
C++从零开始(四):务实基础(中)指针和引用
🌟《C++从零开始》 系列,开始更新中…

二、指针&引用
第一次学C++,指针和引用令当时还是初学者的我感到非常的困惑:
- 普通变量就可以代表一块内存区域,我们可以直接使用原始变量,为什么还需要指针?
- 指针解决了普通变量的不足,为什么又引入引用的概念?
- 引用本质是什么?为什么操作引用等价操作变量本体?
希望曾经的我,现在的你可以在本章找到答案。
2.1 指针
2.1.1 为什么需要指针
重新审视变量
变量可以理解为某块内存区域地址别名,这块内存区域保存变量的值。
下面举一个实例:
1 | int x = 0; |
对应汇编代码:
1 | movl $0, -12(%rbp) |
- 当CPU执行
int x = 0,会在内存(这里是栈)腾出一块区域(-12(%rbp))用来存储变量x;然后0被存入x所代表的内存区域(-12(%rbp))。 - 继续执行
x=1,1被存入变量x所代表的内存区域。
可以看到,变量的存在使得我们:不用记住为分配x的内存地址是什么,我们通过变量名x就可以使用分配的内存区域。因为使用x时,编译器会将变量x隐式自动翻译成对应的内存地址,同时进行间接寻址(可以理解为使用x等价于*x)。
1 | int x = 0; // 编译器眼里:int* x = -12(%rbp); *x = 0; |
既然有好用又好记的变量x就可以,为什么还要画蛇添足般地显示使用指针变量,去存储内存地址,再来操作变量x:
1 | // 声明一个指针变量,它存入x的地址 |
对应的汇编代码也变得臃肿起来,因为还多了空间去存储指针p_x(即使没有汇编相关基础也建议阅读一遍):
1 | # -12(%rbp)地址赋值给寄存器rax,也就是变量x的地址 |
现在我们来说说C++中指针的好处。
指针的好处
事实证明,指针在许多情况下都很有用(上面的例子当然是使用变量更好):
- 遍历数组。指针可以很方便的遍历数组,因为数组是使用指针实现的;
- 动态分配内存。在C++中只能使用指针来动态分配内存;
- 函数作为参数时。可以用来将一个函数作为参数传递给另一个函数,即函数指针;
- 实现多态性。它们可用于实现多态性,在面对对象中会详细介绍;
- 指向另一个结构/类。在一些更高级的数据结构中很有用,例如链表和树。
但另一个事实是,除了在C++中,指针的使用并非那么必要。其它的高级语言中,很多已经摒弃了指针(如.NET或Java):
- 遍历数组:传统的for循环、迭代器都可以替代;
- 动态分配内存:很多高级语言如Java不用指针即可动态分配内存(new方式);
- 函数作为参数:在java中可以通过使用接口实例等方式间接实现;
- 实现多态性:java无需指针即可实现;
- 指向另外一个结构类 :java等直接使用引用即可。
最佳实践
根据多位C++大师的建议,实际编码尽量不要使用指针,替代使用引用或者标准库是种更好的方式。
但种种原因,作为一个C++程序员,很多情况还是避免不了去接触和使用。因此,我们还是很有必要深层次了解指针的用法和原理。
2.1.2 指针简介
指针初识
声明指针使用*,这个时候*不是间接操作符,它只是指针语法的一部分:
1 | int a = 10; |
这里有两个注意事项:
- 指针变量在声明时如果没被初始化,默认初始化规则和普通变量一样,可能包含垃圾值(比如局部指针变量);
p_a被称为“整数指针”,实际含义应该是“指向整数的指针”。
👀 眼保健操环节。
区分以下指针类型?
1 | int *p[10] |
指针和数组[] 结合一般才要注意区分,其余情况大多是表示指针。
int *p[10],强调数组概念,此时p表示数组,每个元素都是int*类型;int (*p)[10],用()圈住*p,强调指针概念,此时指针p指向一个int类型数组,等价于int *p = new int(10*sizeof(int));;int *p(int),这是函数声明本质还是指针,指针p存储的函数的地址,后面的(int)表示是个函数。
特别的还有:
1 | int (*p)(int) |
- 同前,用
()圈住*p,更强调指针概念,后面的(int)表示是个函数。
赋值是使用地址运算符&:
从下也可以看到,指针和普通变量在cpu眼中无多大区别,只不过指针用来存储地址。
1 | p_a = &a; // &a获取了变量a的地址。 |
&p_a可获取指针p_a的地址。
1 | cout<<p_a<<endl; // a的地址,0x7ffc4f78721c |
地址运算符需要注意以下几点:
-
地址运算符 (&) 返回不是变量的地址,而是一个包含变量地址的指针 :
1
std::cout << typeid(&a).name() << '\n';
输出:
1
int *
-
指针只能使用左值进行赋值
什么是左(l)值和右(r)值?可参考下一小节:l值和r值。
1
2
3
4
5int a = 0;
int* b = a; // 合法,变量a是左值
int* b = 1; // 非法,文字1是右值
int* b = a+1; // 非法,表达式a+1也是右值
变量可以修改存储其它的值,指针也可以指向其他的内存区域(存取它的地址):
1 | int b = 11; |
使用指针是通过间接操作符* :
1 | cout<< *p_a <<endl ; // 10, 读取值 |
指针大小取决于编译可执行文件的体系结构——32 位可执行文件使用 32 位内存地址——因此,32 位机器上的指针是 32 位(4 字节)。对于 64 位可执行文件,指针将是 64 位(8 字节)。
它和指向的对象大小无关。
1 | int a = 10; |
在作者64位机器上输出:
1 | 8 |
l值和r值
什么是左值(l值)?
