
C++从零开始(三):务实基础(上)快速入门
🌟《C++从零开始》 系列,开始更新中…

一、快速开始
1.1 认识C++
1.1.1 为什么需要C++
前有Java后有Python、Go、Rust,C++作为一个“老古董”似乎有点格格不入了?
其实不然,C 和 C++ 的底层设计理念可以概括为“信任程序员”——这既美妙又危险。但也正是C++ 允许程序员高度自由地做他们想做的事,因此,在需要高性能和精确控制内存和其他资源的情况下表现出色 。
例如,下面是C++擅长的一些领域,它们对性能要求通常极其苛刻:
- 视频游戏
- 实时系统(例如用于运输、制造等……)
- 高性能金融应用(例如高频交易)
- 图形应用和模拟
- 生产力/办公应用
- 嵌入式软件
- 音视频处理
- 人工智能和神经网络
如果你想更了解计算机的本质,也对这些领域感兴趣,C/C++应该是你不二的选择。
1.1.2 C++组成
标准的C++由两个重要部分组成:
- 核心语言,提供了所有构件块,包括变量、数据类型和常量等等。
- C++ 标准库,提供了大量的函数,用于操作文件、字符串等,包含标准模板库(STL),提供了大量的方法,用于操作数据结构等。
C++ 标准库简单来说就是提供一些预定的库及函数,方便我们编写代码。整体可以分为两部分:
- 标准函数库: 这个库是由通用的、独立的、不属于任何类的函数组成的,函数库继承自 C 语言。
- 输入/输出 I/O、字符串和字符处理、数学、时间、日期和本地化、动态分配、其他、宽字符函数
- 面向对象类库: 这个库是类及其相关函数的集合。
- 标准的 C++ I/O 类、String 类、数值类、STL 容器类、STL 算法、STL 函数对象、STL 迭代器、STL 分配器、本地化库、异常处理类、杂项支持库
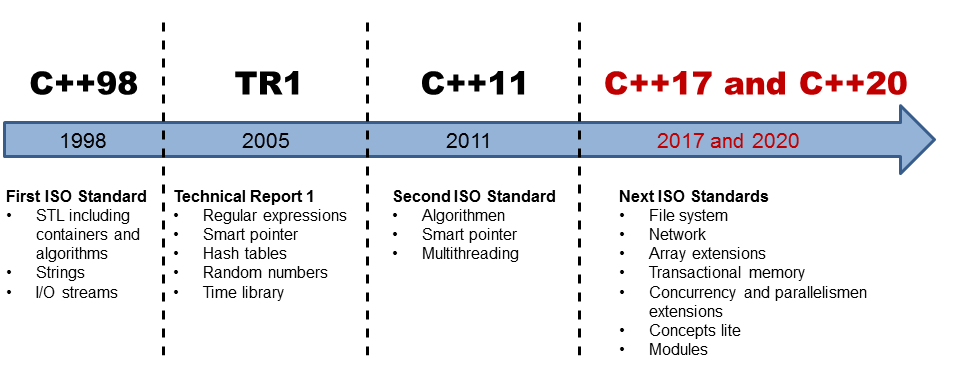
同时,为了编写的代码在 Mac、UNIX、Windows、Alpha 计算机上都能通过编译, C++ 采用ISO标准。
ISO标准发展历史一览如下:
1.1.3 第一个C++程序
🖱 从梦开始的地方,写一个经典hello.cpp 。
1 |
|
确保g++程序可被识别(加入到环境变量中),在包含源文件 hello.cpp 的目录中,编译并执行:
1 | $ g++ hello.cpp |
g++编译代码的方式将在本文大量使用,在前文:g++/Makefile/CMake快速入门 ,我们也仔细介绍过。如果还不太了解,可以一读。
在上述程序中还使用了C++的注释:
- 单行注释:
// 注释内容 - 多行注释:
/* 注释内容 */
特别的,在 /* */ 注释内部,// 字符没有特殊的含义;在 // 注释内,/* */ 也没有特殊的含义。
1.2 变量
“变量”一词来源于数学,是计算机表示能储存计算结果或能表示值的抽象概念,但这种说法不够深刻。
应该从CPU角度理解,变量就是某块内存区域地址别名,这块内存区域保存变量的值。下面举一个实例:
1 | int x = 0; |
对应汇编代码:
1 | movl $0, -12(%rbp) |
- 当CPU执行
int x = 0,会在内存(这里是栈)腾出一块区域(-12(%rbp))用来存储变量x;然后x所代表的内存区域(-12(%rbp))被存入0。 - 继续执行
x=1,1被存入变量x所代表的内存区域。
可以看到,变量的存在使得我们:不用记住为分配x的内存地址是什么,我们通过变量名x就可以使用分配的内存区域。因为使用x时,编译器会将变量x隐式自动翻译成对应的内存地址,同时进行间接寻址(可以理解为使用x等价于*x)。
1 | int x = 0; // 编译器眼里:int* x = -12(%rbp); *x = 0; |
说完深层次的概念,我们来了解变量基本的一些定义&使用。
1 | /* a simple example*/ |
可以看到组成变量的基本三要素:名称、类型及值。
-
名称:变量的名称可以由字母、数字和下划线字符组成。
-
类型:用于指定变量存储的大小和布局。在C++中有基本类型和其它的如枚举等类型。
-
基本类型:C++ 七种基本数据类型如下。
类型 关键字 布尔型 bool 字符型 char 整型 int 浮点型 float 双浮点型 double 无类型 void 宽字符型 wchar_t -
其它类型
C++ 也允许定义各种其他类型的变量,比如枚举、指针、数组、引用、数据结构、类等。这是我们后续笔记会继续提到的知识点。
-
在上面我们提到了变量三要素:名称、值和类型。由此可以引发几个小问题:
-
C++变量名称有什么命令规则或规律吗?
-
C++不同的位置(如,main函数体内、外)定义的变量有什么区别吗?
-
C++的变量存储有上限吗?比如int类型的变量最多可以存储多大的数据?
-
实际写代码中,变量不一定立马给它赋值(初始化),变量的初始化值会是什么呢?为什么常说变量不初始化是一个不好的行为?
1.2.1 标识符和命令规则
C++ 标识符是用来标识变量、函数、类、模块,或任何其他用户自定义项目的名称。一个标识符以字母 A-Z 或 a-z 或下划线 _ 开始,后跟零个或多个字母、下划线和数字(0-9)。
C++ 标识符内不允许出现标点字符,比如 @、& 和 %。C++ 是区分大小写的编程语言。因此,在 C++ 中,Manpower 和 manpower 是两个不同的标识符。
下面列出几个有效的标识符:
1 | mohd zara abc move_name a_123 |
1.2.2 局部变量和全局变量
一般来说有三个地方可以声明变量:
- 函数或一个代码块内部,称为局部变量;
- 函数参数中,称为形式参数;
- 所有函数外部,称为全局变量。
在之前的例子中:
1 | /* a simple example*/ |
-
【扩展思考】特别的,如果局部变量和全局变量的名称相同,调用时以谁的值为准?
- 答案:以局部变量值为准,请看下例。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
using namespace std;
// main函数体外,全局变量
extern char c, ch;
int months;
int empoly_salary = 24000;
int main()
{
int empoly_salary = 20000; // main函数体内,局部变量
cout<< empoly_salary<<endl;
return 0;
}代码输出值:20000。局部变量的值会覆盖全局变量的值。
-
【深入总结】全局变量和局部变量的区别和总结
-
声明位置不同:局部变量声明在函数或代码块内部;全局变量声明在所有函数的外部。
-
生命周期不同:全局变量随主程序创建和创建,随主程序销毁而销毁;局部变量在局部函数内部,甚至局部循环体等内部存在,退出就不存在;
-
使用方式不同:通过声明后全局变量在程序的各个部分都可以用到,分配在全局数据段并且在程序开始运行的时候被加载;局部变量分配在堆栈区,只能在局部使用。
-
1.2.3 变量类型
七种基本类型
在前面我们提到:
-
变量其实只不过是程序可操作的存储区的名称,类型决定了变量存储的大小和布局。
-
C++有七种基本类型
类型 关键字 布尔型 bool 字符型 char 整型 int 浮点型 float 双浮点型 double 无类型 void 宽字符型 wchar_t
这些基本类型可以使用一个或多个类型修饰符进行修饰:
- signed、unsigned、short、long
例如, wchar_t 是这样来的:
1 | typedef short int wchar_t; |
所以 wchar_t 实际上和 short int 一样。
每种类型需占用不同的字节数,存储上下限如下所示:
| 类型 | 描述 | 取值范围 | 字节数 |
|---|---|---|---|
| int | 整型,表示整数 | -2^-31^ ~ 2^31^-1 | 4 |
| unsigned int | 无符号整型,表示整数 | 0 ~ 2^32^-1 | 4 |
| bool | 布尔类型 | true或false | 1 |
| char | 字符类型,是整型 | -128~127 | 1 |
| unsigned char | 无符号字符类型,是整型 | 0~255 | 1 |
| float | 单精度浮点值,表示实数 | 3.4×10^-38^ ~ 3.4×10^38^ | 4 |
| double | 双精度浮点值,表示实数 | 1.7×10^-308^ ~ 1.7×10^308^ | 8 |
| long | 长整型 | -2^-31^ ~ 2×10^31^-1 | 4 |
| unsigned long | 无符号长整型 | 0 ~ 2^32^-1 | 4 |
| unsigned long long | 无符号长整型,64位 | 0 ~ 2×10^64^-1 | 8 |
| short | 短整型 | -2^-15^ ~ 2^15^-1 | 2 |
| unsigned short | 无符号短整型 | 0 ~ 2^16^-1 | 2 |
如何比较浮点变量?
这是一个很有意思的小问题,它涉及到计算机一些底层表示。
永远不要使用== 比较两个浮点变量,因为计算机不能精确表示非2的指数幂小数。
你或许表示疑问:直接==比较不可以吗?
1 | float a = 2.33; |
输出:
1 | 相等 |
— 这没毛病啊老铁?
不,老铁问题大的很勒!
