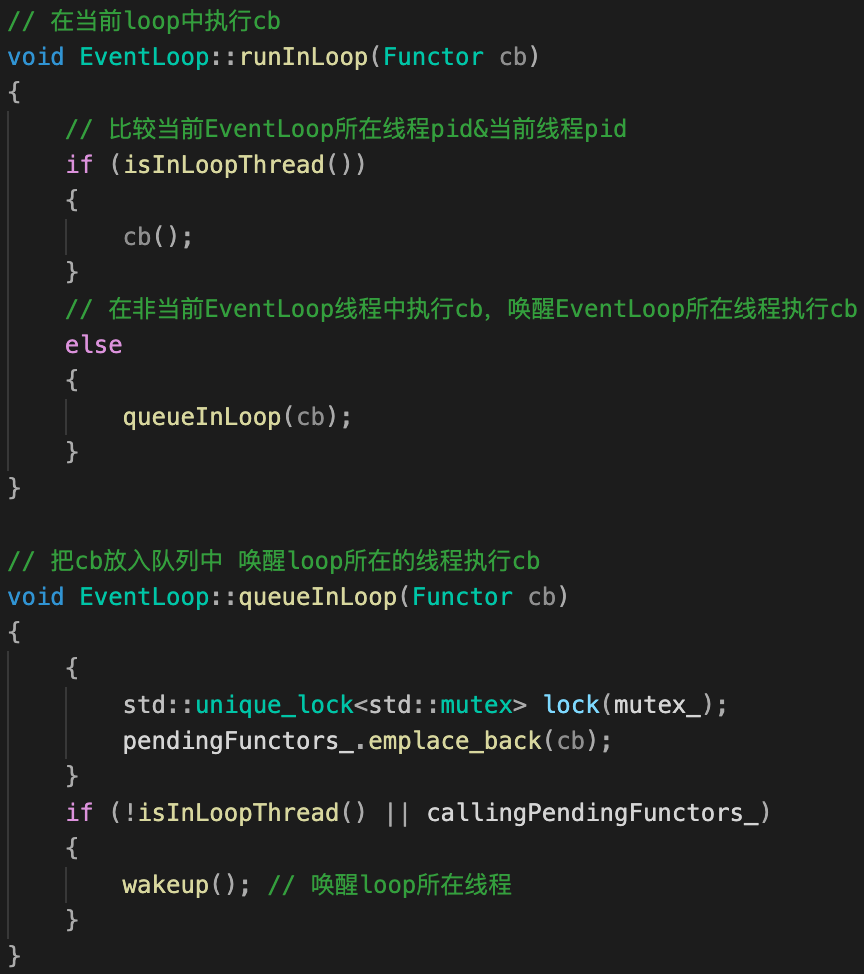
runInLoop(cb)函数功能:负责唤醒调用其所属EventLoop对象所在的线程,并执行回调事件cb。
-
如果TA≠TB,触发新事件时,某个EventLoop对象EA(所属线程TA),唤醒(不再阻塞在epoll)&调用另外某个EventLoop对象EB(所属线程TB)的函数
runInLoop(cb),将回调cb加入到回调队列pendingFunctors_;比如,新连接到来时,main loop(所属线程TA)调用sub loop(所属线程TB)
runInLoop(TcpConnection::connectEstablished)。 -
如果TA=TB,则立即执行回调事件
cb(),走到这里说明线程没有处理其它事(比如正在处理回调队列),因此直接执行即可。
-
-
doPendingFunctors()函数功能:在某个EventLoop对象,例如为上述EB,处理回调队列
pendingFunctors_中的函数 。
当TA≠TB,存在两个多线程同步问题:
-
线程TA,如何保证将回调事件注册EventLoop对象 EB上时,去唤醒TB执行?EB属于线程TB;
-
EventLoop对象EB所属线程TB已经被唤醒,且正在处理
pendingFunctors_;此时TA又要将新回调cb加入pendingFunctors_,该如何用锁优雅处理pendingFunctors_的多线程竞争?- 不过这里有个疑问:这里是典型1消费者N生产者模型,即有多个生产线程可能往
pendingFunctors_加入cb回调,当前EventLoop对象所在线程消费执行cb回调。虽然pendingFunctors_会被多个线程改变状态,但是生产者线程之间各自加入自己回调不需要状态同步,各自加入回调即可;消费者遍历pendingFunctors_回调队列时,虽然队列状态不一定准确,比如判断已经遍历到队尾时但恰好又有新cb加入,等待下次再处理即可?
我猜测原因应该是pendingFunctors_是Vector类型,而Vector是线程非安全的,所以其实还是需要状态同步。
- 例如,多个生产者线程之间向pendingFunctors_.emplace_back(cb)加入回调其实是需要状态同步的。因为pendingFunctors_是vector数组,vector数组插入非线程安全,且存在自动扩容机制。比如线程a插入触发扩容数组的内存重新分配,线程b又恰好插入,可能会引起意料之外的内存错误。
- 又如,单个消费者线程消费cb,erase后虽然vector不会自动缩容,但是考虑线程安全还是加锁?高手看不透啊。
- 不过这里有个疑问:这里是典型1消费者N生产者模型,即有多个生产线程可能往
对于问题1:线程TA,如何保证将回调事件注册EventLoop对象 EB上时,去唤醒TB执行?
muduo给出的答案是:
- EventLoop对象只运行在一个Thread上,并在对象初始化时使用
threadId_字段记录该Thread的pid; - 在注册回调时,通过
isInLoopThread()函数比较调用EB线程的pid 和threadId_字段,如果一样则直接执行; - 如果不一样,调用EB的wakeup(),唤醒其属Thread TB即可。
对于问题2:如何优雅用锁处理
pendingFunctors_的多线程竞争?
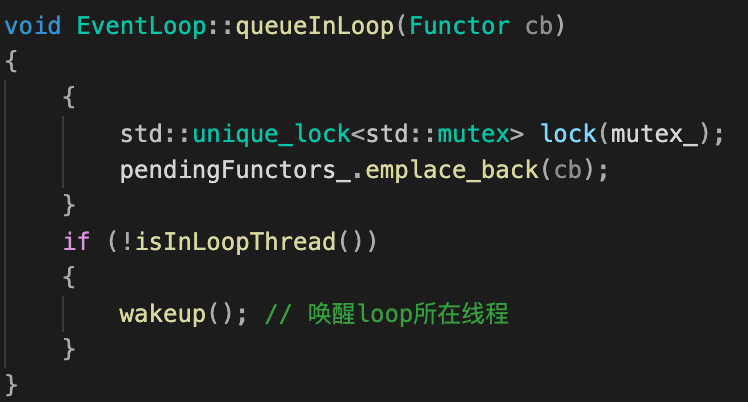
设置互斥锁mutex_来处理,暂时忘记muduo,下面看似更简单一点实现有什么问题?
| EventLoop::queueInLoop() : 基本无改动 | EventLoop::doPendingFunctors():第一次实现 |
|---|---|
 |
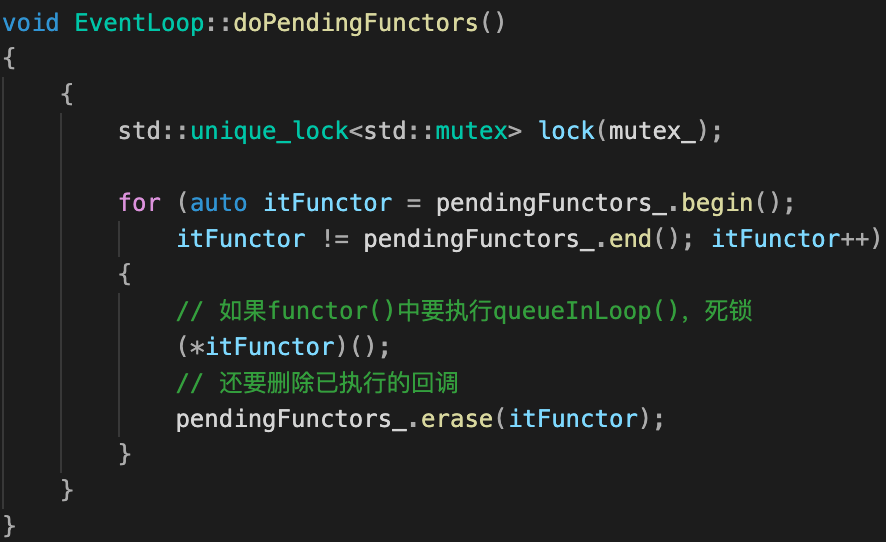 |
-
锁范围增大,性能降低:只有等回调队列函数全部执行完才释放锁,在此期间queueInLoop将不可用;
-
死锁风险:
doPendingFunctors拿到锁—>queueInLoop等待doPendingFunctors释放锁—>doPendingFunctors执行的回调恰好也要执行queueInLoop—>doPendingFunctors等待queueInLoop执行 —>死锁。
聪明的你想到:如前述,我们加锁主要是考虑Vector类型回调队列多线程操作(插入、删除等)安全;但消费线程(EventLoop对象)执行cb()时,里面的回调函数完全是可以独立执行的。如果将队列中回调函数放到临时队列,遍历临时队列执行回调就可以释放锁了(队列相关操作完成)。不但缩小锁范围了,同时还避免了死锁!
因此,我们写出第2版代码:
| EventLoop::queueInLoop() : 基本无改动 | EventLoop::doPendingFunctors():修改锁范围 |
|---|---|
|
 |
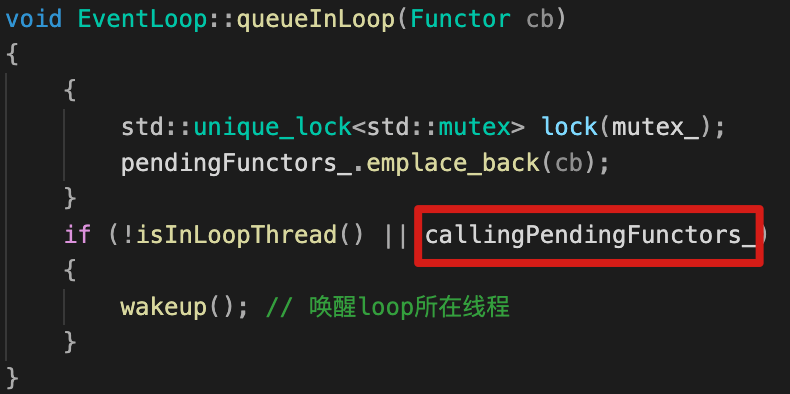
不过我们依旧可以做一个小改进:
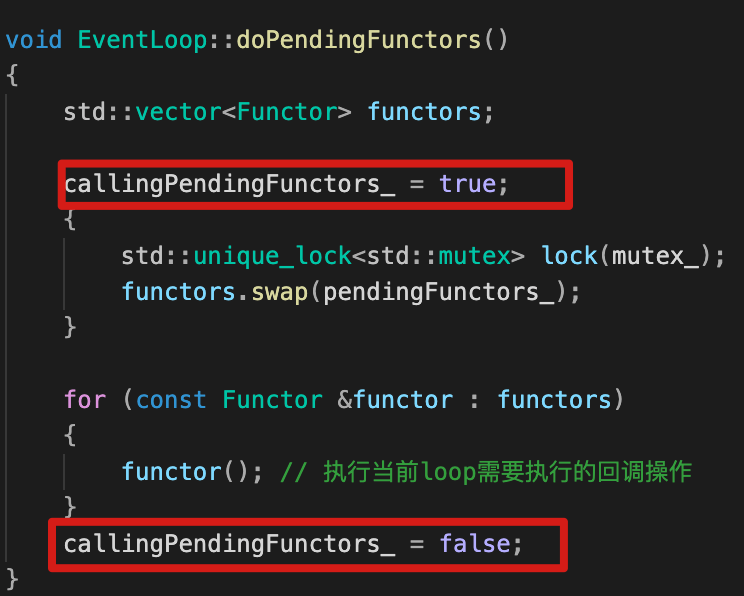
- 使用callingPendingFunctors_记录(右栏)EventLoop对象所在线程T是否已经遍历执行完回调队列中的函数;
- 如果EventLoop对象所在线程在执行回调,新回调cb加入应该要随着队列中的回调一起执行完(属于时间段的事件),这样当
callingPendingFunctors_=true,唤醒EventLoop对象所在线程, 让执行完doPendingFunctors进入到下一次poller_->poll()也不阻塞,会再依次执行doPendingFunctors处理新cb。
最后muduo代码实现为:
这里还有个小疑问:
- 为什么这个callingPendingFunctors_变量没有用原子?外面有线程会来读这个变量,内部本身的io线程会修改这个变量,感觉需要保证这个变量的原子性?