左值是具有地址(在内存中)的值。例如:
- 变量是一种左值(读作 ell-value),因为所有变量都有地址;
当我们进行赋值时,赋值运算符=的左侧必须是左值,但=右侧可以是左值也可以是右值。
例如:
1 | int a = 1; // 正确,变量a可作为左值 |
你可能会疑惑为什么表达式a 是左值,a+1 是左值?
因为a+1没有自己的地址(临时计算的结果存入寄存器中),从根本否定了它是左值。
那什么又是右值?
与左值相反的便是右值(r值,即没有内存地址),右值可以文字、表达式等:
1 | int a = 1; // 正确,1是右值 |
特别的,在赋值运算时,所有左值会隐式转换为右值。
1 | int b = a; // a被隐式转换为右值 |
空指针
空指针是一个特殊的指针,可以通过“0”来为指针分配空值,表示没有指向任何东西。
1 | int *p = 0; |
这似乎听起来没什么用?
根据变量的最佳实践,声明时最好进行初始化,这个时候我们可以将指针设为空值完成最佳实践。
如下,此时指针p未被初始化(也称野指针),就被使用了。
1 | int main() |
根据最佳实践声明同时进行初始化,int* p = 0 ,然后再使用。
但使用0值表示空指针不安全,请使用nullptr关键字。
因为文字0不是任何类型,在少数情况下,编译器无法判断我们是使用空指针还是整数0。
1 |
|
输出:
1 | int |
为了解决上述问题,C++11 引入了一个新的关键字nullptr ,称为 空指针。
C++ 会隐式地将 nullptr 转换为任何指针类型。
1 | int *p = nullptr ; |
在上面的例子中,nullptr被隐式转换为整数指针,然后将nullptr的值赋给ptr。这具有使整数指针 ptr 成为空指针的效果。
void指针
void指针,也称为泛型指针,是一种特殊类型的指针,可以指向任何数据类型的对象。
1 | int nValue; |
但也有由于这种不确定的包容特性,我们需要在使用void指针时转换为具体的指针:
1 | *static_cast<int*>(voidPtr) = 1; |
void指针有什么用?
这种特性使得void指针可以在一个函数处理多种类型的数据。
以下函数展示了如何使用“泛型指针”作为函数参数(C++20前是不允许使用auto类型的参数),去处理多种类型的实参。
1 |
|
但一方面它看起来也很傻:
-
因为我们往往有更好的办法替代void指针,比如模板。
相比前面代码更加清晰,简洁。
1
2
3
4
5template <typename T>
void printValue(T ptr)
{
std::cout << ptr << '\n';
} -
void指针也并不安全,它没有类型检查
没有编译器自动的类型检查,你又粗心写作了传入的参数类型,这显然很糟糕。
1
2float fValue2{ 5.4 };
printValue(&fValue2, Type::tInt);
最佳实践:尽量减少使用void指针,除非真的找不到第二个更好的办法来进行替代。
箭头运算符再思考
对于普通类/结构体的对象,我们使用成员选择运算符.选择成员。
1 | struct Person |
但我们也被告知,如果是个指针对象,请使用箭头->运算符:
1 | Person* p_person = &person ; |
但这个时候,我们不禁想起以前如何使用一个指针:
1 | int a = 10; |
使用间接操作符* 让我们获取了指针指向的对象,然后进行操作:
1 | *p_a = 11; |
那么我们用* 获取p_person 指向的结构体对象,不就可以像普通结构体对象一样使用成员运算符.吗?