下面比较便出现了意料之外的结果。
1 | float a = 2.33; |
输出:
1 | 不相等 |
这是因为b 、a 在底层二进制中不能精确表示,只能无限趋近。实际存储中,计算机只会截断保留一定长度的二进制数,并不能精确表示浮点数 。
以IEEE 754标准为例,单精度(总32位)尾数保留23位,其余指数8位,符号位1位(在线转换地址)。

在浮点运算中,计算机也是使用二进制进行计算:
-
最开始
a=b=2.33,判断a=b是否相等:计算机通过对比每一个bit,因为b和a底层二进制表示相等,所以直接比较两个相等浮点数不会出错; -
但是如果是
a-b,浮点数参与了运算:因此操作数b和a本来就是不精确的二进制表示,计算出来的二进制结果自然无法精确表示的0.01。1
00111100001000111101011100001010 # 32位,0.01对应二进制表示
所以参与了运算的浮点数b-a 再和0.01 比较出错。
但也并不是所有的浮点数都不能精确表示,2的整数冥的浮点数便可以精确表示。
IEEE 754存储标准如下。
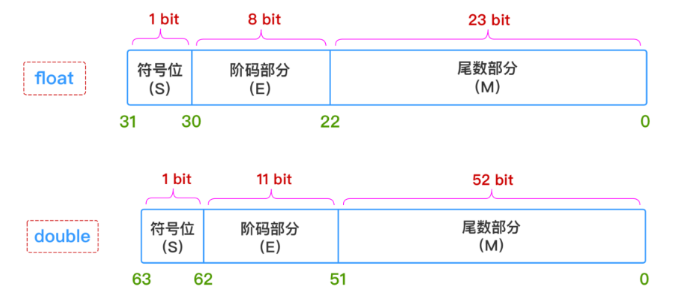
根据标准, ,显然0.5 可以被精确表示。

1.2.4 变量初始化🌟
初始化是指声明变量但没有定义它(没有指定初值)时,编译器进行的默认初始化(赋值)操作。
先讲讲上述概念中出现的新名词,“声明”和“定义”。
声明和定义的区别?
说清楚这个问题,要分变量和函数两个方面讨论。
声明可以多次,定义只能有一次。
如果是变量。
-
声明(一般在
.h文件中):仅仅是把变量的声明的位置及类型提供给编译器,并不分配内存空间;1
2extern int a ; // 仅声明,别处定义
extern int b = 10; // 声明,同时进行定义,为变量b分配了空间且存储了值10⚠️ 注意如果不是
extern关键字修饰的变量,C++中的变量声明时编译器会自动定义(默认初始化)。下面进行举例说明。
1
2/*other.h*/
int a; // 声明+定义(存储值0)如果有多个
.cpp文件include “other.h”,会重复定义多次a(定义只能有一次)。-
main.cpp
1
2
3
4
5
6
7
using namespace std;
int main()
{
} -
other.cpp
1
尝试编译出错:
1
2
3[root@roy-cpp test]# g++ -std=c++11 main.cpp other.cpp -o main.out
/tmp/cc2DsgGi.o:(.data+0x0): multiple definition of `a'
/tmp/ccDlbvUg.o:(.data+0x0): first defined here更糟糕的是,此时采用
ifndef防止预编译重复定义没有用,更多ifndef解释参考:C++防止头文件被重复引入的3种方法 。因为此时
main.cpp、other.cpp是分别编译的,main.cpp中的define OTHER_H对other.cpp不起作用。1
2
3
4
5/*other.h*/
int a;为了避免这种问题,为了避免这种问题我们只有将头文件中变量声明为extern:
1
extern int a;
再次编译正常:
1
[root@roy-cpp test]
main.cpp和other.cpp都是拥有a的声明,声明可以多次。 -
-
定义(一般在
.cpp文件中):要在定义的地方为其分配存储空间,相同变量可以在多处声明(外部变量extern),但只能在一处定义。
1 | int a; // 声明也是定义,编译器默认初始化 |
如果是函数。
-
声明(一般在
.h文件中):把函数的位置、参数和返回类型等信息告诉编译器;1
int Max(int x, int y);
函数定义不会被默认初始化,故无需extern。
-
定义(一般在
.cpp文件中):在源文件中实现具体函数,并为其分配内存。1
2
3
4int Max(int x, int y)
{
return x > y ? x : y;
}
最佳实践:头文件里应该放什么?
参考:muduo 中做法。
在头文件test.h中:
-
全局变量:注意用extern关键字修饰,只声明。
1
extern int a;
-
函数:只声明
1
int Max(int x, int y);
如果是内联函数可直接定义。
1
2
3
4inline void func()
{
// do something
}内联函数会被直接替换,不用担心重复定义的问题。
-
结构体:声明+定义。
1
2
3
4struct S
{
bool isOK;
};由于结构体已经被定义,如果有多个
.cpp文件 include了test.h容易出现重复定义。这也是为什么开源文件中往往在.h文件中使用#ifndef 避免头文件被重复引入。1
2
3
4
5
6
7
struct S
{
bool isOK;
}; -
类:类声明+定义,内部成员只声明。
同上,需注意使用#ifndef 。
1
2
3
4
5
6
7
8
9class MyClass
{
public:
int get_value();
private:
int value;
};普通成员函数(普通构造函数或析构函数、访问函数等)建议在类中(头文件)定义;重要的成员函数应在与类同名的 .cpp 文件中定义。
-
其它:define宏定义。
在源文件test.cpp中:
实现test.h相关定义。
1 |
|
默认初始化
变量值声明时的初始化值不仅和变量的类型有关系,也和变量声明的位置有关系:
-
对于内置类型变量(如
int,double,bool等)- 函数体之外的变量:会进行"零值初始化" ;
- 函数体之内的变量:此时该变量是未定义值,在一些IDE中如VS2017使用会报错;在一些编译器中如VSCode2020可以被使用,部分会被初始化,部分指向内存中“野值”;
- 静态变量(包括局部静态变量):进行"零值初始化"。
-
对于类成员变量(Class):
-
原生类型:int类型或者指针类型等,他们不会被初始化。但是,他们会使用类实例内存地址中任何已经存在的野值作为自己的值;
- 对象类型:如string类型,默认构造器会被调用初始化为空串
"";
- 对象类型:如string类型,默认构造器会被调用初始化为空串
-
引用类型:无法通过编译。
-
对于以上描述我们进行实例验证。
【实例】不同情况初始化验证。
我们先给出各种情况下总结,具有验证请查看下方代码。
| int/float/double | bool | string/char | 指针 | 引用 | |
|---|---|---|---|---|---|
| 局部变量 | 野值 | 0 | "",'' |
野值 | 出错 |
| 全局变量/静态变量 | 0 | 0 | "",'' |
0 | 出错 |
| 类成员 | 野值 | 野值 | "",野值 |
""/野值 |
出错 |
以下是实际代码验证。
-
函数体外变量
可以看到,函数体外的所有变量(全局变量)都已经被零值初始化:整数/浮点类型/指针初始化为0;字符串类型被初始化空串。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
using namespace std;
// 1.数值类型
int num; // 0
float f; // 0
double d; // 0
// 2.bool 类型
bool b; // 0
// 3.字符串类型
string str; // ""
char c; // ''
// 4.指针: 零值
// 旧版本C++, 0 成为指示无效内存位置值
string *str_ptr; // 0
int *ptr; // 0
// 5.引用:出错
string &str_ref; // error: not initialized
int &int_ref; // error: not initialized
int main()
{
// 打印测试代码略
return 0;
}
-
函数体内变量
VSCode(g++ 4.6+)中给部分局部变量进行了“初始化”,直接使用并未报错。但是,浮点类型和指针的值都指向了野值。
函数体内变量变量不初始化,是个危险且错误的编程行为,使得代码很难调试。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
using namespace std;
int func()
{
// 1.数值类型
int num; // 野值:9.88131e-324
float f; // 野值:5.88128e-39
double d; // 野值:2.07385e-317
// 2.bool 类型
bool b; // 0
// 3.字符串类型
string str; // ""
char c; // ''
// 4.指针: 零值
// 指针指向内存中随机地址值,这非常危险
string *str_ptr; // 0x400a10
int *ptr; // 0x400be0
// 5.引用:出错
string &str_ref; // error: not initialized
int &int_ref; // error: not initialized
}
int main()
{
// 打印测试代码略
return 0;
}
-
静态变量
特别的,静态变量不论是局部静态变量还是全局静态变量都会进行零值初始化。初始化规则同全局变量。
❓ 局部静态变量,每次进入函数都会被初始化吗?
静态局部变量和全局变量一样,数据都存放在全局区域,所以在主程序main执行之前,编译器已经为其分配好了内存,即只会被初始化一次。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
using namespace std;
int count_calls()
{
// 主程序执行就已被初始化
// 后续进入函数不会再执行初始化变为0
static int ctr; // 默认初始化为 0
return ++ctr;
}
// 这段程序将输出从 1 到 10 的数字。
int main()
{
for(int i=0; i != 10; ++i)
{
cout << count_calls() << endl;
}
return 0;
}
-
类成员变量
可以看到,类成员变量值如果不给定初始化:基本类型变量指向野值;引用类型会非法警告。
但是,对象类型string会被“零值初始化”(
空串)。这是因为string类型的默认构造函数被调用,而string的默认构造会将string类型值初始化为空串。显然,类成员变量最好在使用前进行初始化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
using namespace std;
class test
{
public:
// 1.数值类型
int num; // 野值:1760379232
float f; // 野值:4.59149e-41
double d; // 野值:4.59149e-41
// 2.bool 类型
bool b ; // 野值:2
// 3.字符串类型
string str; // "" 空,对象类型,会调用string构造函数初始化,所以是""
char c; // 野值
// 4.指针
// 指针指向内存中随机地址值,这非常危险
string *str_ptr; // 0
int *ptr; // 0x400d00
// 5.引用:出错
string &str_ref; // not initialized
int &int_ref; // not initialized
public:
// 默认构造函数:不做任何操作
test() {};
};
int main()
{
test t;
// 打印测试代码略
return 0;
}
1.3 关键字
在前面的例子,多次见到的extern关键字是什么意思呢?