| EventLoop::queueInLoop() | EventLoop::doPendingFunctors():增加执行状态字段 |
|---|---|
 |
 |
EventLoopThread类
都说EventLoop是one loop per thread,其秘密便藏在EventLoopThread类中。
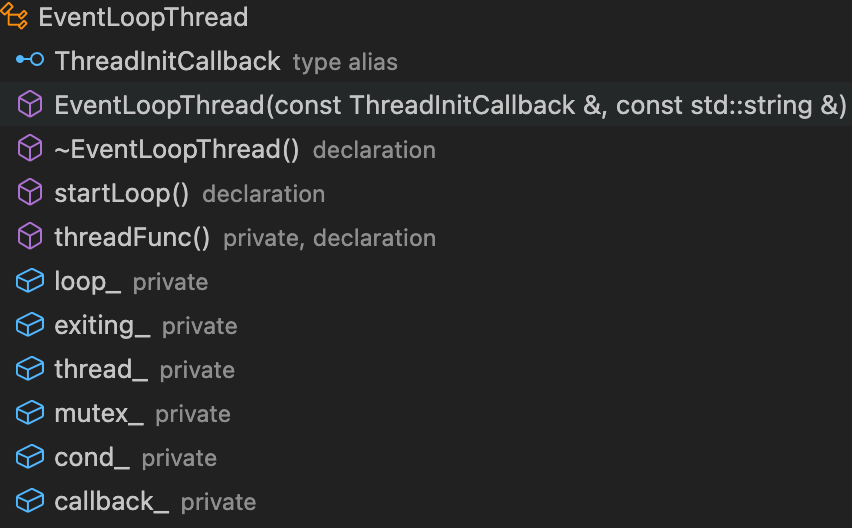
先来看看EventLoopThread类主要职能:
- 负责管理一个线程;
- 一个线程对应创建一个EventLoop对象,且调用
EventLoop::loop()。
| EventLoopThread类成员 | EventLoopThread类构造&析构函数 |
|---|---|
 |
 |
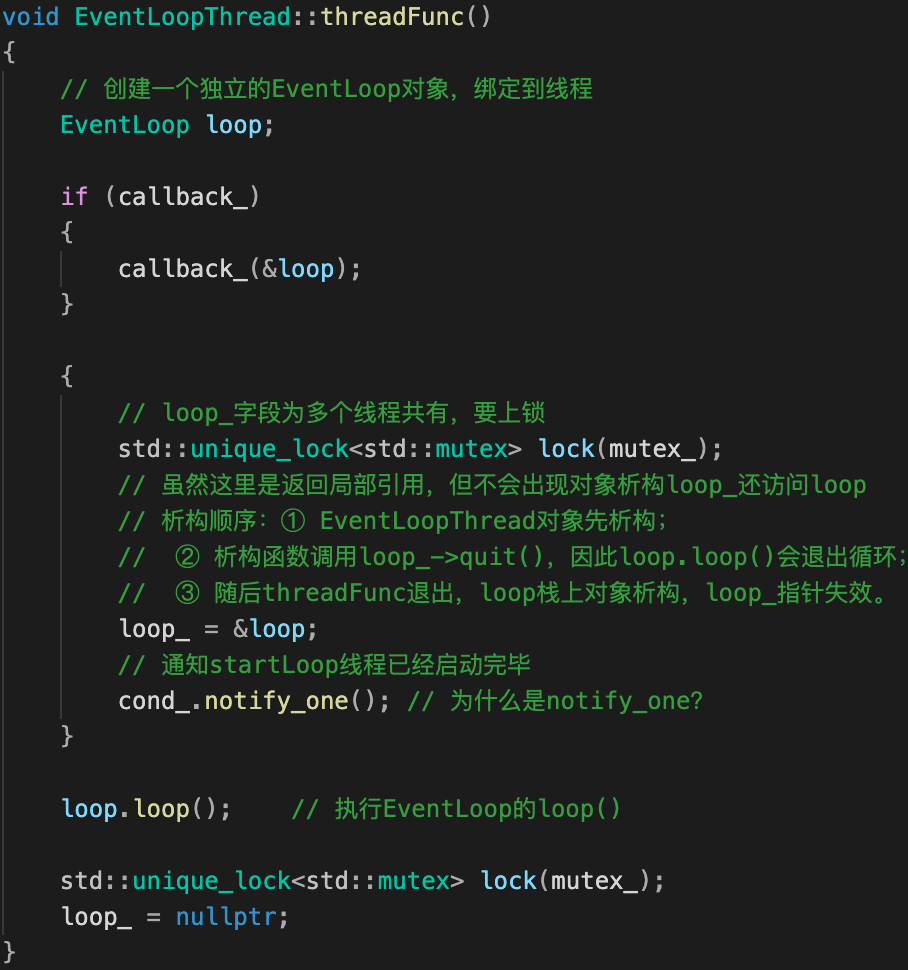
EventLoopThread函数很少,我们重点关注:构造&析构函数、startLoop()、threadFunc() 函数。
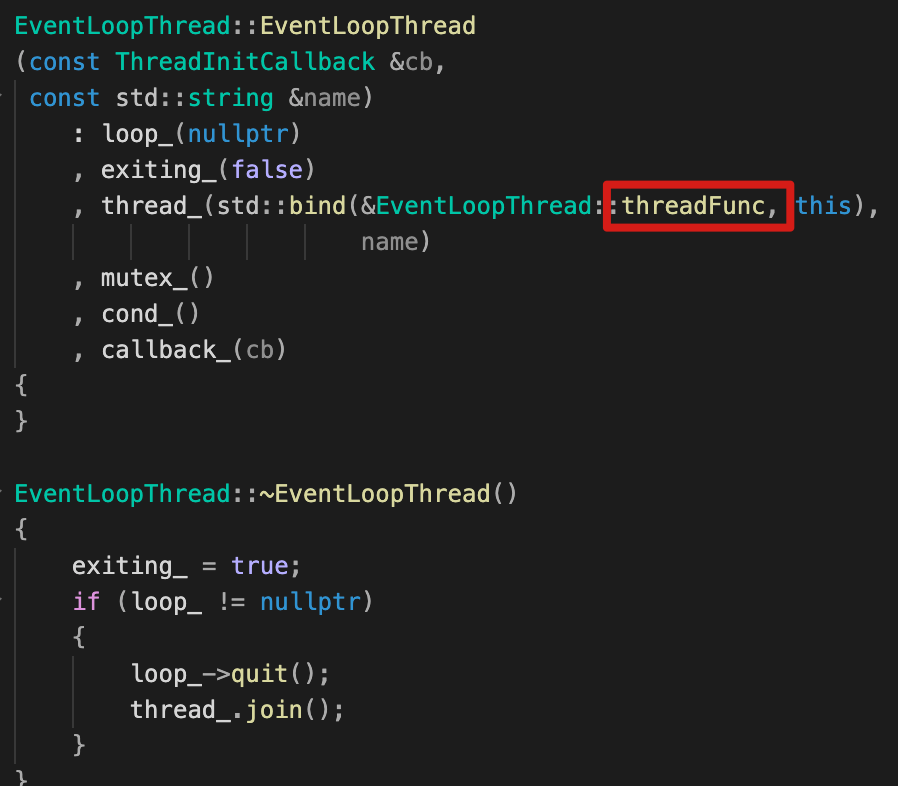
构造函数 & 析构函数
-
构造函数:可以看到,
thread_绑定了EventLoopThread::threadFunc函数; -
析构函数:如果
loop_不为null,说明线程绑定的EventLoopThread对象loop_还未析构,线程thread_也未退出:-
首先退出事件循环,loop_->quit()
1
2
3
4
5
6
7
8
9
10
11
12void EventLoop::quit()
{
// 设置quit_=true使得loop()函数:while(!quit_){ epoll_wait()..} ,退出事件while循环
quit_ = true;
// 但是还可能出现:在其它EventLoop对象中,调用了当前EventLoop对象quit()
// 比如:在subloop(worker)中调用mainloop(IO)的quit时,需要唤醒mainloop(IO)执行完loop()函数。
// p.s. 不太理解这种情况,而且搜了全量代码,也只有在析构才会调用quit()?
if (!isInLoopThread())
{
wakeup(); // 当前EventLoop对象被唤醒,由于quit_ = true当前对象loop退出。
}
} -
线程退出:thread_.join()
保证线程执行完,然后退出。
-
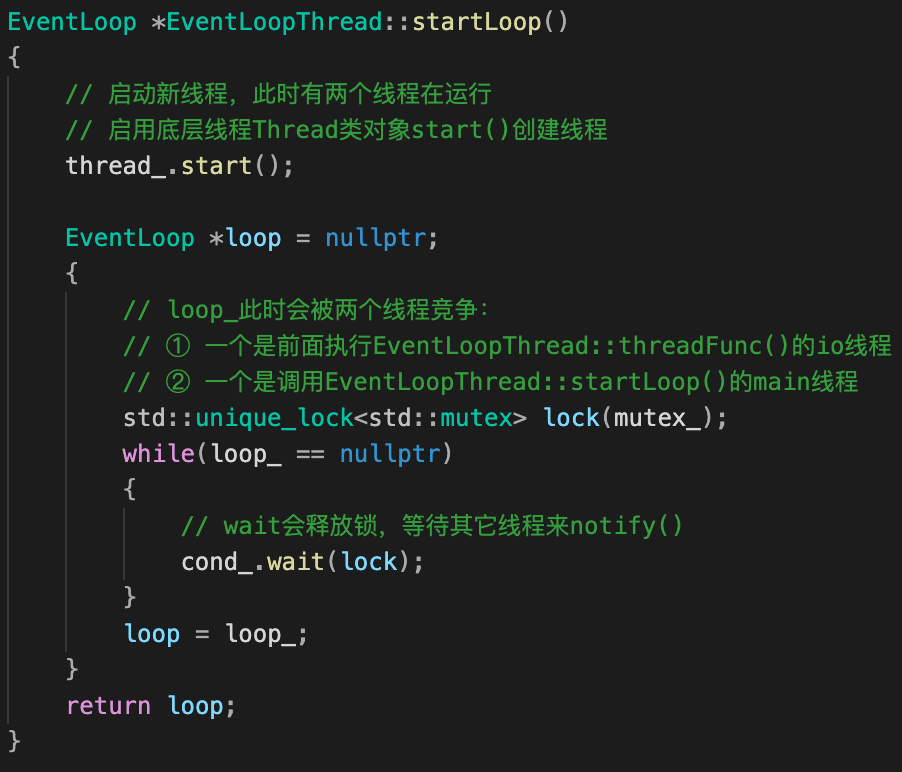
startLoop() & threadFunc()
startLoop()用来创建sub loop并启动事件循环loop()。
startLoop()比较难理解的是其锁逻辑,这里首先需要明白:为什么loop_要上锁?