1 | (*p_person).age = 6; // 等价于:person.age = 6; |
更多的例子:
1 | Person* p_person2 = new Person(); |
2.1.3 指针和数组
指针和数组它们之间的区别有时很具有迷惑性,特别是很多时候编译器会将数组退化成指针使用。以至于有些人错误地将数组等价于指针。
现在我们来进行仔细的区分和总结。
指针加减法
不过在此之前,先了解下指针加减法有利于更好地继续往下分析。
C++ 语言允许对指针执行整数加减运算:
- 如果
ptr指向一个整数,ptr + 1则为ptr之后内存中下一个整数的地址;ptr - 1是前一个整数的地址ptr。
换句话说,在计算指针算术表达式的结果时,编译器总是将整数操作数乘以所指向对象的大小。
1 |
|
输出:
1 | 0x7ffd05328dfc |
可以看到每个地址相差4字节(一个int大小),比如:0x7ffd05328e00-0x7ffd05328dfc=4。这里的地址是虚拟地址,4就表示4个字节。
指针和数组的区别🌟
“万物皆为指针,数组首当其冲”。
声明一个(静态)数组很简单:
1 | int arr1[3] = {1,2,3}; |
但很多时候我们更希望申请一个动态数组(比如声明时并不确定数组的内容):
1 | int* arr2 = new int[3]{1,2,3}; |
new int[3]{1,2,3} 返回了一个int* 指针,存储分配的数组空间首地址,然后赋值给arr2 。
体会一下下面场景下的arr2 和 arr1 表现何其像:
-
作为表达式使用时
此时数组表现的就是指针,存储了数组元素首地址。
1
2
3
4
5
6
7
8
9
10
11
12
13
14int arr1[3] = {1,2,3};
int* arr2 = new int[3]{1,2,3};
// 1.打印数组/指针
cout<<arr1<<endl; // 0x7fff61b6b7d0,数组首元素地址
cout<<arr2<<endl; // 0x97b010,数组首元素地址,因为动态数组分配在堆上不在栈上,地址空间位数显得有些不同
// 2.打印数组/指针首元素
cout<<*arr1<<endl; // 1
cout<<*arr2<<endl; // 1
// 3.打印第二个元素
cout<<*(arr1+1)<<endl; // 2
cout<<*(arr2+1)<<endl; // 2这是因为C++中如果把数组作为表达式使用,会衰减为一个指针。
-
数组作为参数时
将数组作为参数传递时,数组在函数内部表现得已经是一个指针。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
using namespace std;
void printSize(int arr[])
{
cout << "in printArray: " << sizeof(arr) << endl;
}
int main()
{
int array[] = {1,2,3,4,5};
cout <<"in main: " << sizeof(array) << endl;
printSize(array);
return 0;
}输出:
1
2in main: 20
in printArray: 8这种情况是因为,在C++中复制数组代价可能会昂贵。因此将数组传递给函数时,不会复制数组,而是固定数组衰减为指针,然后将指针传递给函数。
- 上述述代码中,数组
array类型是int[5],作为实参时,退化为指针int *,保存的数组中第一个元素的地址即&array[0],然后复制一份给形参arr。 - 题外话,当整个结构或类传递给函数时不会衰减。
也正是因为C++ 使用数组语法 [] 会将数组衰减为指针。这意味着以下两个函数声明是相同的:
1
2void printSize(int array[]);
void printSize(int* array); // 最佳实践:指针语法 (*) 优于数组语法 ([]),它更表明实际接受的参数类型,C++也不用隐式转换 - 上述述代码中,数组
所以说,数组≠指针,只是在某些场景下退化成了指针而已,比如作为表达式或者函数参数时。
更准确来说是退化成了常量指针!因为数组本身默认是常量数组,无法作为左值。
2
3
4
5
6
{
arr = 0x778555622; // error,作为左值
new_arr = new int[]{1,2,3};
arr = new_arr; v // error,作为左值
}
题外话,正由于这种特性,我们往往不得不传递数组参数时还传递数组长度。因为你无法根据指针获取到其长度。
1 |
|
这里我们进行更详细的总结,数组和指针的区别。
数组和指针关键区别在于:类型、是符号不是变量、sizeof等。
-
sizeof:sizeof(数组)打印的是数组的长度(容量*存储类型所占字节数),但是sizeof(指针)打印的是指针长度,一般是4字节或8字节; -
类型:数组类型是
type[LEN],指针类型是type*; -
定义:数组是一个符号,没有自己的存储空间;指针是一个变量,有自己的内存空间,存储其它变量的地址。
可以修改一个指针:
1
2int* array = new int[5]{1,2,3,4,5};
array = NULL; // 正确,array是指针,存储是数组首地址但你尝试修改数组内容是会出错的:
1
2int array[] = {1,2,3,4,5};
array = NULL; // 编译错误,array是符号,不是可以被修改的左值另外,如果你尝试打印
array的地址,也会发现它并没有属于自己的地址:1
2
3int array[] = {1,2,3,4,5};
cout<<array; // 0x7ffffabf61f0,array[0]的地址
cout<<&array; // 0x7ffffabf61f0,没有数组自己的地址,而是array[0]的地址&array返回一个指向整个数组的指针,这个指针也指向数组的第一个元素,只是类型信息不同(类型&array是int(*)[5])。但是每个指针都有自己的地址:
1
2
3int* array = new int[5]{1,2,3,4,5};
cout<<array; // 0x7f3010,array[0]的地址
cout<<&array; // 0x7ffcff233b48,指针本身的地址 -
修改。数组无法被重新初始化/分配,指针(动态数组)可以。
[]再理解
前面我们提到,C++ 使用数组语法 [] 会将数组衰减为指针* ,让我们更好地访问数组元素:
1 | int arr1[3] = {1,2,3}; |
上述事实证明,当编译器看到下标运算符([])时,它实际上将其转换为指针加法和间接寻址。
为了更好说明这一点,请看下面代码:输出会是什么呢?