1 | extern char c, ch; |
在这之前,我们先简单介绍一下什么是关键字,有个整体的概念和了解。
关键字是预定义的单词,对编译器具有特殊的含义。例如,前面我们看到的int、float等基本变量类型也是关键字的一部分。
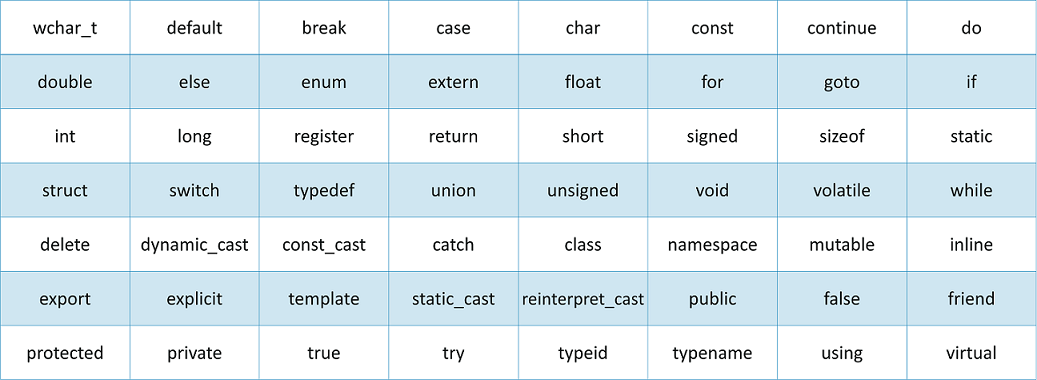
下表列出了 C++ 中的关键字。这些关键字不能作为常量名、变量名或其他标识符名称。
本节主要介绍存储类相关关键字。
存储类定义 C++ 程序中变量/函数的范围(可见性)和生命周期,这些说明符放置在它们所修饰的类型之前。下面列出 C++ 程序中可用的存储类:
- extern
- static
- mutable
- thread_local (C++11)
特别的,从 C++ 11 开始,auto 关键字不再是 存储类说明符,但auto是c++11中非常优雅的关键字。为了更好的说明它的作用,在3.X节中会正式提到它。
1.3.1 extern关键字
extern顾名思义,外面的、外来的。
extern 可以置于变量或者函数前,扩展变量/函数的定义域:
- 第一种情况,首先将声明的变量/函数作用域,从声明扩展到本文件结束;如果依旧未找到定义转情况二。
- 第二种情况,声明变量/函数定义在其它文件中,在链接时会在其它文件寻找其定义(这样在编译时,本文件未找定义也不报错)。
分别举两个例子说明两种情况。
第一种情况,变量在本文件定义
【例1】变量声明后不想立即初始化,在调用后才会进行初始化。如何在调用时就获取正确的值?
使用 extern 关键字对变量c, ch 作“外部变量声明”,使作用域扩展到从声明开始到本文件结束 ,这样编译器就会在本文件其它区域寻找其定义。
1 |
|
输出:
1 | [root@roy-cpp test]# g++ -std=c++11 main.cpp other.cpp -o main.out |
而如果没有使用extern关键字,输出为空(默认初始化的值):
1 |
如果本文件没找到定义,extern还会去其它文件中寻找定义。
第二种情况,变量在其它文件定义
c, ch是在别的文件中声明
【例2】变量
c,ch是在别的.cpp文件中声明的,但又需要在 main 函数中调用它们(引入头文件中也没有它们的定义)。
使用extern关键字声明即可解决,这样编译阶段不会出错,链接时会去寻找它们的定义(如果extern修饰函数/类等效果等同前向声明,3.1.1节)。
-
main.cpp
1
2
3
4
5
6
7
8
9
10
11
12
using namespace std;
// 声明外部变量,头文件中也没有c,ch的定义
extern char c, ch;
int main()
{
cout<<c<<endl;
cout<<ch<<endl;
return 0;
} -
other.cpp
1
char c='h', ch='H';
没使用extern关键字声明编译会出错,使用后编译正常:
1 | g++ -std=c++11 main.cpp other.cpp -o main.out |
输出:
1 | h |
不过这个做法有点刻意,根据我们之前的最佳实践,声明和定义最好分开。变量c, ch 应该声明在.h文件中。
此时extern关键字的作用是告诉编译器, other.h 变量a定义在别处/文件中。
-
main.cpp
1
2
3
4
5
6
7
8
9
10
using namespace std;
int main()
{
cout<<c<<endl;
cout<<ch<<endl;
return 0;
} -
other.h
1
extern char c, ch; // 只声明
-
other.cpp
1
char c='h', ch='H'; // 实际定义
编译正常:
1 | [root@roy-cpp test] |
最佳实践:什么时候使用extern和头文件
引入头文件就可以使用在其它文件的变量/函数/类,为什么还需要extern?
-
extern将声明、定义分离。extern可以用于头文件把全局变量的声明和定义分离,避免重复定义;
-
只需要使用个别其它文件的变量/函数等。有时候我们只想使用头文件定义的个别变量/函数,但是这样不得不引入头文件所有的相关变量/函数等声明。在大项目编译中,过度使用头文件会让编译速度显著变慢。