- 在main线程中(主逻辑)启动线程池TcpServer::start()函数时,线程池EventThreadPool会创建N个EventLoopThread对象;所以,EventLoopThread::startLoop()是在main线程中被调用的,但main线程不负责具体的 sub loop(loop_)创建,会wait其它线程将sub loop创建完成。
- EventLoopThread::startLoop()还会启动一个io线程(绑定了
threadFunc函数),io线程会执行threadFunc去创建sub loop(loop_),通知main线程。
可知,loop_对上述两个线程都是可见的,需要上锁。
| startLoop() | threadFunc() |
|---|---|
 |
 |
给loop_ 上锁代码,是经典的:条件变量+while{wait}+notify逻辑:
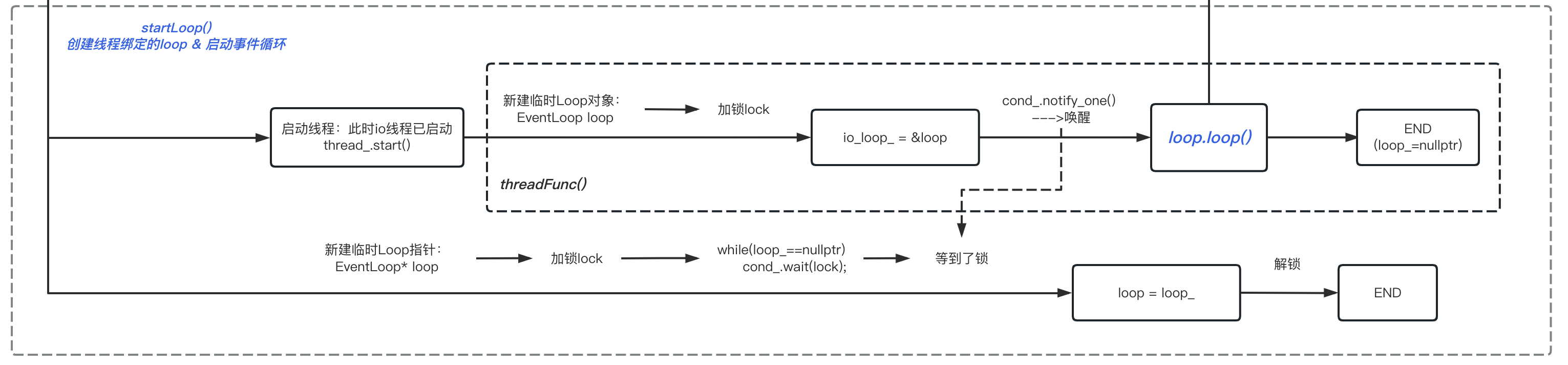
- main线程,while循环+条件变量等待解锁;
- io 线程,创建完成EventLoop对象后,使用notify唤醒main线程;
- main线程返回创建好的EventLoop对象。
TcpConnection类
如前所述,TcpConnection类职能如下:
…
- Sub-Reactor 向其底层封装的epoll注册clientfd ;
- 同时,对于每个新连接,其实是通过分配一个TcpConnection类对象处理:
new一个Channle对象封装clientfd,并向Channle注册回调事件(可读、可写、可关闭、错误处理);
封装底层InputBuffer和OutputBuffer,用来进行数据收发。
不难发现,TcpConnection用于sub loop中处理新连接,对connfd封装以及数据收发。
- 注,TcpConnection类析构函数为空,因此这里省略。
| TcpConnection类 | TcpConnection类构造函数 |
|---|---|
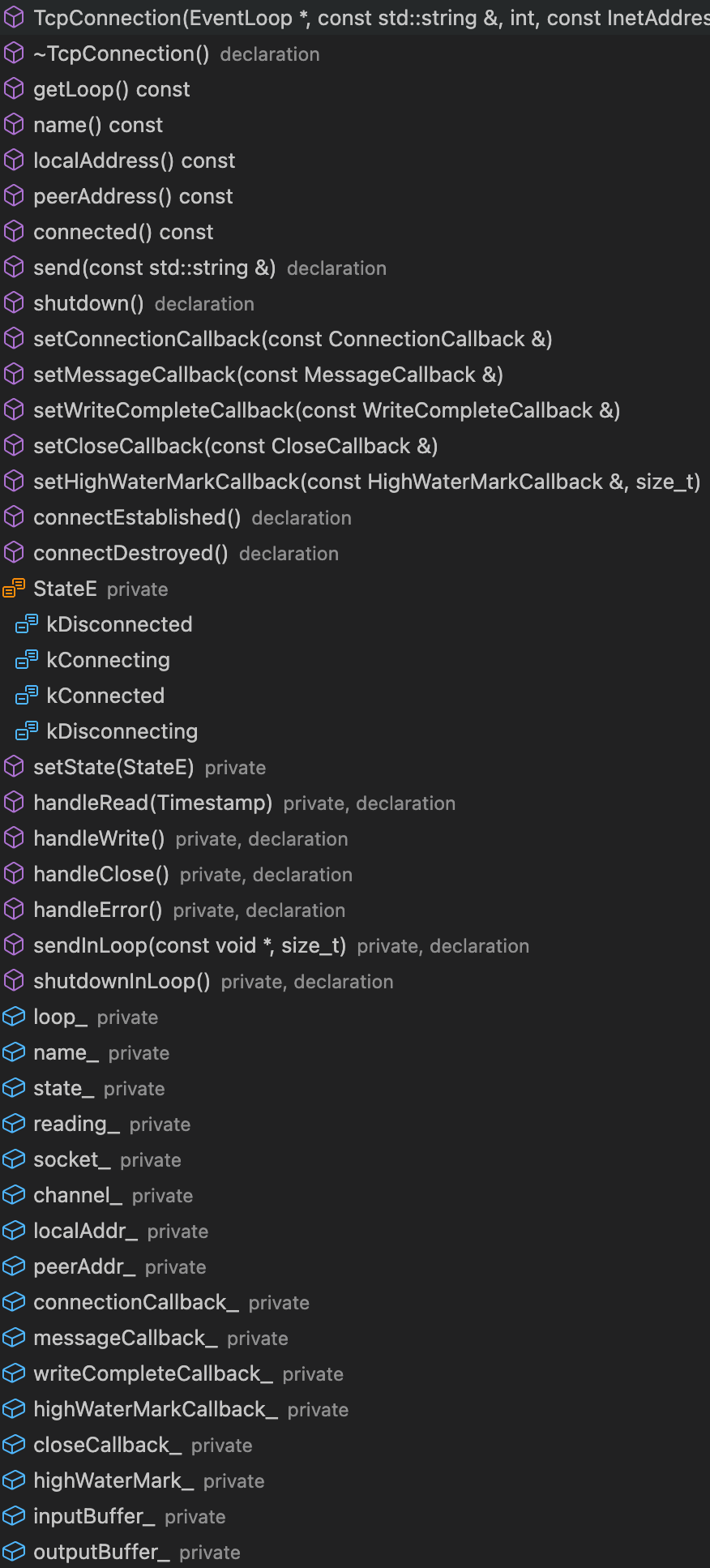 |
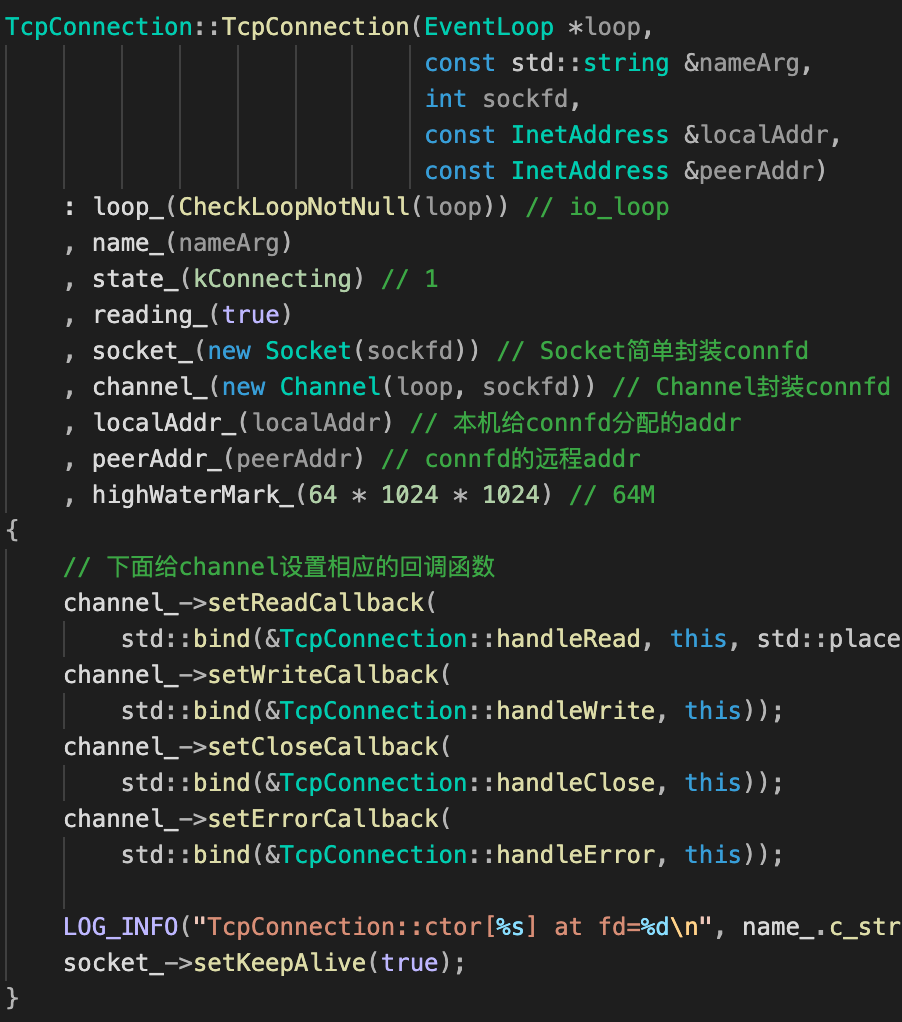 |
TcpConnection对象上游调用链
在前面我们说过:对于每个新连接,Accpetor分配新连接给sub loop时,会创建一个新TcpConnection对象。
那么在muduo代码中,TcpConnection对象生成的具体时机(调用链)?
-
生成时机:main loop 有新连接 —>
Acceptor::handleRead(Acceptor初始化时注册该回调)—>TcpServer::newConnection: -
核心代码示例
1
// 1. accepChannel_上listenfd可读(epoll返回)-->执行readCallback_-->即Acceptor::handleRead()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 2. Acceptor::handleRead()处理新连接
void Acceptor::handleRead()
{
InetAddress peerAddr;
// 调用accpet4返回client_fd(connfd)&相应地址(peerAddr)
int connfd = acceptSocket_.accept(&peerAddr);
if (connfd >= 0)
{
if (NewConnectionCallback_)
// 绑定为:TcpServer::newConnection
NewConnectionCallback_(connfd, peerAddr);
else
::close(connfd);
}
...