1 |
|
输出:
1 | 2 |
下标运算符 ( []) 等同于加法和间接法,操作数可以交换,因此它等价于:
1 | *(2+arr) |
cout 和数组
不知道读者有没有注意到一个有趣的事情,cout会自动遍历char数组打印所有字符。
1 | char c_arr[] = "hello"; |
输出:
1 | hello |
理论上,此时输出应该是数组首选组h的首地址。就像下面的int数组:
1 | int i_arr[] = {1,2,3}; |
输出:
1 | 0x7fff74ecdc70 |
这是因为std::cout上的<<运算符已重载, 实际上是几个不同的函数,都命名为operator<<。它的行为取决于操作数类型,编译器由此决定要调用哪个函数。
如果给它一个char*或const char*,它会把操作数当作一个指向C样式字符串(第一个字符)的指针,并顺序移动输出剩下的字符串。
上面99% 的情况下都很棒,但它依旧可能会导致意想不到的结果。
下面代码尝试打印一个char类型字符的地址。
1 |
|
输出:
1 | Q╠╠╠╠╜╡4;¿■A |
好吧,这种情况不一定会发生,编译器可能已经给我们做了优化。但是如果发生了,你需要知道为什么:
&c具有char*类型,因此std::cout尝试将其打印为字符串,直到遇到\0;- 但很不幸地下一个地址是垃圾值,直到它终止前打印了一堆垃圾字符串。
这个例子在现实情况不太可能发生,但对我们理解std::cout 如何工作很有帮助。
2.1.4 指针和const
指针和const的组合通常让人感觉很迷惑,国内的相关考试也没少折磨过作者。本节,作者将尽量尝试用清晰、简洁的语言说明。
指向常量的指针
一个指向常量值的指针是指向常量值的(非常量)指针,它通常被如此声明(const位于*左侧即可):
1 | int value = 5; |
“指向常量值的指针”,这里强调了两个要素:
- 指针是非const的,所以它本身可以被修改(存储的地址);
- 指针指向的变量是const的,它不能通过指针被修改(存储的地址对应的内存区域,即变量)。
听起来有点绕,举个例子说明:
-
指针指向的变量无法被修改
1
2
3
4int value = 5;
const int* p_value = &value; // 指向“const int”
// 尝试修改变量value的值
*p_value = 6; // 非法更深刻地理解:指针指向整个内存区域都不能被修改。
1
2const int* p_array = new int{1,2,3};
cout<<*(p_array+1)<<endl; // okp_array指向的好像只是是首元素(保存的是首元素地址),但其实应该理解为,指向的是分配给数组的整个连续内存区域。如下,
p_array所指向的内存区域任意数组元素都不能被修改:1
*(p_array+1) = 0; // 等价于:p_array[1] = 0;
出错:
1
error: assignment of read-only location ‘*(p_array + 4u)’
这种做法也使得我们可以放心地定义指向常量的数组。
-
指针本身可以被修改
1
2
3
4
5
6int value = 5;
const int* p_value = &value; // 指向“const int”
// 尝试修改指针的值
int value1 = 6;
p_value = &value1; // 合法
那怎么让指针本身可以无法被修改?
常量指针
常量指针,可以使得指针本身无法被修改,即指针对应内存区域存储的值(通常是存储一个地址)。
它通常被如此声明(const位于*右侧):
1 | int value = 5; |
“常量指针”,同样包含了两个要素:
- 指针是const的,所以它本身不可以被修改(存储的地址);
- 指针指向的变量是非const的,它能通过指针被修改。
依旧是举个例子说明:
1 | int value1 = 5; |
好吧,或许有些变态般的需求,指针指向的值和指针都不可以被修改。请看下个小节。
指向常量的常量指针
最后,可以通过在类型之前和变量名之前使用const关键字,来声明指向const 值的 const 指针:
1 | int value = 5 ; |
正如你所需要的,指针和其指向的变量都无法被修改。
最佳实践
或许你有些疑问:const可以让指针或变量不被修改,很多时候可以保持程序的严谨、健壮性。这看起来确实有些优点,但它真的那么重要吗?
事实上,const非常重要&有用!
- 多位大师,比如候捷就曾说过:“程序写得是否大气严谨,大胆使用const就是直观的评价指标”。
- 所以,大胆的在你的代码中使用const吧。
扩展:函数与const
选择性阅读:本节额外涉及到,3.4 函数参数 & 面对对象基本知识。
const是衡量一个程序员是否老道的一个标准,除了修饰变量之外,主要便用于修饰函数。
1 | const int& fun(int& a); // 修饰返回值 |
-
const修饰返回值
const常用于返回值是引用类型的时候。
由于通常不会是局部变量的引用(返回局部引用是危险的,3.5.3节),那么通常是返回是,函数参数/成员变量/全局变量等。如果我们并不希望它们被修改,使用const修饰便可以做到这一点。
举个例子。
下面演示了没有const修饰函数返回值时,出现了我们并不期望的情况。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
using namespace std;
class Salary
{
private:
int base; // base是不期望被修改的,但无法在这里被声明为const
public:
Salary()
{
base = 20000;
}
~Salary(){};
int& get_base()
{
return base;
}
};
int main()
{
Salary s;
// 修改base
s.get_base() = 22000;
// 修改成功
cout<<s.get_base()<<endl;
return 0;
}输出:
1
22000
但是,我们如果用const修饰函数返回值,私有成员
base便无法被修改(无法作为左值)。1
2
3
4const int& get_base()
{
return base;
}再次尝试修改会报错:
error: assignment of read-only location ‘s.Salary::get_base()’1
2// 再次尝试修改base,非法
s.get_base() = 22000; -
const修饰形参
多数情况下,我们都会选择 pass by reference(按引用传递参数)。如果我们不希望修改实参的话,传递的引用参数请务必优先考虑加上const关键字。
这个很好理解。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
using namespace std;
void onlyPrint(const int& b)
{
b = 1; // error,b无法作为左值
cout<<b<<endl;
}
int main()
{
int a = 0;
onlyPrint(a);
return 0;
}特别的,值传递传递用const修饰没有意义,因为形参本来就是拷贝了实参一份,和实参无关。
1
2
3
4void onlyPrint(const int b) // 无意义,形参b和实参a完全独立
{
...