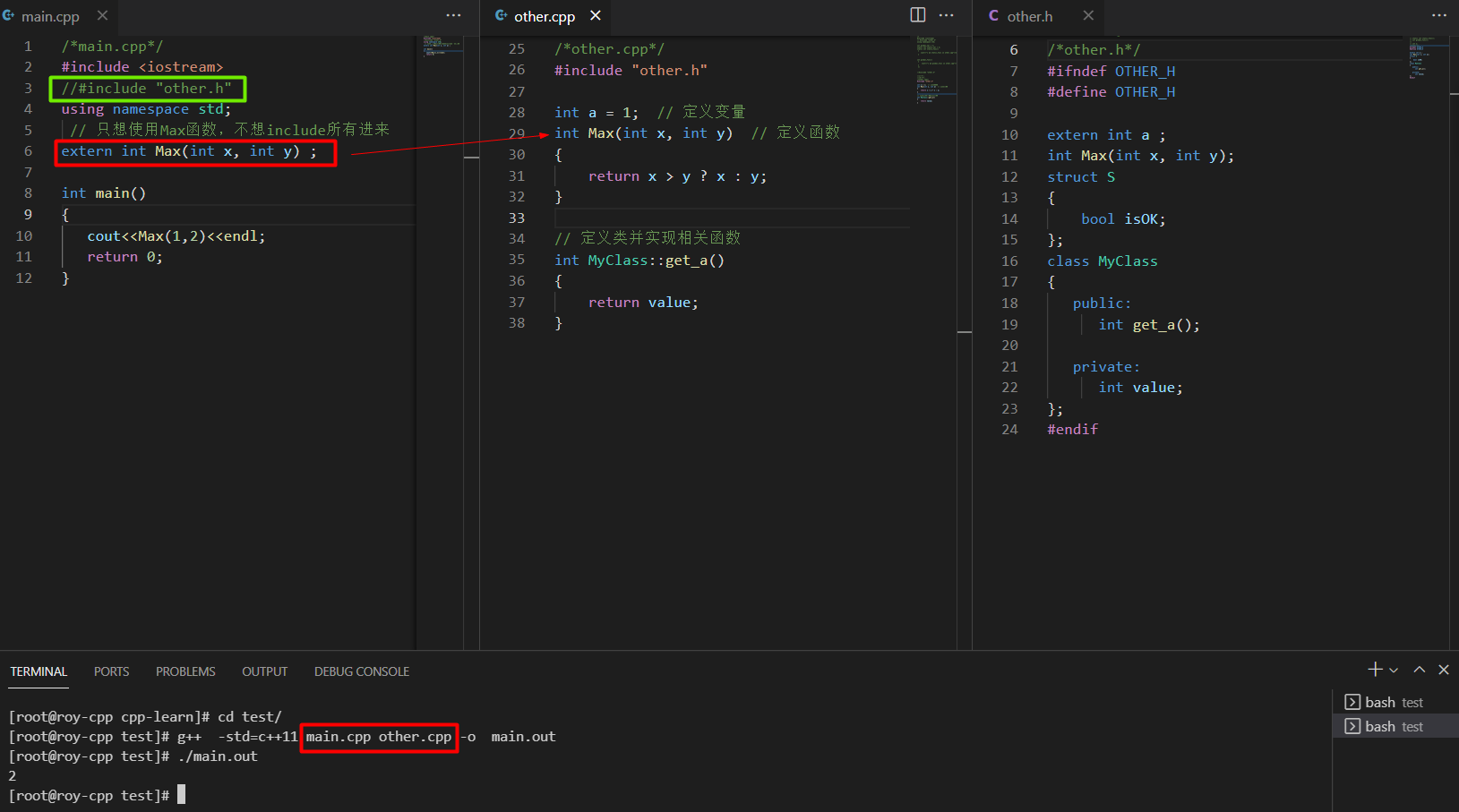
这里我们没有include “other.h” , 因为我们只需要它的
Max函数,使用extern关键字即可。 -
C++和C代码混编时。 下节说明。
extern “C”
extern关键字还可用于extern “C”,使得C和C++混编不会出错,它有两层含义:
- 声明的变量是extern的,它只是在这里声明,定义在别的地方;
- 声明的变量按C方式进行编译。
第2点是本节的核心内容。
⚠️ 以下情况仅在用gcc编译代码时出现,g++编译不会出错(节末解释)。
准备三个文件:a.c、a.h、main.cpp ,在main.cpp中调用a.c中的函数printHello 。
尝试gcc编译:
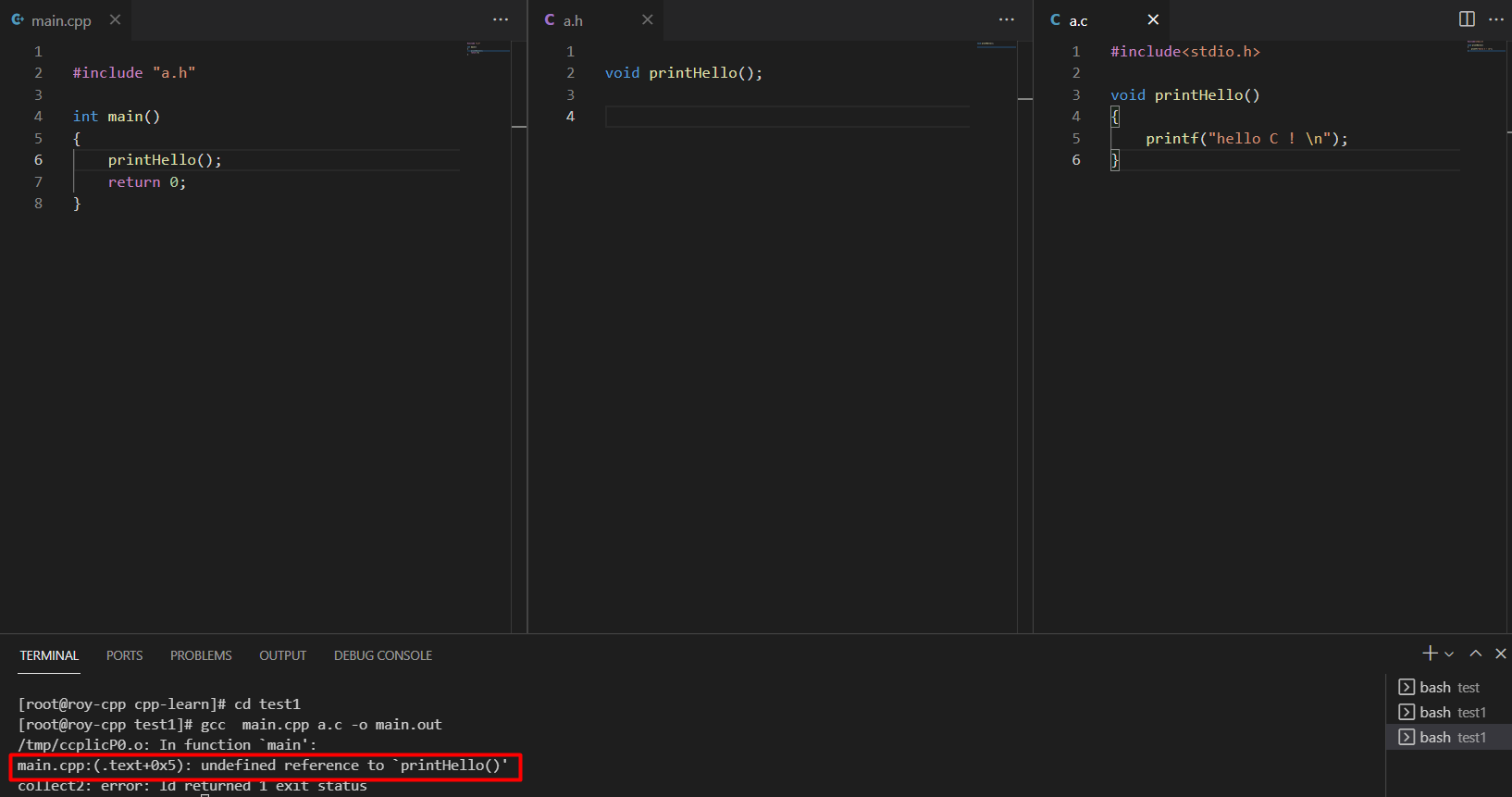
很不幸报错了:
1 | main.cpp:(.text+0x5): undefined reference to `printHello()' |
链接过程中找不到符号 printHello ,为什么会这样?
这是因为gcc 对 cpp和c代码变量的符号处理不同导致的。
我们知道从代码到可执行程序需要经过,预编译→编译→汇编→链接,其中编译和链接大致如下:
- 编译:代码展开、语法检查,还包括将变量转成符号;
- 链接:将未定义的符号,解析重定位到其定义实现的地方。
查看a.o链接前的符号表:
1 | [root@roy-cpp test1]# gcc -c a.c -o a.o |
a.c 编译后的符号名(printHello)和代码中的定义一样。
再查看main.o链接前的符号表:
1 | [root@roy-cpp test1]# nm main.o |
main.cpp 编译后printHello符号名变为_Z10printHellov ,这是什么鬼?
对于C++代码:如果是数据变量并且没有嵌套,符号名也是本身;如果变量名有嵌套(在名称空间或类里)或者是函数名,符号名就会按如下规则来处理。
- 符号以_Z开始;
- 如果有嵌套,后面紧跟N,然后是名称空间、类、函数的名字,名字前的数字是长度,以E结尾;
- 如果没嵌套,则直接是名字长度后面跟着名字;
- 最后是参数列表,
v表示void。
因为main.cpp 的符号_Z10printHellov 是未定义的,它需要解析重定位到定义的地方,也是a.o 中。但显然符号_Z10printHellov 和 printHello 不同,因此链接时在a.o找不到相关符号导致报错,无法正确重定义:
1 | main.cpp:(.text+0x5): undefined reference to `printHello()' |
这个时候extern “C” 就派上用场了:在C++文件指定代码/头文件按C的方式进行编译。
将a.h 修改如下:
1 |
|
再次查看main.o 符号表:
1 | [root@roy-cpp test1]# gcc -c main.cpp -o main.o |
一切正常。整个过程详细变化如下:
-
gcc根据main.cpp文件名后缀识别为cpp文件; -
预编译:将
main.cpp中\#include "a.h"展开,因为cpp文件都会存在宏定义__cplusplus,所以#ifdef __cplusplus成立。最终展开为:1
2
3extern "C"{
void printHello();
} -
编译:编译到 extern “C”{…} 中的变量
printHello按C方式编译成符号printHello。
再次尝试编译也确实正常输出了:
1 | [root@roy-cpp test1]# gcc main.cpp a.c -o main.out |
但是g++编译不使用extern “C”汇编C和C++代码也不会出错 ,因为g++将c或cpp代码都按cpp方式编译。
下面是测试。
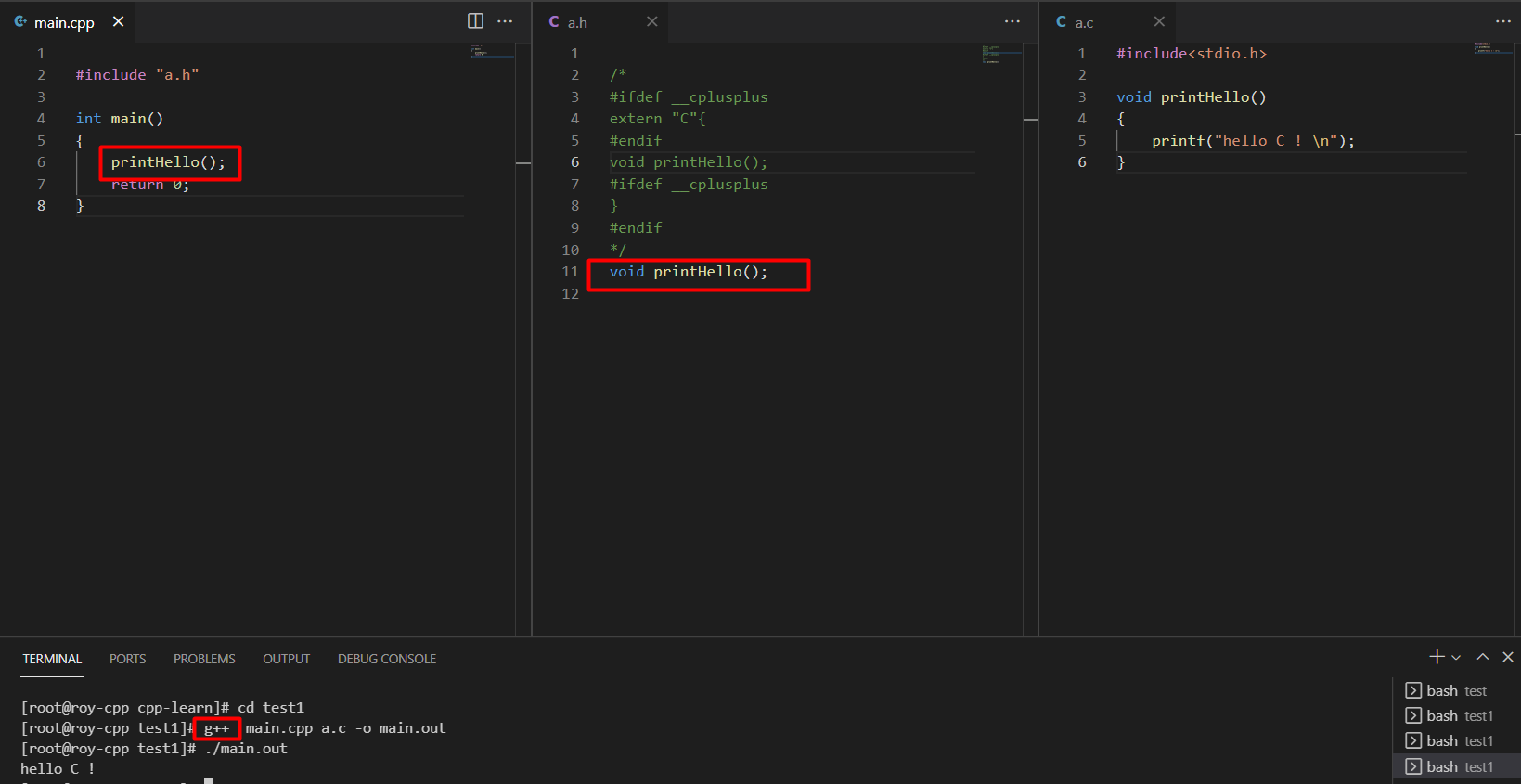
查看此时a.c编译后的a.o 符号表(cpp风格):
1 | [root@roy-cpp test1]# g++ -c a.c -o a.o |
1.3.2 static关键字
static关键字常于各种面试题、书籍中,为什么需要static关键字?为什么它如此重要?