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23// 3. TcpServer::newConnection:轮询找到subLoop 唤醒并分发当前的新客户端的Channel
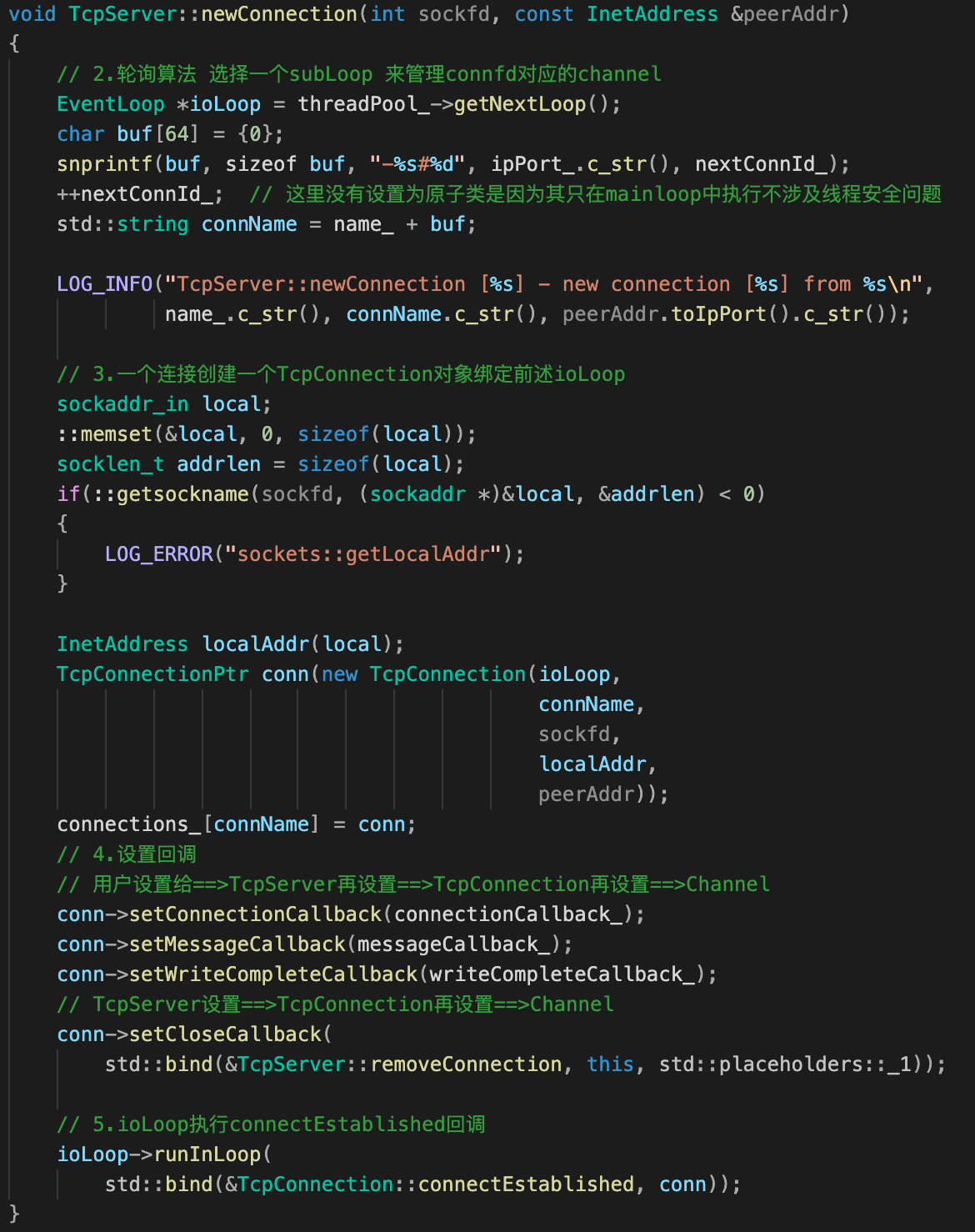
void TcpServer::newConnection(int sockfd, const InetAddress &peerAddr)
{
// 3.1 轮询算法 选择一个subLoop 来管理connfd对应的channel
EventLoop *ioLoop = threadPool_->getNextLoop();
...
...
// 3.2 创建TcpConnection对象!
TcpConnectionPtr conn(new TcpConnection(ioLoop,
connName,
sockfd,
localAddr,
peerAddr));
connections_[connName] = conn;
// 3.3 TcpServer 设置回调给=> TcpConnection的
conn->setConnectionCallback(connectionCallback_);
conn->setMessageCallback(messageCallback_);
conn->setWriteCompleteCallback(writeCompleteCallback_);
conn->setCloseCallback(std::bind(&TcpServer::removeConnection, this, std::placeholders::_1));
// 3.4 io loop(sub loop)执行回调connectEstablished
ioLoop->runInLoop(
std::bind(&TcpConnection::connectEstablished, conn));
}
构造函数:muduo中的回调注册链
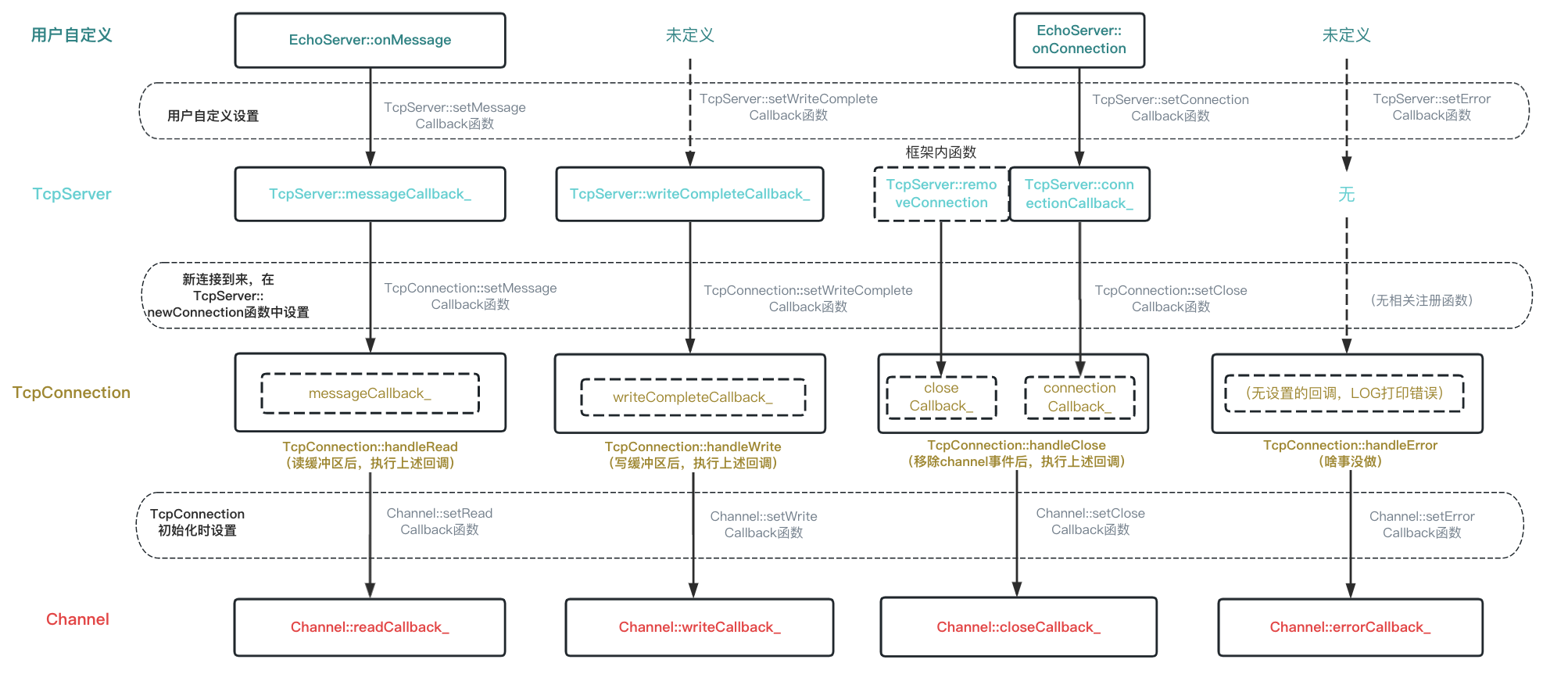
注意到,TcpConnection在构造函数体内还给其绑定的channel_注册了四个读、写、关闭、错误回调。那handleRead、handleWrite、handleClose、handleError又是什么时候被注册?
一图看明白muduo中Channel类关键回调注册链:
TcpServer 还没正式介绍过,其主要封装了Accpetor & EventThreadPool ,是提供给用户的接口类。如:
- 启动服务器
start()方法,启动线程池&创建线程&main loop开启事件循环; - 上述给用户注册自定义回调的
TcpServer::setConnectionCallback、TcpServer::setMessageCallback等方法。
谈谈数据收发
前面提到TcpConnection第二个职能:封装底层InputBuffer和OutputBuffer,用来进行数据收发。
所谓InputBuffer和OutputBuffer都是Buff类对象:
1 | // 数据缓冲区 |
下一节我们进行具体介绍。
Buff类
Buffer类封装了一个vector数组,以及向这个缓冲区数组读、写数据等一系列控制方法。
Buff类底层数据结构
Buff类底层数据结构是个vector数组buffer_,结合两个读writerIndex_、写readerIndex_索引:
1 | std::vector<char> buffer_; |
Buff类关键函数
关键函数:
append(const char* data, size_t len),将data数据添加到缓冲区中;retrieveAllString(),获取缓冲区所有数据,并以string返回;ensureWritableByts(size_t len),当你打算向缓冲区写入长度为len的数据之前,先调用这个函数,这个函数会检查你的缓冲区可写空间能不能装下长度为len的数据,如果不能,就动态扩容。
下面两个方法主要是封装了调用了上面几个方法:
ssize_t Buffer::readFd(int fd, int* saveErrno):客户端发来数据,readFd从该TCP接收缓冲区中将数据读出来==>Buffer中;操作过程参考上图。ssize_t Buffer::writeFd(int fd, int* saveErrno):服务端要向这条TCP连接发送数据,通过该方法将Buffer中的数据拷贝==>到TCP发送缓冲区outputBuffer_中;操作过程参考上图。
Buff类这里浅浅提下,其核心设计精髓要结合TcpConnection::send & TcpConnection::handRead 一起理解。在2.3、2.4复盘有详细分析。
Channel类
Channel类主要是对描述符fd和感兴趣的事件events封装,一个Channel只属于一个EventLoop。
为啥Channel_类析构函数为空?似乎将所封装的fd移除注册的事件 & 移除channelMap比较好?