} -
const成员函数
这种情况多数情形下很容易被忽视,其实这个是非常重要的一个内容。
在前面const返回值避免了私有成员
base被修改,但是依旧可能在函数返回前就不小心把base修改了:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
using namespace std;
class Salary
{
private:
int base; // base是不期望被修改的
public:
Salary()
{
base = 20000;
}
~Salary(){};
const int& get_base()
{
base = 22000; // 不小心在return前就修改了base
return base;
}
};
int main()
{
Salary s;
cout<<s.get_base()<<endl; // 22000
return 0;
}这个时候我们可以用const修饰整个成员函数,去避免成员函数修改对象成员变量 。
1
2
3
4
5const int& get_base() const
{
base = 22000; // error,无法修改base
return base;
}不过我们依然有疑问,const成员函数修饰了究竟是什么?
为什么要发出这种疑问,作者是不是神经质了?请看下例。
假设此时的
get_data()还没有被const修饰,也没做什么修改对象成员的事(很乖):1
2
3
4const int& get_base()
{
return base;
}你尝试调用
get_data方法出错了:1
2const Salary s;
s.get_base();报错:
1
error: passing ‘const Salary’ as ‘this’ argument of ‘const int& Salary::get_base()’
好吧,不要和我说常量对象不能调用非常量函数之类的,我更想知道上面的报错是什么意思,深层次的原因是什么…
报错大意是说,
get_base()函数有一个参数叫做this,尝试将实参const Salary传递给this时出错。这由此需要解释两个问题:get_base()哪来的叫做this参数?this指针是什么?
其实在C++中任何成员函数的参数都隐含
this指针,不过不需要你显示写出来(熟悉python的同学是不是立马想到self?)。比如,我们的
get_base在编译器眼中应该是这样的:1
2
3
4const int& get_base(Salary* this)
{
return base;
}this指针指向正在操作成员函数的对象(在这里是s),此时对象的类型是const Salary。调用
s.get_base()在编译器眼里等价于:1
2const Salary s;
s.get_base(&s);而我们的
get_base函数参数类型是Salary*,传递的形参&s类型是const Salary*。它们是不匹配的,故报错。这也说明了,const 成员函数其实就是修饰了成员函数中this参数,也就是当前对象。
1
2
3
4
5const int& get_base() const
{
base = 22000; // 不小心在return前就修改了base
return base;
}等价于:
1
2
3
4
5const int& get_base(const Salary* this)
{
this->base = 22000; // 修改常量对象this,故出错
return base;
}
扩展:类对象和const
const修饰的对象,不能进行修改对象成员变量的尝试。
最明显的一点就是,const修饰的对象不能调用非const修饰的函数,即使函数没有修改任何数据成员。
1 |
|
通过编译也很简单,const修饰函数即可:
1 | int& print_base() const |
2.1.X 智能指针🌟
从内存泄漏说起
和内存碎片概念区分。
一般我们常说的内存泄漏是指堆内存的泄漏。
使用malloc,、realloc、 new等函数从堆中分配到块内存后,没有相应的调用free或delete释放该内存块,导致这块内存就不能被再次使用。这就是内存泄漏。
-
例1,双重分配泄漏内存。
1
2int* ptr = new int();
ptr = new int(); // ptr指向了新一块内存,原来存储的内存地址丢失 -
例2,类似指针不释放原先指向的内存区域。
1
2
3int value = 5;
int* ptr = new int(); // 堆上分配内存,返回分配的内存首地址