我们从面向过程和面向角度两个角度分析。
面向过程角度
一、作用域隐藏。当一个工程有多个文件的时候,用static修饰的函数或变量只能够在本文件中可见,文件外不可见。
对比全局变量/函数:全局变量/函数访问具有全局性,其它文件通过extern关键字或引用头文件,是可以使用本文件中定义的全局变量/函数。
但有时我们并不希望这样,因为这暴露了我们不想暴露的变量/函数,这个时候static可以更好的限定作用范围。
由此还引申另外一个好处:不同的人编写不同的函数时,不用担心是否会与其它文件中的函数同名,因为同名也没有关系(限定作用范围在本文件内)。
下面我们通过两个小例子来理解。
例子1:静态变量
可以看到,静态static变量即使被extern关键字修饰,依旧不能被其它文件引用。
1 | /*other.cpp*/ |
例子2:静态函数
将静态函数static_func 定义在other.h (实现在other.cpp),无法通过编译:undefined reference to static_func()。
1 | /*other.h*/ |
尝试编译出错:
1 | g++ -std=c++11 main.cpp other.cpp -o main.out |
但如果我们不使用头文件,static_func可以被成功使用?
1 | /*other.cpp*/ |

这是因为此时static_func 已经被视为在同一个文件中。
注意到:
-
头文件
#include "other.cpp",预编译时直接替换为other.cpp中内容, 相当直接在main.cpp定义了static_func。同一个文件中调用静态函数static_func自然是可以的。预编译后的文件如下所示。
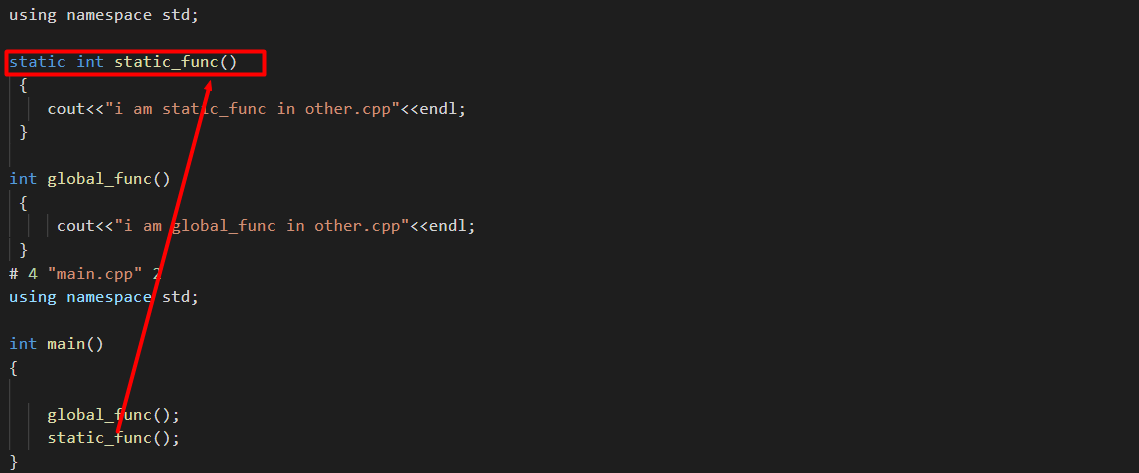
而之前生成的预编译文件是不会包含静态函数的定义(只有头文件
other.h中的静态函数声明),所以实际定义还是在别的文件(other.cpp)中,因此调用时会出错。 -
所以我们在g++编译时都不用把
other.cpp作为源文件(预编译时已经替换了)。
二、全局生命周期。用static修饰的变量或函数生命周期是全局的(即使是局部静态变量),存储在静态数据区(全局数据区)。 即在main函数执行前就会被初始化。
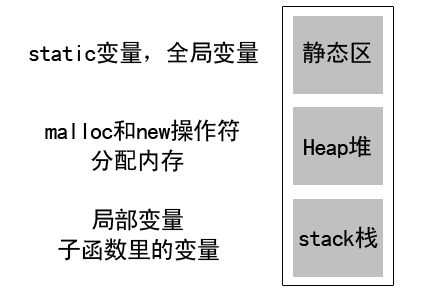
我们举两个实例,来更好的理解“全局生命周期”这个概念。
-
例1,在
normal_add函数中定义了局部变量count,每次函数退出,count也随之销毁。所以每次打印的都是进入函数初始化后的值+1。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
using namespace std;
static int i ; // 全局访问性,全局生命周期
int normal_add()
{
int count = 0; // 局部访问性,局部访问周期
return ++count;
}
int main()
{
for(int j = 0 ; j < 3 ; j++)
cout<< normal_add()<<endl;
return 0;
}
-
例2,在
static_add中定义了局部静态变量count。它只会被初始化一次(内存只被分配一次,见下例解释),随着函数退出也不销毁,保持最新的值。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
using namespace std;
static int i ; // 全局访问性,全局生命周期
int static_add()
{
static int count = 0; // 局部访问性,局部访问周期
return ++count;
}
int main()
{
// 虽然多次(3次)进入了函数static_add
// 但count只在第一次进入函数被初始化了一次
for(int j = 0 ; j < 3 ; j++)
cout<< static_add()<<endl;
}
三、初始化零值。
static修饰的(局部/全局)变量和全局变量一样,不显示定义时会进行零值初始化。
面向对象角度
一、类只拷贝一份。类中static修饰的静态数据成员或静态成员函数是属于类的,所有对象只有一份拷贝,因此它的值可以被所有对象更新,在类未实例化就可以使用。
特别的, static类对象必须要在类外进行初始化,因为static修饰的变量先于对象存在。
1 |
|
这种特性可以很好的实现类多个对象的变量共享。
在后面面对对象笔记中,有机会我们还会更深入探讨下static的用法,比如与虚函数的关系。
最后,总结下全局变量和静态变量。
全局变量/函数和static变量/函数的区别?
- 存储方式。全局变量/函数和static变量/函数都是静态存储方式,存储在全局数据区。
- 作用域。全局变量/函数是可见性全局性,其它文件中可通过extern关键字/引用头文件,来进行使用,但静态变量/函数只能在本类使用。
- 初始化。staic变量/函数只被初始化一次,但全局变量则不然可以被初始化多次。
- 面对对象。类静态成员、函数只被拷贝一份,为全对象共享。
1.4 常量
在前面我们认识的“变量”,即意为“变化可被修改的值”,灵活性强。
在C++中还存在“常量”,即“不希望被修改的值”,定义以后无法被修改。
如何定义一个常量?
1.4.1 定义常量
🖋 把常量定义为大写字母形式,是非常好的编程实践。
在 C++ 中,有两种简单的定义常量的方式:
-
使用 #define 预处理器。
1
-
使用 const 关键字。
1
const type NAME = value;
以下是更多的实例(以const关键字定义为例)。请注意不同数据类型常量定义的区别。
1.4.2 常量类型
-
整数常量
整数常量可以是十进制、八进制或十六进制的常量。前缀指定基数:0x 或 0X 表示十六进制,0 表示八进制,不带前缀则默认表示十进制。
整数常量也可以带一个后缀,后缀是 U 和 L 的组合,U 表示无符号整数(unsigned),L 表示长整数(long)。
1
2
3
4
5
6
7
8
9
10
11
12
13
using namespace std;
int main()
{
const int VALUE = 123;
const int VALUE = 123L; // 自动转换为long类型
const int VALUE = 123u; // 自动转换为unsiged int类型
const int VALUE = 0x123; // 16进制
const int VALUE = 0123; // 8进制
return 0;
} -
浮点常量
浮点常量由整数部分、小数点、小数部分和指数部分组成。
以下仅给出关键代码。
1
2const float VALUE = 3.14159;
const float VALUE = 314159e-5; // 使用科学计数法 -
布尔常量
布尔常量共有两个,即true和false。
以下仅给出关键代码。
1
2const bool VALUE = true;
const bool VALUE = false;我们不应把 true 的值看成 1,把 false 的值看成 0。即如下定义通常不建议进行:
1
2
3// 不建议的做法
const bool VALUE = 1;
const bool VALUE = 0; -
字符常量
字符常量是括在单引号中。
字符常量可以是一个普通的字符(例如 ‘x’)、一个转义序列(例如 ‘\t’),或一个通用的字符(例如 ‘\u02C0’)。
以下给出关键代码进行示例。
1
2
3const char VALUE = 'X'; // 普通字符
const char VALUE = '\n'; // 转义字符,即换行符
const char VALUE = '\u02C0'; // 通用字符,打印输出 -
字符串常量
字符串字面值或常量是括在双引号 “” 中的。一个字符串包含类似于字符常量的字符:普通的字符、转义序列和通用的字符。
1
2
3const string VALUE = "\n"; // 转义字符,即换行符
const string VALUE = "\u02C0"; // 通用字符,打印输出
const string VALUE = "hello world";
1.4.3 const 和constexpr
C++11 引入了一个关键字常量表达式constexpr,它确保变量必须在编译时被初始化,而const修饰的变量可以在编译时或运行时被初始化。
换句话说,constexpr 语义才是真正意义上的常量,运行时不能初始化。
1 |
|
上述代码编译出错:
1 | [root@roy-cpp test]# g++ -std=c++11 test.cpp -o test.out |
constexpr有什么好处?
constexpr 可以显示地告诉编译器表示式是确定值且可以被优化,const 修饰的编译器只能隐式跟踪是运行时常量还是编译时常量。
比如上述代码:
1 | const int i = 0; // 修改为常量 |
由于i也是常量,表达式int j = i + 1显然也一定会是常量。我们由此可以显示声明为constexpr,这样表达式会被编译器大胆地在编译期进行优化,提高编译速度。
在对性能要求苛刻的高并发场景,constexpr是个不错的选择。
1.4.4 define & const & 函数 🌟
define宏定义和const的区别?
- 文本替换:define是在编译的预处理阶段起作用,属于文本插入替换;而const是在编译、运行的时候起作用;
- 类型检查:define只做替换,不做类型检查和计算,也不求解,容易产生错误;const常量有数据类型,编译器可以对其进行类型安全检查;
- 内存占用:define只是将宏名称进行替换,在内存中会产生多分相同的备份。const在程序运行中只有一份备份,且可以执行常量折叠,能将复杂的的表达式计算出结果放入常量表;
- 空间分配:宏定义的数据没有分配内存空间,只是插入替换掉;const定义的变量只是值不能改变,但要分配内存空间。
define宏定义和函数的区别?