这部分代码放到EventLoop 和 Accpetor析构函数,可能是因为:①一个Channel属于一个EventLoop;②Channel的析构动作由其所属的Reactor负责比较好?保证先析构Channel?
| Channel类成员 | Channel类构造函数 |
|---|---|
 |
 |
理解Channel类,关键在于理解:
- Channel类回调函数是如何被注册的?什么时候执行?第1个问题再TcpConnection类中已介绍。
tie_&tied字段作用?第2个问题在EventLoop类中也已介绍。
因此,这里不再赘述。
1.3.2 Main Reactor:Acceptor、EventThreadPool
Acceptor类
在前面,我们已大致清楚Acceptor职能:
- 封装listenfd:初始化时会创建
acceptChannel_封装listenfd; - 处理&分配新连接:通过
acceptChannel_的读回调(具体是Acceptor::handleRead函数)。
显然,Acceptor最重要的就是Acceptor::handleRead 方法。
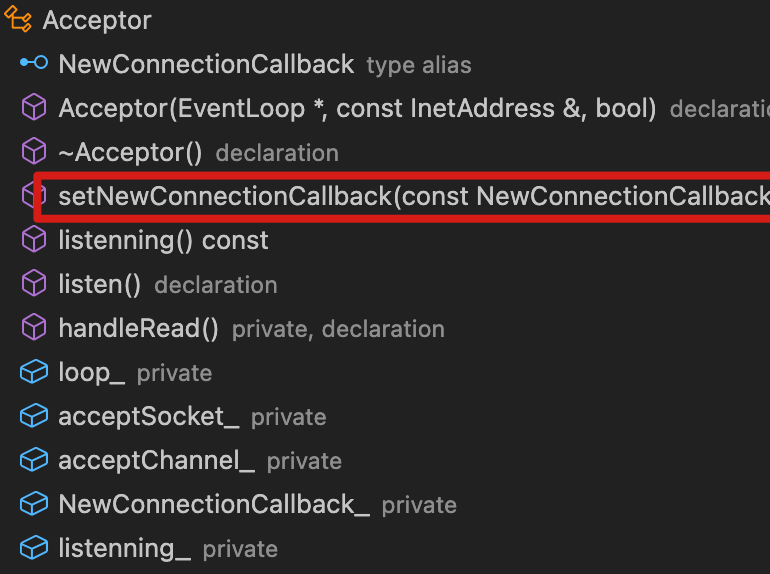
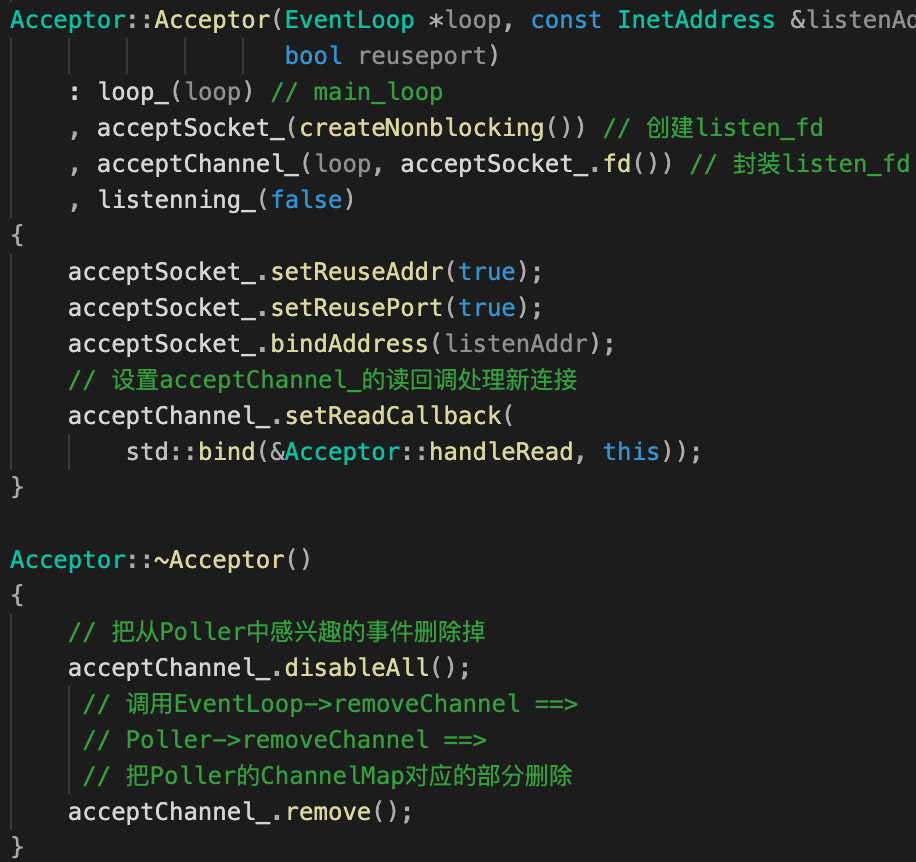
构造函数和析构函数
| Acceptor类成员 | Acceptor类构造&析构函数 |
|---|---|
 |
 |
-
构造函数
主要就做了两件事:
- 创建listenfd–>bind() --> acceptChannel封装listenfd;
- 设置了acceptChannel的读回调
Acceptor::handleRead。
-
析构函数
类似Sub-Reactor(sub loop)会将其绑定的
wakeupChannel_:- 感兴趣的事件移除;
- 从chanenlMap上移除。
Accpetor其绑定的
acceptChanne_也做了上述处理。
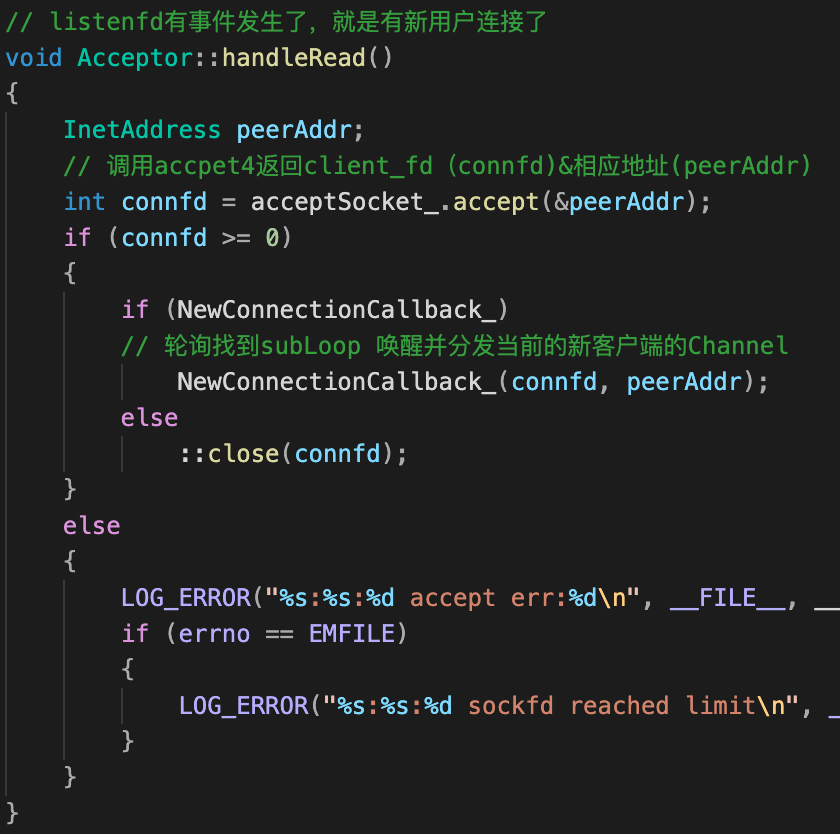
Acceptor::handleRead 函数
handleRead进行处理&分配新连接,具体来说:
| Acceptor::handleRead | TcpServer::newConnection |
|---|---|
 |
 |
-
接受新连接;
-
轮询算法选择一个sub loop;
-
new TcpConnection对象绑定该sub loop;
-
设置TcpConnection的连接、读、写、关闭回调;
-
sub loop执行connectEstablished回调:①设置
tie(深入理解可以参考)②acceptChanne_绑定的listenfd开始listen() ③执行用户自定义连接回调。1
2
3
4
5
6
7
8
9
10
11
12
13void TcpConnection::connectEstablished()
{
setState(kConnected);
// 1.防止当channel被手动remove掉 channel还在执行回调操作
// shared_from_this()==指向对象this指针的有效shared_ptr
channel_->tie(shared_from_this());
// 2.向poller注册channel的EPOLLIN读事件
channel_->enableReading();
// 3.新连接建立:执行用户自定义的回调
// TcpConnection::connectionCallback==EchoServer::onConnection
connectionCallback_(shared_from_this());
}
至此,Accpetor核心功能便已经分析完成。
EventThreadPool类
在前面EventThread类介绍中,我们曾简单提过EventThreadPool的职能:
线程池EventThreadPool会创建N个EventLoopThread对象 。
更具体点,EventThreadPool类:
- 负责在
构造函数,初始化main loop、线程数等字段; - 负责在
start()函数,创建N个EventLoopThread对象==>N个EventLoopThread对象对应启动N个thread_==>N个thread_创建对应创建N个EventLoop对象并开启事件循环loop(); - 负责在
getNextLoop()实现sub loop的分发(具体调用是在Accpetor); - …
需要重点关注的便是 start()创建线程池对象逻辑 。
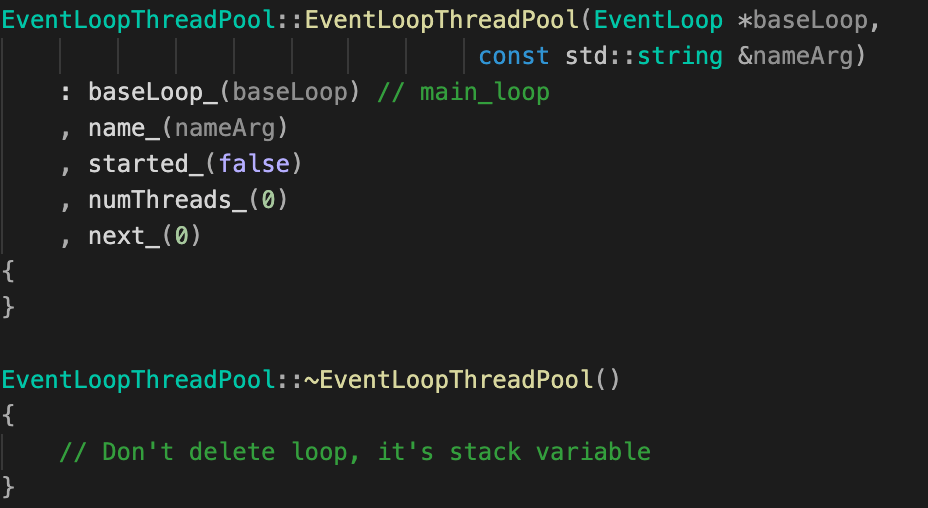
构造函数&析构函数
| EventLoopThreadPool类成员 | EventLoopThreadPool类构造&析构函数 |
|---|---|
 |
 |
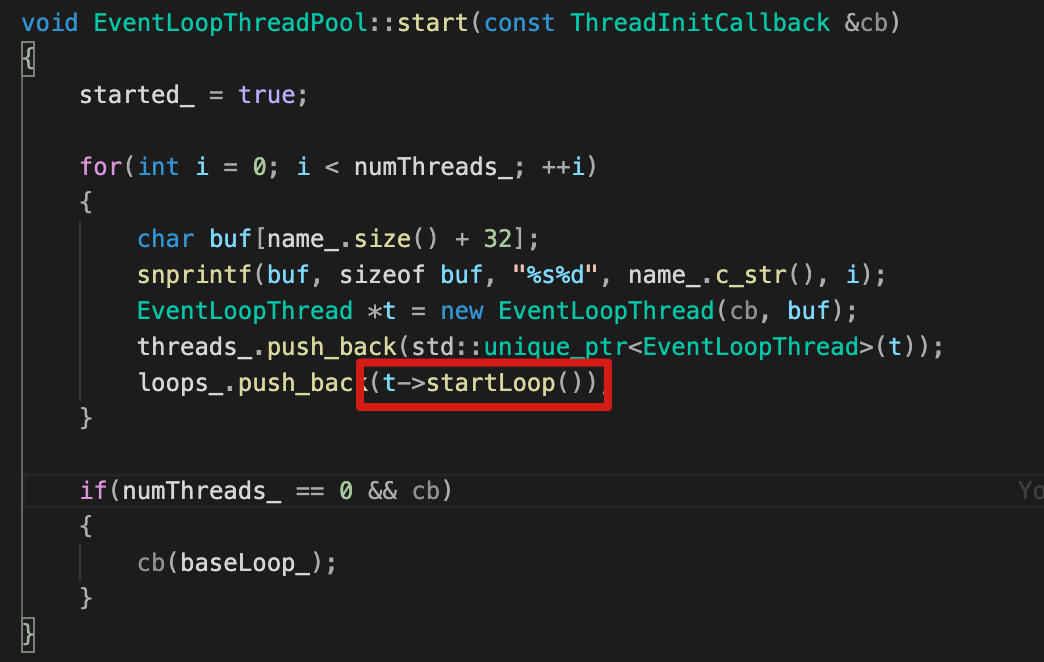
start() 函数
主要流程:
- 循环创建N个EventLoopThread对象,保存在
threads_,对于这N个对象; - 每个EventLoopThread对象执行
startLoop(),并启动底层的thread_线程; thread_线程, 创建EventLoop对象并启动loop()事件循环 。
可见,每个EventLoopThread对象(底层是thread_线程)都会创建一个EventLoop对象。也即是 one loop per thread的秘密所在。
startLoop()&threadFunc(),在EventLoopThread已详细分析,这里不再赘述。
| EventThreadPool::start()&startLoop() | EventLoopThread::threadFunc() |
|---|---|
 |
|
|
Muduo的“各个”核心类至此便介绍完成,我们再来“整体”串联整个muduo代码。
二、 从三个半事件处理再看Muduo
muduo作者chengshuo说过,TCP网络编程最本质的是处理三个半事件:
- 连接建立:包括服务器端被动接受连接(accept)和客户端主动发起连接(connect),TCP连接一旦建立,客户端和服务端就是平等的,可以各自收发数据;
- 消息到达:即文件描述符可读,这是最为重要的一个事件,对它的处理方式决定了网络编程的风格(阻塞还是非阻塞,如何处理分包,应用层的缓冲如何设计等等);
- 消息发送完毕(半个):对于低流量的服务,可不必关心这个事件;另外,这里的“发送完毕”是指数据写入操作系统缓冲区(内核缓冲区),将由TCP协议栈负责数据的发送与重传,不代表对方已经接收到数据;
- 连接断开:包括主动断开(close、shutdown)和被动断开(read()返回0)。
结合muduo代码,我们来深刻的全面理解。
2.1 连接建立
2.1.1 问题引入
对于Muduo这么一个基于Multi-Reator模型的网络库,连接的建立(或者说创建一个服务器)是如何完成的?