ptr = &value; // 堆上内存没有释放,其ptr保存的地址丢失
上面感受可能不够直观,我们来举个具体例子。
下面一个很简单int堆内存(4字节)忘记使用delete释放,执行了百万次(比如线上代码的高频基础函数),便损失了40M内存。
1 |
|
输出(栈占用了1M内存):

试想:如果不是简单int,而是复杂的大对象,很快就能把服务器所有内存干完。
避免内存泄漏的几种方式
在C++11前,我们通常通过以下方法尽量保证内存不被泄漏。
-
利用"查找"功能,查询
new与delete,看看内存的申请与释放是不是成对释放的,这使你迅速发现一些逻辑较为简单的内存泄漏情况。 -
计数法:使用new或者malloc时,让该数+1,delete或free时,该数-1,程序执行完打印这个计数,如果不为0则表示存在内存泄漏;
-
将基类的析构函数声明为虚函数,让子类去调用父类的析构函数,避免父类没有申请的空间没有被释放。
当然,我们还可以使用一些检测工具:
- Linux下可以使用Valgrind工具
- Windows下可以使用CRT库
但无论如何,在传统 C++ 中,『记得』手动释放资源,总不是最佳实践。
人远没有机器可靠,我们总可能在什么时候就忘记去是否内存资源。幸运的是,在C++11智能指针的概念中,对对象使用了引用计数,让程序员不再需要关心内存释放问题。
智能指针简介
为了减少出现内存泄漏的情况,在C++ 11 中,移动语义的引入,结合 RAII ,采用代理模式的思想,管理动态分配对象的生命周期。
C++11提供四种智能指针供使用:
| 指针类别 | 支持 | 备注 |
|---|---|---|
unique_ptr |
C++ 11 | 拥有独有对象所有权语义的智能指针 |
shared_ptr |
C++ 11 | 拥有共享对象所有权语义的智能指针 |
weak_ptr |
C++ 11 | std::shared_ptr 所管理对象的弱引用 |
auto_ptr |
C++ 17中移除 | 拥有严格对象所有权语义的智能指针 |
本文主要关注, std::shared_ptr、std::unique_ptr、std::weak_ptr,使用它们需要包含头文件 <memory>。
std::shared_ptr
std::shared_ptr 是一种智能指针,一个动态分配的对象可以在多个 std::shared_ptr 之间共享。
-
对象每多一个
shared_ptr指针计数就+1,反之-1;为保证线程安全,引用计数的增减必须是原子操作。
-
动态分配的控制块包括了引用计数,弱引用计数,自定义的析构器等等数据。
配套使用的还有std::make_shared方法 :
- 消除显式的使用
new,分配创建传入参数中的对象, 并返回这个对象类型的std::shared_ptr指针。
这样一来,std::shared_ptr 能够通过访问引用计数来确定自身是否是最后一个指向该对象的:如果是,则析构该对象;否则将引用计数减一。
一个简单使用实例。
1 |
|
std::shared_ptr 还有其它的一些有用方法:
get()方法来获取原始指针;reset()来减少一个对象的引用计数;use_count()来查看一个对象的引用计数。
使用auto 关键字替代std::shared_ptr<int> 声明。
*注释的数字表示一开始声明的对象,被多少shared_ptr所指向。
1 | auto pointer = std::make_shared<int>(10); // 1 |
std::shared_ptr 看着很美好,但它存在循环引用的问题。
请看下例。
1 |
|
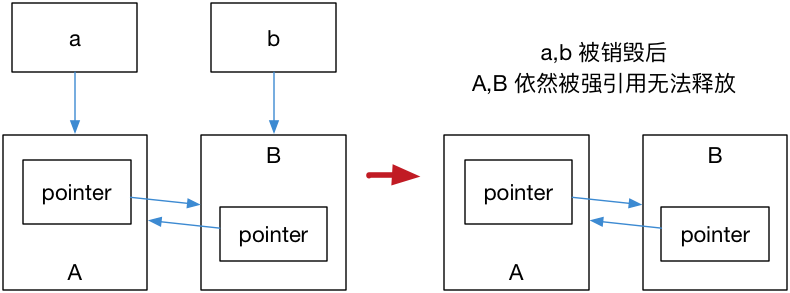
此时运行对象A、B均不会被销毁(引用计数不为0)。
1 | 1 |
- main 函数退出前,B 对象的引用计数为2,A 对象的引用计数为 2;
- main 函数退出后:b 指针销毁,B 对象的引用计数变为 1;a 指针销毁,A 对象的引用计数变为1;
这样就导致了 对象A、B的内存区域引用计数不为零,而外部已经没有办法找到这块区域了,也就造成了内存泄漏。
std::weak_ptr 的存在便可以解决这个问题。
std::weak_ptr
std::weak_ptr是一种弱引用(相比较而言 std::shared_ptr 就是一种强引用)。
std::weak_ptr 是针对 std::shared_ptr 功能的扩展, 不能解引用,也不能检查是否为空,主要作用是用于观察 std::shared_ptr 的内部状态,查看其引用计数,查看指针是否空悬,是一种具有临时所有权语义的智能指针。
为什么需要std::weak_ptr?