-
文本替换:define是在编译的预处理阶段起作用,属于文本插入替换;函数调用在运行时需要跳转到具体调用函数;
-
类型检查:define只做替换,不做类型检查和计算,也不求解,容易产生错误;函数参数具有类型,需要检查类型;
-
其它:函数有返回值,在最后不用加分号。
1.5 运算符
运算符是一种告诉编译器执行特定的数学或逻辑操作的符号。
除了常见的:算术运算符、关系运算符、逻辑运算符、位运算符、赋值运算符外,我们先来看看其它的一些重要运算符。
| 运算符 | 描述 | 备注 |
|---|---|---|
sizeof |
sizeof 运算符一个对象或类型所占的内存字节数。 | 重要,4.1.3节给出具体示例 |
Condition ? X : Y |
条件运算符。如果 Condition 为真 ? 则值为 X : 否则值为 Y。 | |
.、 -> |
成员运算符用于引用类、结构和共用体的成员。 | |
Cast |
强制转换运算符把一种数据类型转换为另一种数据类型。 | 4.X节详述 |
& |
取地址运算符 & ,可获取变量的地址。例如 ,int var =3; int *ptr=&var,获取变量var的地址。 |
|
* |
间接寻址运算符 *, 获取指定地址的变量的值。例如,int val = *ptr ,此时var=3。 |
1.5.1 运算符汇总
该小节详细列出各类运算符,仅为查表用。读者可略过。
非特别说明,下例中假设变量 A 的值为 10,变量 B 的值为 20。
-
算术运算符
运算符 描述 实例 把两个操作数相加 A + B 将得到 30 - 从第一个操作数中减去第二个操作数 A - B 将得到 -10 * 把两个操作数相乘 A * B 将得到 200 / 分子除以分母 B / A 将得到 2 % 取模运算符,整除后的余数 B % A 将得到 0 ++ 自增运算符,整数值增加 1 A++ 将得到 11 – 自减运算符,整数值减少 1 A-- 将得到 9
-
关系运算符
运算符 描述 实例 == 检查两个操作数的值是否相等,如果相等则条件为真。 (A == B) 不为真。 != 检查两个操作数的值是否相等,如果不相等则条件为真。 (A != B) 为真。 > 检查左操作数的值是否大于右操作数的值,如果是则条件为真。 (A > B) 不为真。 < 检查左操作数的值是否小于右操作数的值,如果是则条件为真。 (A < B) 为真。 >= 检查左操作数的值是否大于或等于右操作数的值,如果是则条件为真。 (A >= B) 不为真。 <= 检查左操作数的值是否小于或等于右操作数的值,如果是则条件为真。 (A <= B) 为真。
-
逻辑运算符
假设变量 A 的值为 1,变量 B 的值为 0。
运算符 描述 实例 && 称为逻辑与运算符。如果两个操作数都非零,则条件为真。 (A && B) 为假。 || 称为逻辑或运算符。如果两个操作数中有任意一个非零,则条件为真。 (A || B) 为真。 ! 称为逻辑非运算符。用来逆转操作数的逻辑状态。如果条件为真则逻辑非运算符将使其为假。 !(A && B) 为真。
-
位运算符
p q p & q p | q p ^ q 0 0 0 0 0 0 1 0 1 1 1 1 1 1 0 1 0 0 1 1
-
赋值运算符
运算符 描述 实例 = 简单的赋值运算符,把右边操作数的值赋给左边操作数 C = A + B 将把 A + B 的值赋给 C += 加且赋值运算符,把右边操作数加上左边操作数的结果赋值给左边操作数 C += A 相当于 C = C + A -= 减且赋值运算符,把左边操作数减去右边操作数的结果赋值给左边操作数 C -= A 相当于 C = C - A *= 乘且赋值运算符,把右边操作数乘以左边操作数的结果赋值给左边操作数 C *= A 相当于 C = C * A /= 除且赋值运算符,把左边操作数除以右边操作数的结果赋值给左边操作数 C /= A 相当于 C = C / A %= 求模且赋值运算符,求两个操作数的模赋值给左边操作数 C %= A 相当于 C = C % A <<= 左移且赋值运算符 C <<= 2 等同于 C = C << 2 >>= 右移且赋值运算符 C >>= 2 等同于 C = C >> 2 &= 按位与且赋值运算符 C &= 2 等同于 C = C & 2 ^= 按位异或且赋值运算符 C ^= 2 等同于 C = C ^ 2 |= 按位或且赋值运算符 C |= 2 等同于 C = C | 2
1.5.2 运算符优先级
不同运算符在编译时优先级是不同的。
- 例如 x = 7 + 3 * 2,在这里,x 被赋值为 13,而不是 20,因为运算符 * 具有比 + 更高的优先级,所以首先计算乘法 3*2,然后再加上 7。
列出所有优先级比较,供需要时查表所用。读者不应过分关注下面细节。
| 类别 | 运算符 | 结合性 |
|---|---|---|
| 后缀 | () [] -> . ++ - - | 从左到右 |
| 一元 | + - ! ~ ++ - - (type)* & sizeof | 从右到左 |
| 乘除 | * / % | 从左到右 |
| 加减 | + - | 从左到右 |
| 移位 | << >> | 从左到右 |
| 关系 | < <= > >= | 从左到右 |
| 相等 | == != | 从左到右 |
| 位与 AND | & | 从左到右 |
| 位异或 XOR | ^ | 从左到右 |
| 位或 OR | | | 从左到右 |
| 逻辑与 AND | && | 从左到右 |
| 逻辑或 OR | || | 从左到右 |
| 条件 | ?: | 从右到左 |
| 赋值 | = += -= *= /= %=>>= <<= &= ^= |= | 从右到左 |
| 逗号 | , | 从左到右 |
1.6 循环
循环语句允许我们多次执行一个语句或语句组,下面是大多数编程语言中循环语句的一般形式:
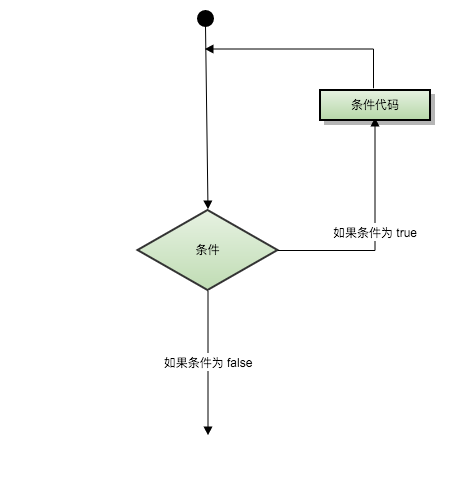
1.6.1 快速入门
C++ 编程语言提供了以下几种循环类型。点击链接查看每个类型的细节。
| 循环类型 | 描述 |
|---|---|
| while 循环 | 当给定条件为真时,重复语句或语句组。它会在执行循环主体之前测试条件。 |
| for 循环 | 多次执行一个语句序列,简化管理循环变量的代码。 |
| do…while 循环 | 除了它是在循环主体结尾测试条件外,其他与 while 语句类似。 |
| 嵌套循环 | 可以在 while、for 或 do…while 循环内使用一个或多个循环。 |
循环控制语句更改执行的正常序列。
| 控制语句 | 描述 |
|---|---|
| break 语句 | 终止 loop 或 switch 语句,程序流将继续执行紧接着 loop 或 switch 的下一条语句。 |
| continue 语句 | 引起循环跳过主体的剩余部分,立即重新开始测试条件。 |
| goto 语句 | 将控制转移到被标记的语句。但是不建议在程序中使用 goto 语句。 |
1.6.2 循环判断
C++ 编程语言提供了以下类型的判断语句。
| 语句 | 描述 |
|---|---|
| if 语句 | 一个 if 语句 由一个布尔表达式后跟一个或多个语句组成。 |
| if…else 语句 | 一个 if 语句 后可跟一个可选的 else 语句,else 语句在布尔表达式为假时执行。 |
| 嵌套 if 语句 | 您可以在一个 if 或 else if 语句内使用另一个 if 或 else if 语句。 |
| switch 语句 | 一个 switch 语句允许测试一个变量等于多个值时的情况。 |
| 嵌套 switch 语句 | 您可以在一个 switch 语句内使用另一个 switch 语句。 |
1.6.3 ?: 运算符
条件运算符在实际编码中,用来替代 if…else 语句。因为很多时候可以简化代码,用的比较多。
1 | Exp1 ? Exp2 : Exp3; |
1.6.4 无限循环
如果条件永远不为假或不存在时,则循环将变成无限循环。
1 |
|
按 Ctrl + C 键可以终止一个无限循环。
1.7 数组
存储一个由相同类型元素构成的顺序集合,称之为数组。
1.7.1 静态数组
静态数组声明且未初始化时必须确定数组大小,否则会报错。
- 初始化:可以使用列表
{...}快速赋值,不可使用new int[]{...}赋值(这是指针分配空间的方式)
1 |
|
1.7.2 动态数组
声明静态数组很简单,但很多时候我们更希望申请一个动态数组(比如声明时并不确定数组的内容)。
动态数组可以声明时不指定大小 ,但是使用前一定要分配空间(可不初始化,会默认初始化)。
-
初始化:可使用
new int[]{...}赋值,不可以使用列表{...}快速赋值 -
删除:注意是使用
delete[],不是delete
1 | int main() |
1.7.3 数组默认初始化
在前面,我们了解到了局部变量/全局变量/静态变量/类成员的默认初始化值。数组的默认初始化值会什么呢?
经过实验,数组默认初始化规则,基本等同局部变量/全局变量/静态变量/类成员的规则。只不过数组是以集合形式出现的。
| int/float/double | bool | string/char | 指针 | 引用 | |
|---|---|---|---|---|---|
| 局部变量 | 野值 | 0 | "",'' |
野值 | 出错 |
| 全局变量/静态变量 | 0 | 0 | "",'' |
0 | 出错 |
| 类成员 | 野值 | 野值 | "",野值 |
""/野值 |
出错 |
| 局部数组(其它同) | 野值 | 野值 | "",'' |
野值 | 出错 |
但是很多时候我们希望给(局部)数组进行初始化(比如0值)。如果数组很长,你肯定不希望逐个进行初始化化,虽然可以用循环但看起来也不那么聪明的样子。
让我们看看初始化数组的技巧。
1 |
|
1.7.4 数组不是指针
在前面数组和动态数组(指针方式)不同初始化方式(指针需要new分配),你也应该隐隐约约感受到指针和数组是两个不同的东西。虽然很多时候数组会退化为指针使用,但将数组视为指针这是不对的。
比如,静态数组一旦初始化是不能重新赋值的,但是动态数组可以。
1 | int arr1[3] = {1,2,3}; |
那么,数组和指针究竟有哪些不同?它什么时候退化为指针?怎么去更深层次的理解?