在前面tcpserver.cc示例,其实已经做了非常好的示例。但这仅仅是业务层面的调用,底层又是如何完成的?
其实前面的核心类分析,基本已经揭晓了答案。现在我们将各个“子图块”完整“拼接”起来。
2.2.2 从“复读机服务器”再看连接建立
EchoServer&TcpServer作用
EchoServer&TcpServer在tcpserver.cc被使用,这里先简单介绍:
-
EchoServer,是用户自定义的类,主要是封装了TcpServer对象
server_& 自定义连接、可读事件回调; -
TcpServer,如前介绍,它主要封装了Accpetor & EventThreadPool ,是提供给用户的接口类。如:
- 启动服务器
start()方法,启动线程池&创建线程&main loop开启事件循环; - 上述给用户注册自定义回调的
TcpServer::setConnectionCallback、TcpServer::setMessageCallback等方法。
TcpServer类成员 TcpServer构造函数 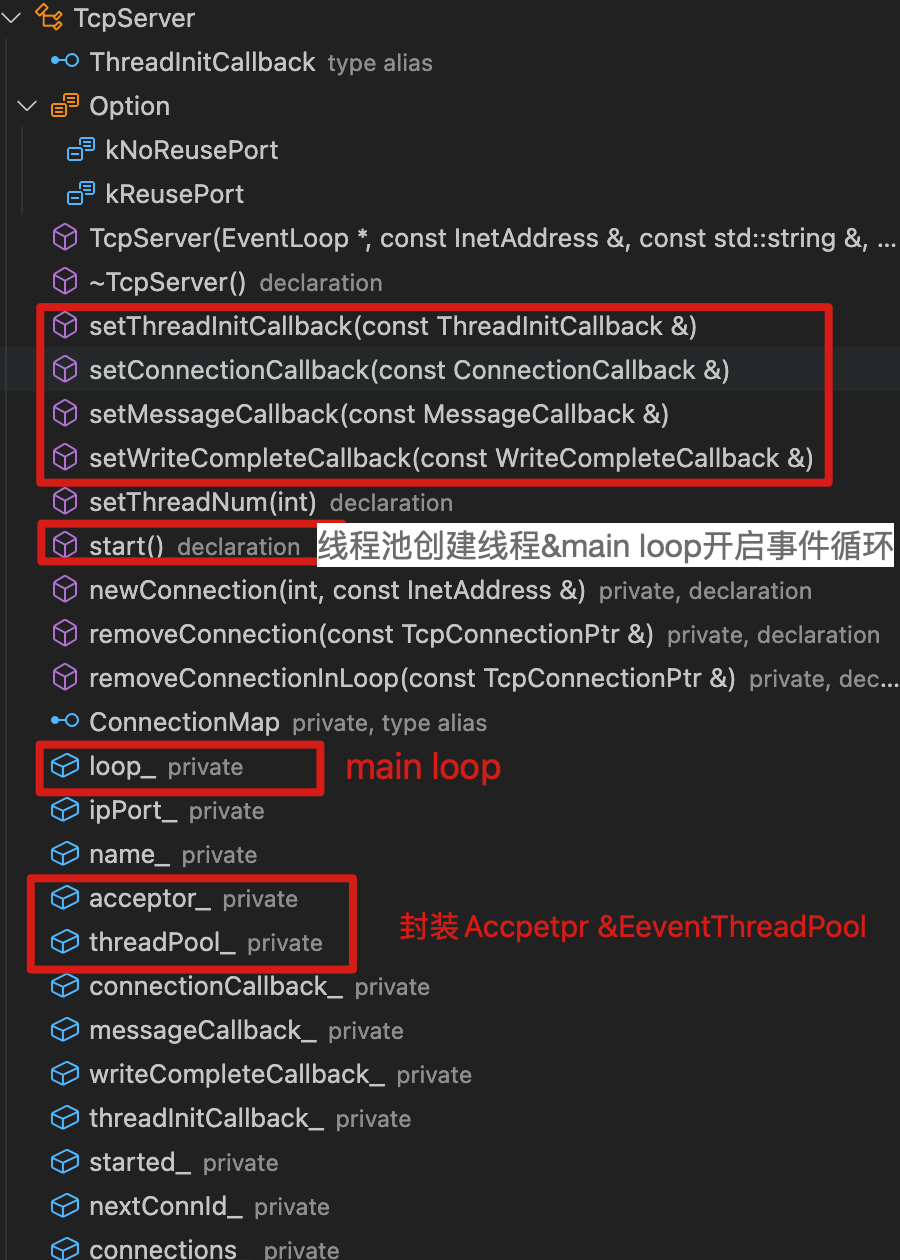
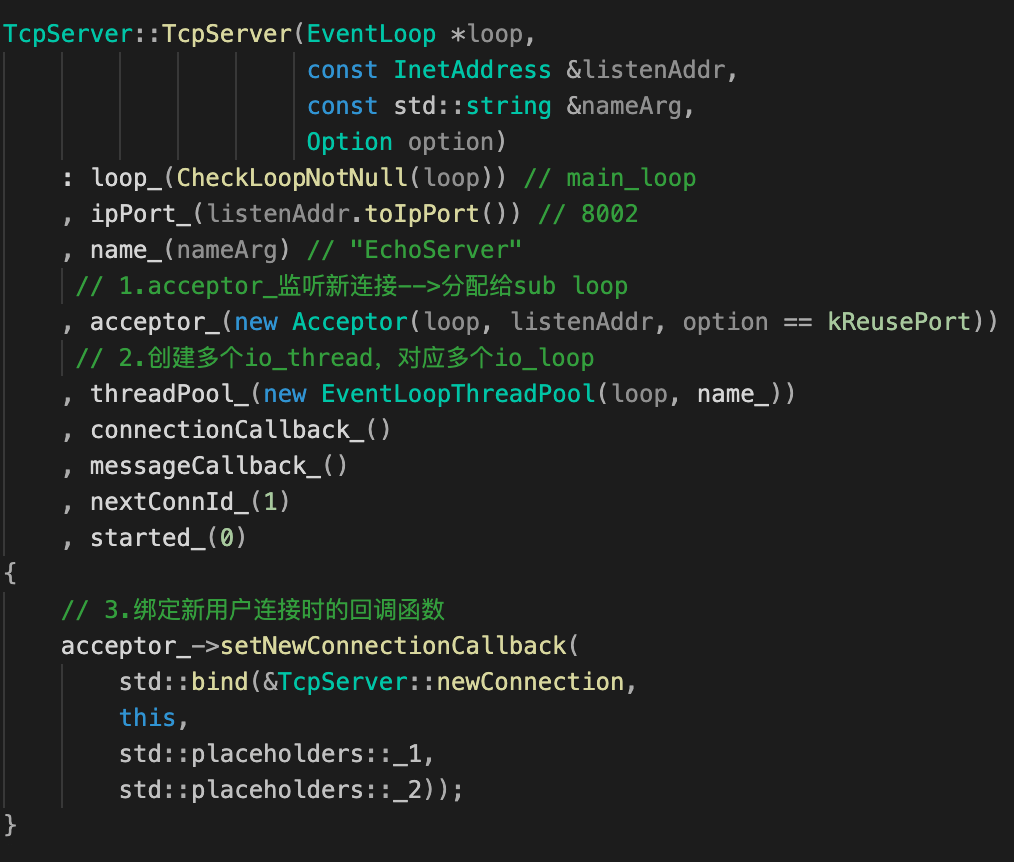
- 启动服务器
连接建立流程
回忆一下tcpserver.cc主要逻辑:
1 | class EchoServer |
-
用户自定义main loop,用于和后面Accpetor对象绑定;
-
封装要监听的ip&port,使用InetAddress封装;
-
EchoServer初始化,主要完成:
-
loop_字段绑定前面创建的main loop;
-
TcpServer对象server_初始化,参考上图TcpServer构造函数:

- loop_字段EchoServer传过来的main loop;
- Acceptor对象accpetor_初始化;
- EventThreadPool对象threadpoll_初始化;
- 设置accpetor_新连接时的回调函数(即
TcpServer::newConnnection,是Accepetor::handleRead函数核心逻辑)。
-
-
启动服务器server,真正调用的是
TcpServer::start()函数:1
2
3
4
5
6
7
8
9void TcpServer::start()
{
if (started_++ == 0) // 防止一个TcpServer对象被start多次
{
threadPool_->start(threadInitCallback_); // 启动底层的loop线程池
// main_loop 执行Acceptor::listen
loop_->runInLoop(std::bind(&Acceptor::listen, acceptor_.get()));
}
}-
线程池启动,即前所述的EventThreadPool::start()函数 :
- 循环创建N个EventLoopThread对象,保存在
threads_,对于这N个对象: - 每个EventLoopThread对象执行startLoop(),并启动底层的
thread_线程; thread_线程, 创建sub loop并启动loop()事件循环,监听clientfd的io事件 。
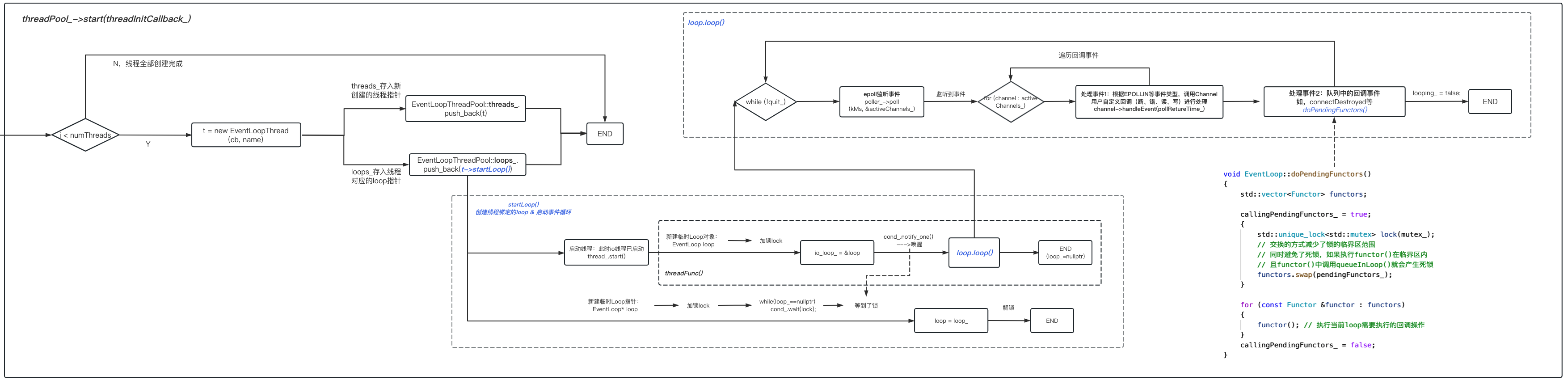
- 循环创建N个EventLoopThread对象,保存在
-
main loop的listenfd开始
listen()& 注册到epoll,listenfd开启listen() ,并在enableReading() 函数中将listenfd的io事件注册到epoll。1
loop_->runInLoop(std::bind(&Acceptor::listen, acceptor_.get()));
1
2
3
4
5
6void Acceptor::listen()
{
listenning_ = true;
acceptSocket_.listen(); // listen
acceptChannel_.enableReading(); // acceptChannel_绑定fd并注册至mian loop的底层epoll
}
-
-
main loop启动事件循环,epoll_wait监听listenfd的accpet连接事件 。
2.2 连接断开
2.2.1 问题引入
在处理连接断开,我们必然要面对这么两个灵魂发问:
- 如果是被动关闭连接:服务端如何感知,应该处理哪些逻辑?