一种常用的用法就是前面所说,打断 std::shared_ptr 所管理的对象组成的环状引用。
上代码解释。
和前面唯一的区别是只在结构体B内部替换了std::shared_ptr --> std::weak_ptr。
1 | struct A |
主函数中:
1 | int main() |
执行结果,一切岁月静好(析构函数被执行):
1 | 1 |
可见弱引用不会引起引用计数增加(A对象的引用计数始终是1),当换用弱引用时候,最终的释放流程如图所示(虚线表示弱引用):
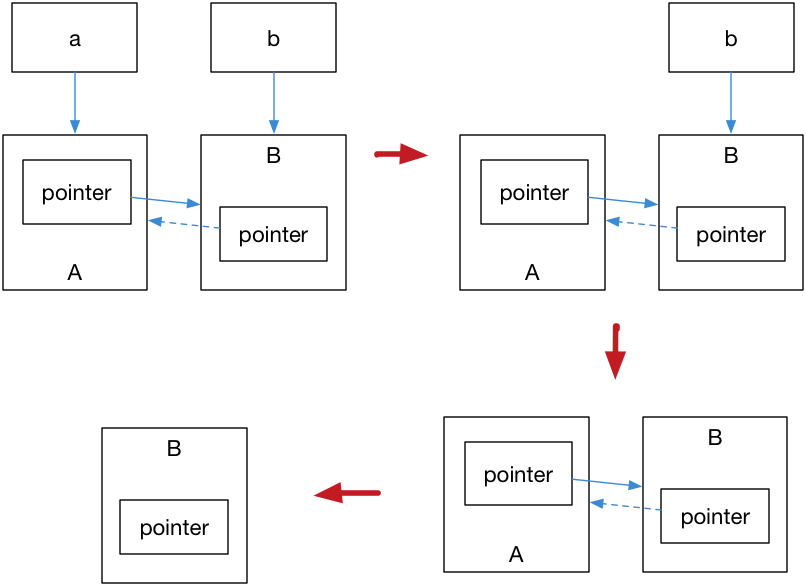
- main 函数退出前,B 对象的引用计数为2,A 对象的引用计数为 1;
- b 指针销毁,B 对象的引用计数变为 1;
- a 指针销毁,A 对象的引用计数变为0,A 对象立刻析构,A 对象析构的过程中会导致其包含的 b 指针被销毁,从而导致 B 对象的引用计数变为0,使得 B 对象也被正常析构。
std::unique_ptr
在前面std::shared_ptr,可以使得多个智能指针共有一个对象:
1 | auto pointer = std::make_shared<int>(10); // 引用计数:1 |
然而std::unique_ptr 是一种独占的智能指针, 是具有专属所有权语义(exclusive ownership semantics)的智能指针,它禁止其他智能指针与其共享同一个对象,从而保证代码的安全。
为什么需要std::unique_ptr?
- 避免内存泄漏,这没什么好说的;
- 避免更大开销,相比于shared_ptr,它的开销更小,甚至可以说和裸指针相当,它不需要维护引用计数的原子操作等等。
回到前面,既然std::unique_ptr是独占,也就是不可复制。
1 | auto pointer = std::make_unique<int>(10); // 引用计数:1 |
std::make_unique 在C++14才被支持(C++11委员主席原话说他忘了)需要我们自己实现:
1 | template<typename T, typename ...Args> |
虽然unique_ptr不能复制,但我们可以利用 std::move 将对象所有权转移给其它的 unique_ptr,例如:
1 |
|
输出:
1 | 执行Foo构造函数 |
- 创建对象,构造函数进行初始化并由智能指针
p1管理,输出“执行Foo构造函数”; - 执行foo函数,输出“执行Foo函数foo”;
std::move转移原先p1所指向的Foo对象(内存区域)所有权转移给了p2,因此并没有创建新对象,故代码16行处不会产生输出;- 执行foo函数,“执行Foo函数foo”;
p2管理的对象离开作用范围,析构函数自动执行,“执行Foo析构函数”。
2.2 引用
在本章开篇我们便已提到,尽量避免使用指针。最重要的原因便是指针它的不安全性与不确定性,一个crazy的野指针可能会让你更加crazy。
条件允许的话,请多多使用引用:
- 更安全。引用使用前必须初始化,且不能为空;指针可以随意改变他的指向的对象(野指针的一大温床),但引用不可以。
- 效率更高。指针最后析构时,要处理内存释放问题。
- 数组不会退化为指针。将数组引用作为参数时,不会像指针传递一样退化为指针。
现在我们来进行更详细的介绍。
2.2.1 引用简介
引用初识
声明一个引用很简单,类型+& 即可:
1 | int a = 0; |
引用就是变量的别名,对引用的任何操作等价于操作于本体。
1 | b = 1; |
变量a、b被视为同义词。在b上返回地址,会打印a的地址:
1 | std::cout << &a << '\n'; // 0x7fff16db208c |
特别的引用还有两个重要特性:
-
无法修改引用指向,可以理解为引用默认就是常量引用。
1
2int c = 2;
b = c; // 等价于:b=2,无法重新指向c -
就像指针一样,引用只能用左值(l值)进行赋值
(结合下节理解)因为只有左值才有属于自己内存地址,才能引用时间接寻址找到本体变量。
1
2
3
4
5int a = 0;
int& b = a; // 合法,变量b是左值
int& b = 1; // 非法,文字1是右值
int& b = a+1; // 非法,表达式a+1也是右值
从汇编角度看引用
引用到底是什么?变量的别名?是指针?初学者难免都要被绕晕。
这里先给出结论:引用的本质就是一个常量指针,指针在CPU眼中也和一个普通变量没什么区别。
铁证如下,堂下引用还不露出原型?