这些东西不适合放在这里详细讲解,因为你还不具备很多相关知识。请参考:2.1.3#指针和数组。
1.7.5 数组小结🌟
下面我们总结一下数组常用声明、初始化方式。
【注1】仅以一维数组为例。
【注2】动态数组记得使用delete[]释放空间。
| 声明 | 显示初始化 | 快速初始化 | |
|---|---|---|---|
| 静态数组 | int arr[LEN]; | int arr[LEN]={…}; int arr[]={…}; int arr[]{…}; |
int arr[LEN]={0}; fill(arr,arr+LEN,0); |
| 动态数组 | int* arr; int* arr = new int[LEN]; |
int arr = new int[LEN]{…}* | int* arr = new int[LEN](); fill(arr,arr+LEN,0); |
1.8 字符串
1.8.1 C风格字符串
在C中我们使用字符串其实是字符数组。
| 用字符数组存放 | 用字符指针管理串 |
|---|---|
| char str1[ ]=“royhuang”; | char *str2=“hwh”; |
-
char字符数组
定义一个C 风格的字符串:
1
char my_name[] = "royhuang" ;
猜猜
my_name的长度?8?不,是9。因为C风格的字符串还会自动在末尾添加一个终止符,即:royhuang\0。1
sizeof(my_name)/sizeof(my_name[0]); // 9
strlen可以忽略空字符:1
strlen(my_name); // 8
C风格字符数组,无法二次重新赋值,但数组存储的内容可以被修改。
下面举例说明。
数组不能重新赋值:
1
my_name = "hwh"; // error,无法被修改
数组存储的内容可以被修改:
1
2my_name[0]='z'
cout<<my_name; // zoyhuang -
指针数组
定义一个指针数组:
1
char* my_name = "royhuang" ;
如果你对指针有所了解,一定会纳闷:指针都没给它分配指向的空间,怎么就可以存入char数组?
下面才符合我们之前对动态数组的认知:
1
2
3
4
5
6
7
8
9
10
11
12
13
14// C风格动态数组
// malloc分配空间
char* my_name = (char*)malloc(10*sizeof(char));
// for赋值
for(int i=0 ; i<10 ; i++) // for循环赋值
{
my_name[i]='';
}
/*
// C++风格
// new分配空间,还可以同时初始化
char* my_name = new char[10]{"royhuang"};
*/这一切都要感谢编译器的“幕后工作”:
1
char* my_name = "royhuang" ; // 发生了什么?
等价于:
-
编译器首先在常量区分配一个字符数组(可以看做是匿名数组),这里假设为
tmp_my_name;1
char* tmp_my_name[] = "royhuang\0";
题外话,正因为"royhuang\0"保存在常量区(只读),所以上述方式分配的动态数组无法修改:
1
my_name[0] = 'z'; // 错误,尝试修改常量区的值
-
然后将
tmp_my_name拷贝给my_name:1
2
3// my_name 并没有分配空间
// 只是保存了数组(首元素)地址
my_name = tmp_my_name;题外话,正因为
my_name只是保存了数组地址(本质是指针,而不是数组),所以动态数组可以重新改变指向。1
my_name = "hwh"; // ok
-
-
常用方法
C++提供了
cstring.h供我们操作C字符串(不适用std::string!),这里给出一些常用方法:1
2
3
4
5
6
using namespace std;
char source[]="royhuang";
char dest[5];-
复制字符串
下面这种方式容易造成溢出:
1
strcpy(dest, source); // 溢出 > 5
c中建议使用
strncpy,C++11则首选strcpy_s:1
2
3
4
5
6
7// 确保编译器支持此函数,需要先define
// linux下strcpy_s无法使用,使用strncpy
// strncpy(dest, source, 5);
strcpy_s(dest, 5, source);
cout<<dest<<endl;输出:
1
royhu
-
长度和容量
1
2
3char name[10] = "royhuang";
strlen(name) ; // 7,不包含终止符
size(name); // 10 -
其它有用的方法
- strcmp() :比较两个字符串(如果相等则返回 0 );
- strncmp() : 比较两个字符串到特定数量的字符(如果相等则返回 0);
- strcat() : 将一个字符串附加到另一个(危险);
- strncat() :将一个字符串附加到另一个字符串(带缓冲区长度检查)。
-
-
最佳实践
C风格的字符串通常使用麻烦:合并字符串不方便、
char*需管理内存分配、不自动增长需考虑越界的问题等。因此在C++中最佳字符串实践:
- 不建议使用C风格的字符串,请尽量使用
std::string; - 如果一定要使用,请使用有固定缓冲区大小的 C 样式字符串。
认识下
std::string究竟有何般魔力吧。 - 不建议使用C风格的字符串,请尽量使用
1.8.2 string初识
std::string 是什么?
C++ 支持两种不同类型的字符串:std::string(作为标准库的一部分)和 C 风格的字符串(从 C 语言继承而来)。
std::string 是使用 C 风格的字符串实现的,参考:C++ string 源码实现对比 。
可以看到 string 其实就是 basic_string<char>,通过 basic_string 可以构造出不同字符类型的字符串类型。比如 wstring 就是 basic_string<wchar_t>。
1 | typedef basic_string<char> string; |
也就是说std::string是一个对象,不是数组。
在c++中可以通过 #include <string> 引入字符串std::string 。
1 |
|

std::string 好在哪里?
回忆我们提到的C风格字符串缺点:
C风格的字符串通常使用麻烦:合并字符串不方便、
char*需管理内存分配、不自动增长需考虑越界的问题等。
std::string 则不存在这些问题:
-
合并字符串方便:string内置
append方法和重载了+操作符。1
2
3string s1 = "royhuang";
s1.append("cqu"); // royhuangcqu
s1 = s1+"1996"; // royhuangcqu1996 -
无需管理内存 。使用
char*需要显示使用delete[]删除内存,string会自动管理。 -
自动动态增长。同上:
1
s1.append("cqu"); // 字符串长度自动增长
1.8.3 string转换为C风格
实际编码中,总有或多或少的原因,我们要将string转换为C风格字符串(C风格字符串如何转换为string在下一节:string常用方法介绍)。
了解一下吧。
-
c_str()方法原型:
const char* string::c_str () const。1
2string sSource{ "abcdefg" };
sSource.c_str(); -
data()方法原型:
const char* string::data () const。1
2string sSource{ "abcdefg" };
sSource.data(); -
copy()方法原型:
size_type string::copy(char *szBuf, size_type nLength, size_type nIndex = 0) const。1
2
3string sSource{ "sphinx of black quartz, judge my vow" };
char szBuf[20];
sSource.copy(szBuf, 5, 10);输出:
1
black
继续看看string更多的用法吧。
1.8.4 string常用方法
字符串是编程中经常要处理的,这里列出常用的方法供熟悉和查阅。
为了尽量简洁,下面仅给出关键性代码。
注意初始化string的只能是常量(const)类型。
当然你可能见过最简单的方法,使用操作符= 来初始化字符串。
1 | string str = string("royhuang"); |
当然,你还可以用C风格的字符串,也就是C风格字符串如何转换为string。
1 | string str = "royhuang"; // 字符串 |
这里= 是重载过后的运算符。现在我们来了解一下:如何通过构造函数进行初始化。
-
string()方法原型:string::string()。创建一个空字符串。
1
2// 空串,默认初始化
string sSource; -
string::string(const string& strString)
此构造函数创建一个新字符串作为 strString 的副本。
1
2
3
4
5
6
7// 指定字符串值初始化
string sSource{ "my string" };
string sNewSource{ sSource };
// 特别的,还接受char* szCString 类型作为参数
const char *szSource{ "my string" };
string sNewSource{ szSource }; -
string::string(const char szCString)*
使用常量C风格字符串初始化。
1
2const char *szSource{ "my string" };
string sOutput{ szSource }; -
string::string(const string& strString, size_type unIndex, size_type unLength)
创建一个新字符串,最多包含 strString 中的 unLength 字符,从索引 unIndex 开始。如果遇到 NULL,即使未达到 unLength,字符串复制也会结束。
1
2
3
4
5
6
7
8// 截取指定长度初始化
string sSource{ "my string" };
string sOutput{ sSource, 3 };
std::cout << sOutput<< '\n'; // string
std::string sOutput2(sSource, 3, 4);
std::cout << sOutput2 << '\n'; // stri -
想用非字符串类型初始化?
如果你尝试用非字符类型串初始化,比如数字:
1
string sFour{ 4 };
会报错:
无法将参数 1 从“int”转换为“std::basic_string”。也就是说试图将int转换为string失败了。有什么好办法吗?好办法就是我们先将非string类型,比如上文int类型,转换为string。
好吧,果然是经典废话大师。具体来说我们是使用
std::ostringstream类来转换为string类型。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
using namespace std;
template <typename T>
inline std::string ToString(T tX)
{
// 初始化-->读入-->调用str方法
ostringstream oStream;
oStream << tX; // tX加入到流中
return oStream.str();
}
int main()
{
string sFour{ ToString(4) };
string sSixPointSeven{ ToString(6.7) };
string sA{ ToString('A') };
cout << sFour << '\n'; // 4
cout << sSixPointSeven << '\n'; // 6.7
cout << sA << '\n'; // A
}好了,知道你一定求知若渴:那string类型怎么转换为其它类型呢?类似的,我们使用std::istringstream。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
using namespace std;
template <typename T>
inline bool FromString(const std::string& sString, T &tX)
{
// 初始化-->写入-->调用str方法
istringstream iStream(sString);
// 将流中数据写入到tX中
return !(iStream >> tX).fail(); // extract value into tX, return success or not
}
int main()
{
double dX;
FromString("3.4", dX)
FromString("ABC", dX)
}
-
重载符号[]
1
2string sSource{ "abc" };
sSource[2] = 'D'; // abD -
at() 方法
相比性能较慢,因为它会对传入的参数
index进行异常检查。但是相对的,如果你不确定传入的index是否有效:just use it.