- 如果是主动关闭连接:如何保证对方已经收到全部数据?直接close(fd)肯定是不行的。因为应用层往往有缓冲(这在非阻塞网络编程中是必需的),我们需要保证先发送完缓冲区中的数据,然后再断开连接。
2.2.2 被动关闭连接
如何感知?
在muduo中:
- 服务端
TcpConnection::handleRead()中,内部调用了Linux的函数readv(); - 当
readv()返回0的时候,服务端就知道客户端断开连接了。
如何处理?
当readv()返回0 ,会紧接着调用TcpConnection::handleClose(),一图明白后续调用链:
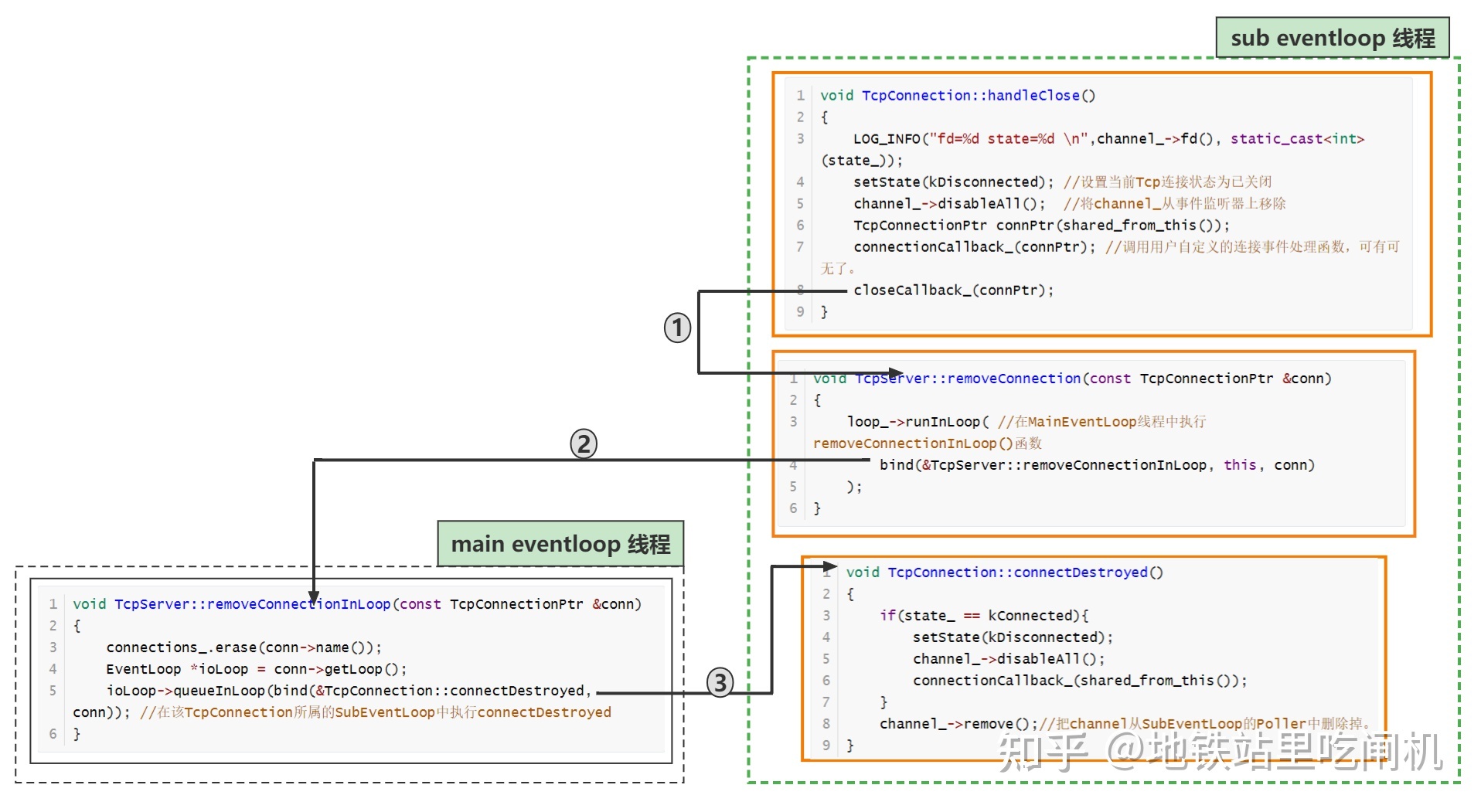
- 将TcpConnection的channel_从Poller取消监听,因为一个TcpConnection对应一个Channel,连接关闭了首要是将channel_从Sub-EventLoop的epoll取消监听;
- 执行用户自定义的connectCallback_回调;
- 在TcpServer::connections_移除当前TcpConnection对象,由于
connections_(一个unordered_map,负责保存<KEY:connName,VALUE:TcpConnection>的映射)在TcpServer中定义(主线程),所以这里会跳转到main loop去执行; - 最后将TcpConnection::channel_从底层Poller::chanenlMap移除,chanenlMap保存
<KEY:sockfd,VALUE:Channel>映射。
2.2.3 主动关闭连接
如何实现优雅关闭?
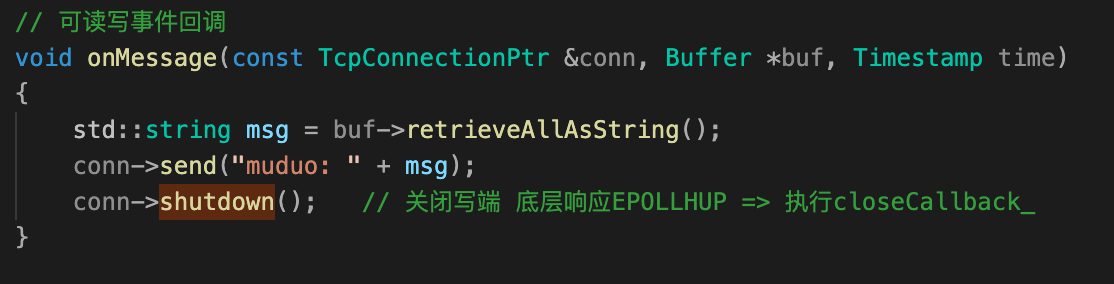
在“复读机”服务器示例中,“复读”完可以主动调用shutdown() 关闭连接。这是一种“优雅关闭”,保证主动关闭时正在发生的数据可以全部发生完:
-
如果要主动关闭连接,先关本地“写”端
这样muduo会发送 TCP FIN 分节,对方会读到 0 字节。注意此时muduo不是调用
close(fd),所以不是完全关闭。 -
等对方关闭之后,再关本地“读”端
- 一般来说,对方通常会关闭连接,这样 muduo 会read到 0 字节,然后 muduo 调用
TcpConnection::handleClose()取消监听&移除channel_&connections_移除当前TcpConnection对象,不再接收客户端数据,即关闭了“读端”; - 不过这种做法有风险:万一对方故意不不关,那么 muduo 的连接就一直半开着,消耗系统资源。
- 一般来说,对方通常会关闭连接,这样 muduo 会read到 0 字节,然后 muduo 调用
完整的代码实现:
| 用户自定义回调 | shutdown()实现 |
|---|---|
 |
 |
但是,截止目前依旧疑云重重:
什么时候muduo才会真正的close(fd)关闭连接?
答案是:在 TcpConnection 对象析构的时候。TcpConnection 不再持有一个 Socket 对象(sockfd_),Socket 是一个 RAII handler,它的析构函数会 close(sockfd_)。
1 | class TcpConnection : noncopyable, public std::enable_shared_from_this<TcpConnection> |
那什么时候会触发TcpConnection 对象析构?
我们知道,每个TcpConnection 对象引用计数至少为2,有新连接时执行TcpServer::newConnection:
- 创建TcpConnection 对象指针
conn时, 该conn持有对象; TcpServer::connections_持有所有TcpConnection 对象。
1 | void TcpServer::newConnection(int sockfd, const InetAddress &peerAddr) |
关键在于让connections_ 释放持有的TcpConnection 对象,从而触发TcpConnection 对象析构==> Socket 对象对象析构。
connections_ 在什么时候会释放持有的TcpConnection 对象?