1
2string sSource{ "abc" };
sSource.at(2) = 'D'; // abD
-
size_type string::length() const 和 size_type string::size() const
两个函数都可以返回字符串中的当前字符数,不包括空终止符。
1
2
3string source{ "012345678" };
source.length() // 9
source.size() // 9 -
bool string::empty() const
如果字符串没有字符则返回真,否则返回假。
1
source.empty() // false
-
size_type string::capacity() const
注意,length()方法返回的是实际存储的字符数量,但是capacity()方法返回的编译器给string类型初始化分配的容量大小。
编译器一般会为用户提供了一些缓冲空间,所以一般。
1
2
3string s { "012345678" };
s.length() ; // 9
s.capacity() ; // 16为什么要这么做?
考虑这么一种情况,你初始化了一个字符串
str,length()=8。如果你在后面还继续串联构造更大字符串,这个时候每串联一次编译器就要重新分配str大小。1
2
3
4
5
6
7
8
9
10
11
12
13
14
int main()
{
string str{}; // length 0
for (int count{ 0 }; count < 16; ++count)
str += 'a';
cout << str;
}当串联的次数过多时,显然这会对性能造成较大的影响。所以更更聪明的做法,除了系统默认分配更大的容量,还可以自定义提前reserve分配更大的容量。
-
void string::reserve(size_type unSize)
提前分配更大的容量。
1
str.reserve(16);
定义公共代码如下。
1 | string sStr1("red"); |
-
交换两个字符串
void swap (string &str1, string &str2)。
1
swap(sStr1, sStr2);
-
追加字符串
string& string::operator+= (const string& str)。
1
sStr1 += sStr2 ; // 新字符串:redblue
或者使用append()方法,效果一样。
1
sStr1.append(sStr2)
特别对于C风格字符串,如下。
-
+=/append方式要求都是常量!
1
2
3
4string sString("one");
// " two"、" three"都是C风格字符串
sString += " two";
sString.append(" three"); -
push_back,仅限字符不要求是常量,如下:
1
2
3
4
5string sString("one");
sString += ' ';
sString.push_back('2');
cout << sString << endl;输出:
1
one 2
-
-
插入字符串
string& string::insert (size_type index, const string& str)。
1
sStr1.insert(2,sStr2); // reblued
当然也可以插入C风格字符串,但是只能是常量字符串。
1
sStr1.insert(2,"hwh");
-
比较
常用方法如下。
方法 作用 ==, != 比较两个字符串是否相等/不相等(返回 bool) <, <=, > >= 比较两个字符串是否小于/大于彼此(返回 bool) compare() 比较两个字符串是否相等/不相等(返回 -1、0 或 1) -
子串
见下。
方法 作用 + 子串相加 substr() 获取子串 -
搜索
大致如下。
方法 作用 find() 查找第一个字符/子串 find_first_of() 查找指定搜索字符的第一次出现位置的索引 find_last_of() 查找指定搜索字符的最后一次出现位置的索引
1.8.5 输入输出流
在本笔记中,“流(stream)”一词会被大量提到。不可避免的,我们先来了解下其基本概念。
-
什么是流?
抽象地说,流只是一个可以顺序访问的字节序列。随着时间的推移,流可能会产生或消耗无限量的数据。
以我们通常处理的输入流和输出流为例。
- 输入流:保存来自数据生成器(例如键盘、文件或网络)的输入。例如,保存用户当前键盘的输入。
- 输出流:用于保存特定数据使用者的输出,例如监视器、文件或打印机。将数据写入输出设备时,该设备可能尚未准备好接受该数据——例如,当程序将数据写入其输出流时,打印机可能仍在预热。数据将位于输出流中,直到打印机开始使用它。
-
C++中的输入、输出流
- istream类是与输入流处理时的主类。对于输入流,提取运算符 (>>)用于从流中删除值。
- ostream类是与输出流处理时的主类。对于输出流,插入运算符 (<<)用于将值加入流中。
当然,C++已经预定义好四个标准流对象,我们可以直接使用它们:
- cin :标准输入流对象(通常是键盘);
- cout :标准输出流对象(通常是监视器);
- cerr :标准错误输出流对象(通常是监视器),提供无缓冲输出;
- clog :标准错误输出流对象(通常是监视器),提供缓冲输出。
无缓冲输出通常被立即处理,而缓冲输出通常作为块存储和写出。因为 clog 不经常使用,所以经常从标准流列表中省略它。
-
istream最佳实践
-
(C风格)使用setw避免缓存区溢出
使用提取运算符
>>从输入流中读取信息,第一个常见问题便是要避免缓冲区溢出。尤其是在C风格的字符串中,这应该成为你的肌肉反应。1
2char buf[10];
cin>>buf; // 输入:12345678910- 流程:上例中,输入流中存在:12345678910,cin每次读取一个字符串放入buf中,遇到空格、制表符、换行符才会终止。
但由于你的小调皮,输入了超过10个字符。因为这超过了缓存预定大小(10),很不幸发生了Segmentation fault。
正确的做法应该是,我们要限制从流中读取的最大字符数(小于10),然后再放入buf中。
1
2
3
4
5
char buf[10];
cin>>setw(10)>>buf;
cout<<buf;现在程序只读取流中的前 9 个字符(为终止符留出空间)。任何剩余的字符都将留在流中,等待下一次提取。
1
123456789
-
(C风格)使用getline读取整行
如前提到,cin如果遇到:空格、制表符、换行符,就会自动停止提取。比如:
1
2
3
4
5
char buf[20];
cin>>setw(20)>>buf; // 输入:i am royhuang
cout<<buf;输出结果却不如意:
1
i
当然,聪明的你想到直接用循环读取字符:遇到空格、制表符等开始下一个循环,直至遇到
\n才结束循环。1
2
3char buf[20];
int i=0;
while (cin>>buf[i++]);输出结果:
1
i am royhuang
但上面的方式存在两个问题:1)循环不够优雅;2)没有限制输入字符最大长度。
为此,你说可以使用get方法。
1
2char buf[20];
cin.get(buf,20);看上去一切都很美好。但是这里忽略了一个问题,换行符
\n还在流中。请看下例。
1
2
3
4
5
6
7char buf[20];
cin.get(buf,20);
cout<<buf<<endl;
char company[10];
cin.get(company,10);
cout<<company<<endl;company还未来得及输入,便结束:

使用getline可读入换行符:
1
2
3
4
5
6
7char buf[20];
cin.getline(buf,20); // \n 也并读入
cout<<buf<<endl;
char company[10];
cin.get(company,10);
cout<<company<<endl;一切正常了。

-
-
(string)std::string+cin
和前面C风格字符串读取大同小异,不过C++中使用的是标准库中
std::get和std::getline函数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
using namespace std;
int main()
{
// 虽然uni初始化为空串,但是赋值后超过长度(length)会自动增长容量(capacity)
string name{};
cout<< "input your name: ";
cin>>name;
string uni{};
cout<< "input your university: ";
getline(cin,uni);
cout<< "your university is: "<<uni<<endl;
return 0;
}出现前述类似读入
\n问题:
我们输入
royhuang并按下回车时,等于输入了royhuang\n:royhuang被正确赋值给name,但是\n留在了缓冲区等待下一次cin读取。下一次的cin还没等我们再次输入,便发现了缓冲区\n就完成此次读取了。我们有两个办法解决这个问题:
- 提前读入
\n:第6行cin>>name;替换—>getline(cin,name);; - 忽略
\n:第13行getline(cin,uni);—>getline(cin>>ws,uni);,ws表示忽略前面的空白字符。
好了,世界又好起来了。

- 提前读入
-
其它有用的istream函数
- ignore()丢弃流中的第一个字符。
- ignore(int nCount)丢弃前 nCount 个字符。
- peek()允许您从流中读取字符,而无需将其从流中删除。
- unget()将读回的最后一个字符返回到流中,以便下次调用时可以再次读取。
- putback(char ch)允许您将您选择的字符放回流中以供下一次调用读取。
这个小节主要如何 iostream 输出类 (ostream) 格式化输出内容。
-
前缀正数+
std::ios::showpos:如果设置,则用 + 前缀正数。
1
cout << showpos << 5 << '\n';
输出:

-
bool标识
std::ios::boolalpha:如果设置,布尔值打印“真”或“假”。如果未设置,布尔值打印 0 或 1。
1
cout << boolalpha << true << " " << false << '\n';
输出:

-
科学计数法
1
cout << uppercase << 12345678.9 << '\n';
输出:

-
10/2/8/进制
1
2
3cout << hex << 11 << '\n';
cout << dec << 11 << '\n';
cout << oct << 11 << '\n';输出:

-
设置宽度、填充字符、对齐方式
1
2
3
4
5cout << -12345 << '\n';
cout << setw(10) << -12345 << '\n';
cout << setw(10) << left << -12345 << '\n';
cout << setw(10) << right << -12345 << '\n';
cout << setw(10) << internal << -12345 << '\n';输出:
1
2
3
4
5-12345
-12345
-12345
-12345
- 12345
更新记录
- 第一次更新
参考资料
- 1.c++中的变量初始化:https://www.dyxmq.cn/program/code/c-cpp/cpp-variable-default-init.html ↩
- 2.cpp类初始化:https://aiden-dong.gitee.io/2020/01/08/cpp%E7%B1%BB%E5%88%9D%E5%A7%8B%E5%8C%96/ ↩
- 3.C++ 教程:https://cloud.tencent.com/edu/learning/course-1844-21266 ↩
- 4.C语言extern关键词:http://c.biancheng.net/cpp/html/448.html ↩
- 5.C++ 中的static关键字使用场景:https://cloud.tencent.com/developer/article/1695037 ↩
- 6.C++ 循环:https://www.w3cschool.cn/cpp/cpp-loops.html ↩
 微信
微信 支付宝
支付宝