答案是在触发TcpServer::removeConnection 时。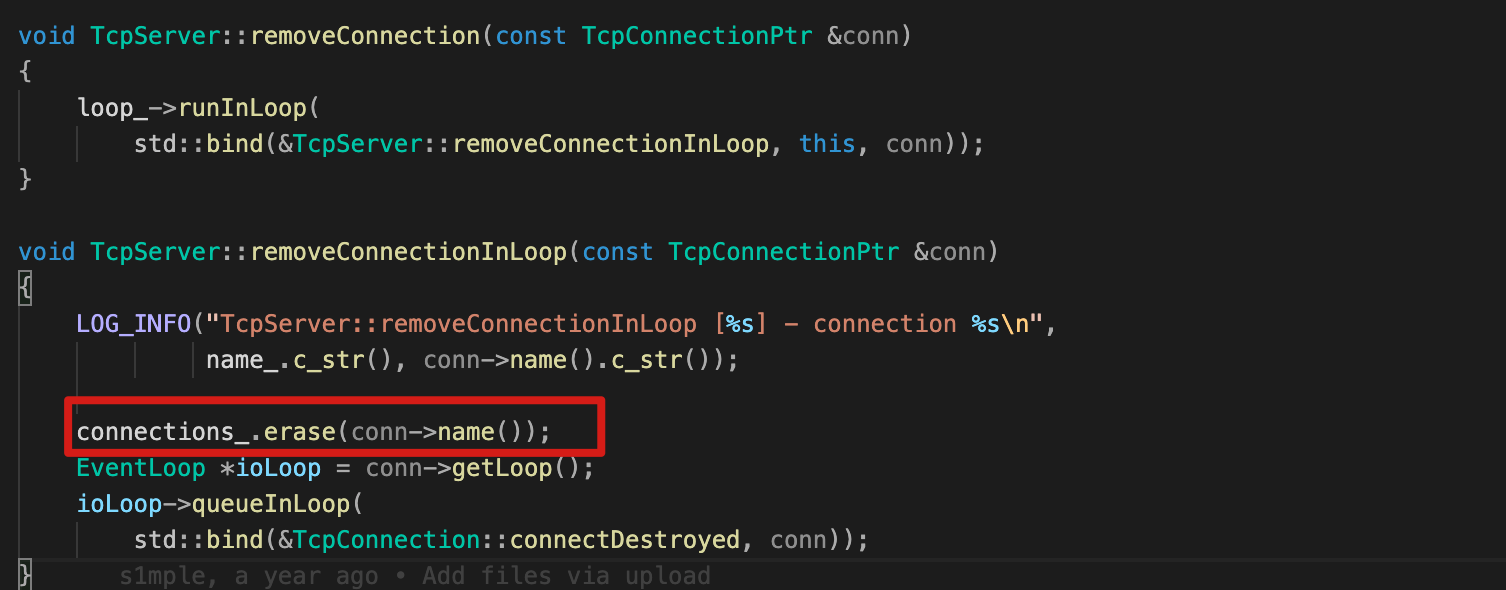
而removeConnection函数:
shutdown(),关闭写端,底层响应EPOLLHUP,会触发TcpConnection::handleClose(),进而触发removeConnection函数。- read到0,也会触发
TcpConnection::handleClose()函数。
如果 TcpConnection 的引用计数降到零,它就会析构了。
当服务器主动关闭时,调用TcpServer::~TcpServer()析构函数,也会析构所有TcpConnection对象:
1 | TcpServer::~TcpServer() |
TcpConnection::connectDestroyed 即将所管理的channel_在chanenlMap移除。
疑问
为什么这里不执行
disableAll()? 不先取消事件监听?观察到,相比
~Accpetor()析构wakeupChannel_还是前面被动关闭连接析构channel_还会先执行disableAll(),将channel_从sub EventLoop的epoll取消监听。
如何保证主动关闭时正在发生的数据可以全部发生完?
我们需要tie:保证先让Channel回调函数先把数据发送完,再释放TcpConnection对象的资源。
参考前:1.3.1其中小节—tie深入理解。
2.3 消息到达
2.3.1 问题引入
为什么要应用层接收缓冲区?
消息到达是最重要的事件,对它的处理决定了网络编程的风格:①是阻塞还是非阻塞;②分包的处理;③应用层的缓冲如何设计等等。
在非阻塞网络编程中,为什么要使用应用层接收缓冲区?
假如一次读到的数据不够一个完整的数据包,也就是需要分包去区分一个个消息:已经读到的数据应该先暂存在某个地方,等剩余的数据收到之后再一并处理;
常见的分包方法有:
- 固定长度;
- 特殊的结尾符,比如字符串的\0,或者回车换行等;
- 固定的消息头中指定后续的消息的长度,然后跟上一个消息体内容;
- 使用协议本身的格式,比如json格式头尾配对(XML也一样)。
但是:从系统内核中调用的时候,在应用层需要有足够大的缓冲区,最好能一次将系统recv到的缓冲区给读空,但这可能是不行的;每次针对每个连接一次都分配较大的缓冲区,又会浪费严重。
该如何处理?
2.3.2 muduo是如何做的?TcpConnection::handleRead
TcpConnection::handleRead的核心函数便是Buffer::readFd。
Buffer已经是老熟人了:
- 底层数据结构:使用的是
vector::buffer_,可以动态增长 ;- 核心函数:
Buffer_.readFd(channel_->fd(), &saveErrno)。
1 | void TcpConnection::handleRead(Timestamp receiveTime) |
readFd关键设计:
- 设计两个缓冲区vec[2],vec[1]指向Buffer底层的
buffer_,vec[2]预分64K临时空间extrabuf; - readv的时候,如果第一个缓冲区<=64k就使用两个缓冲区,否则就只使用第一个缓冲区(一般不会超过64K,tcp buffer如果确实要设置大的缓存区,需要调整系统参数),这样一次读取就足以将socket中的缓存区读空;
- 开始readv,将socket上数据读到两个缓冲区;
- 如果第一个缓冲区已满,
buffer_扩容,将第二个缓冲区数据append到第一个缓冲区;
这样:既①保证一次就可以读完socket ;②也避免预申请过大的buffer_。
具体实现代码如下:
1 | /** |
2.4 消息发送
2.4.1 问题引入
为什么要应用层发送缓冲区?
- TCP发送缓冲区空间不足:TCP发送缓冲区会出现不足;
- 应用层接收慢:发送数据时,应用层写的快而内核发送数据慢,需要把待发送数据写入缓冲区。
TCP发送缓冲区不足如何处理?
假设应用程序需要发送40kB 数据,但是操作系统的 TCP 发送缓冲区只有 25kB 剩余空间,那么剩下的 15kB数据怎么办?
-
如果等待 OS 缓冲区可用,会阻塞当前线程,所以我们需要一个发送缓冲区。
-
但是,如果应用程序随后又要发送 50kB 数据,不能立刻尝试 write() ,这样有可能打乱数据的顺序。如果发送缓冲区不为空,应该先write到发送缓冲区。
这也是muduo的做法。
2.4.2 muduo是如何做的:TcpConnetion::send
在muduo中,当用户调用了TcpConnetion::send(buf)函数时:
- 如果发送缓冲区没有待发送数据:
- 如果TCP发送缓冲区能一次性容纳buf,调用用户自定义的
writeCompleteCallback_来移除该TcpConnection在事件监听器上的可写事件(因为大多数时候是没有数据需要发送的,频繁触发可写事件但又没有数据可写); - 如果TCP发送缓冲区不能一次性容纳buf,判断一下errno是不是SIGPIPE RESET等致命错误。
- 如果TCP发送缓冲区能一次性容纳buf,调用用户自定义的
- 如果发送缓冲区没有待发送数据 && 非致命错误:
- 判断是否是高水位,执行回调
highWaterMarkCallback_; - 不直接write,先将数据append到发送缓冲区(如果缓冲区不足会执行
makeSpace扩容); - 注册当前
channel_的写事件,通知epoll监听处理。
- 判断是否是高水位,执行回调
完整代码如下:
1 | /** |
2.5 其它:LT与ET
细心的读者已经注意到,Muduo使用的是LT(Lever Trigger,边缘触发,默认模式)而非是ET(Edge Trigger,边缘触发)。
- 为什么muduo使用ET?不是说ET更快吗?
- LT什么时候关注 EPOLLOUT 事件?会造成 busy-loop吗?muduo是怎么做的?
- 如果使用ET,如何防止漏读造成的饥饿?
2.5.1 LT与ET介绍
要讲明白这个问题,我们先来复习LT与ET基本概念和触发条件。
LT与ET触发条件
LT与ET两种模式本质区别:
- 对于水平触发模式LT,一个事件只要有就会一直触发;
- 对于边缘触发模式ET,只有一个事件从无到有才会触发。
具体到读、写事件:
| 读事件触发条件 | 写事件触发条件 | |
|---|---|---|
| LT | socket有数据(就一直触发) | socket可写(就一直触发) |
| ET | socket有新数据到来 | socket不可写 => socket可写 |
这决定LT、ET在编程上对于读、写事件的不同处理。
LT与ET编程
对于一个非阻塞 socket:
| 读事件处理 | 写事件处理 | |
|---|---|---|
| LT | 根据业务自行决定recv多少数据,尽量多读点防止busy-loop | 必须:不需要写事件EPOLLOUT一定要及时移除,避免busy-loop |
| ET | 必须:循环recv到错误码EWOULDBLOCK/EAGAIN,防止漏读 |
根据业务自行决定下次是否触发 |
所在,对于LT模式,最要紧的就是防止busy-loop:
- 对于可读事件busy-loop:muduo有接收缓冲区+recv(2)策略,能保证数据能被尽量一次读完;
- 对于可写事件busy-loop:在muduo的
TcpConnetion::send(buf)函数时,如果能一次发送完,会马上调用writeCompleteCallback_回调函数,移除可写事件监听;如果不能发完,可以先放到发送缓冲区。
2.5.2 muduo为什么使用ET?
muduo使用是LT而非ET,主要原因:
- LT读的时候只需要一次系统调用,而ET必须循环read到EAGAIN错误逻辑处理更复杂;
- muduo有应用层缓冲区,对于可读/可写事件的busy-loop,可以进行很好的避免。
而且:ET不一定比LT快 。
ET模式下用户要自行进行 read/write 循环处理,这其中增加的read/write系统调用和减少的epoll 系统调用相比,综合收益其实不大。为了降低处理逻辑复杂度,常用的事件处理库大部分都选择了LT 模式(如 libevent、boost::asio、muduo等)。
三、总结与展望
3.1 本文总结
本文主要介绍了以下内容:
-
高并发IO网络模型介绍,从最简单的单线程网络IO模型==>Reactor模式==>Muduo网络框架介绍;
-
Muduo各个核心类的介绍,尤其是对
loop()、tie等重难点进行了介绍; -
结合muduo源码,来分析“三个半事件”的每个事件的关键处理,如:muduo连接建立全流程、被动关闭如何感知/处理、主动优雅关闭、消息到达使用缓冲区+recv(2)处理分包、消息发送使用缓冲区处理应用层接收慢或TCP发送缓冲区不足等;
-
muduo为何使用LT等。
总的来说尽量考虑了整体联系和细节丰满。
3.2 未来展望
本文陆陆续续在半个月落笔完成,中间修修改改多次。在成文的过程中,也学习、巩固到不少网络编程知识。对于网络编程入门来说,muduo的确是个不错的参考。
但限于自身水平,自己对muduo中一些设计细节还是存在些疑问。比如,muduo代码大量使用了智能指针和RAII管理对象的生命周期,但对于TcpConnection/Eventloop/Socket/…各个对象在连接关闭/整个服务器关闭/…等各种情况核心设计处理理念,目前依旧存在些疑惑。这个,留到后面再来补全吧!
最后,如果本文能给学习网络编程or研究muduo库的同学带来帮助,那就再好不过了。欢迎在下留言交流。
四、更新记录
- 修正一些排版bug;
- 更新1.2节传统IO性能改进相关描述。
- 第一次更新上传。
五、参考文献
- 1.陈硕.《Linux多线程服务端编程》 ↩
- 2.万字长文梳理Muduo库核心代码及优秀编程细节思想剖析:https://zhuanlan.zhihu.com/p/495016351 ↩
- 3.Muduo 源码分析:https://youjiali1995.github.io/network/muduo/ ↩
- 4.IO - Netty的模型:https://www.cnblogs.com/hlkawa/p/15303013.html ↩
- 5.【muduo】net篇---TcpConnection:https://blog.csdn.net/daaikuaichuan/article/details/87822822 ↩
- 6.高并发之网络IO模型 https://www.cnblogs.com/xiekun/p/16593204.html ↩
 微信
微信 支付宝
支付宝