1 | int main() |
对应汇编代码:
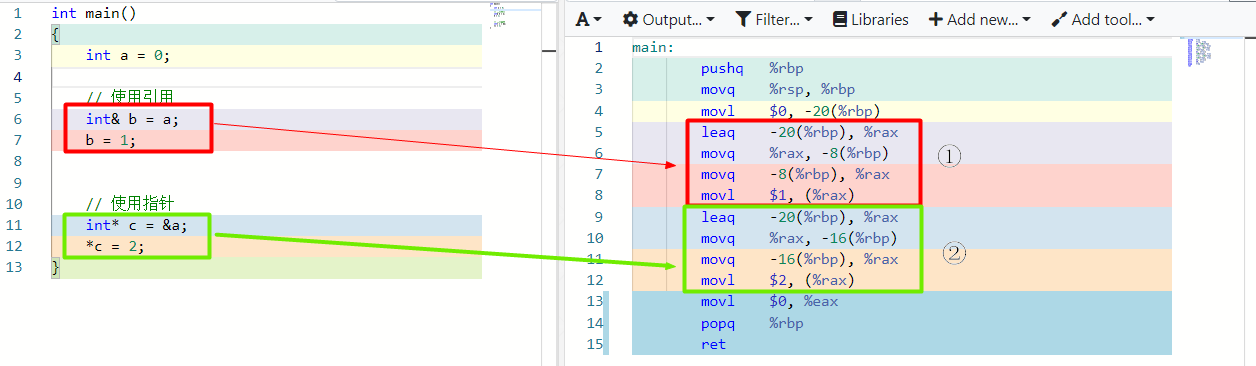
可以看到使用指针(②处)和使用引用(①处)汇编代码基本一致。以指针汇编代码为例:
1 | # 将变量a的地址(-20(%rbp))存入寄存器rax |
这说明,引用在编译器眼里就是一个指针,存储了变量地址,使用引用时编译器会自动加上间接操作符*,本质还是一样的 。
不过这个“指针”还是“常量指针”,所以引用本身无法被修改且必须初始化(const修饰的特性)。
1 | int& b = a; // 编译器眼里等价于:int* const b = &a; |
希望看到这儿的你有种豁然开朗的感觉。
2.2.2 引用和const
前面我们说到,引用本身就不能改变,因此“引用”本来就具备“常量引用”特性(无法修改)。
在C++中也不存在“常量引用”这个概念:
1 | int a = 1; |
但存在指向指向常量的引用。
指向常量的引用
就像“指向常量的指针”,指向常量的引用可以用常量或非常量的左值进行初始化:
1 | int a = 0; |
但指向常量的引用,还可以使用文字右值初始化(这和普通引用/指针不同):
1 | const int& e = 5; // ok |
引用作为函数参数
引用作为函数参数相比指针作为参数更加推荐,原因就是本节开头所说:安全、效率高、避免了数组退化问题。
条件允许的话,我们还建议你尽量使用const修饰引用,这可以避免传递的参数被修改。
1 | void printIt(const int& x) |
2.2.3 指针和引用小结
前面核心内容总结:
- 本质:引用本质就是常量指针,指针本质就是存储了其它变量地址的变量。
- 声明/赋值:引用和指针都只能用左值进行初始化/赋值(但指向常量的引用可以用右值初始化),引用还必须声明时就初始化。
- const+指针/引用:const位于
&/*前后具有不同语义;const让修饰的变量无法被修改。 - 智能指针:善于使用智能指针帮我们自动管理内存释放,循环引用使用
std::weak_ptr进行解决。
指针和引用的区别:
- 本质:指针本质是变量,引用本质是指针也是变量;
- 初始化:引用必须初始化(且不能为NULL),指针不必要初始化(但不初始化就使用是使用野指针);
- 赋值:引用和指针都只能用左值进行初始化/赋值(但指向常量的引用可以用右值初始化);
- 修改:引用一旦初始化之后就不可以再改变,指针变量可以重新指向别的变量;
- …
2.3 功力提升
2.3.1 循环你真的会了吗:for_each&迭代器
少年,想更优雅的遍历假装高手吗?
来使用更简单、更安全的循环称为for-each循环、迭代器替换普通的for循环吧。
for_each
for 循环遍历元素时更加的灵活(比如指定长度的数组元素),但也很容易出错。比如你不小心写错了数组长度:
1 | int arr[] = {1,2,3}; |
for-each 提供了更简单、安全的方式,特别你需要获取所有元素的情况。
- for-each 还适合
std::array、std::vector等容器; - for-each 不适合指向数组的指针(动态数组),因为指针不是数组,无法遍历(根本原因是无法根据指针知道数组的长度)。
for-each语句的语法如下所示:
1 | for (element_declaration : array) |
试一试:
1 | int arr[] = {1,2,3}; |
好起来了。
我们还可以优化上面的程式,让世界更美好:
- 使用引用。for-each 用值复制方式把数组每个元素复制给
num,这显然有点糟糕,使用引用更好。 - const修饰。一个大气的程序员要善于使用const,这里显然不需要改动
这里还是使用auto关键字自动推断类型(懒蛋狂喜)。
1 | int arr[] = {1,2,3}; |
美好的世界值得吟诗一首。
深圳夏天的阳光刺得眼睛眯成一条缝
腾讯大厦外天空蓝得可以看见白云
感觉一切暖洋洋、软绵绵
我也慢悠悠、晃荡荡
好像就要飘去外太空
— by royhuang
迭代器
迭代器 旨在用来遍历容器的对象(例如,数组中的值,或字符串中的字符),提供对每个元素的访问。
迭代器并没有那么神秘,我们熟悉的指针(应该已经熟悉了吧?)就可以当做迭代器。
依旧是改写之前的例子:
1 | const int* begin = arr; |
对于标准库容器 还通常会直接提供对迭代的支持,无需自己写。
以std::array 为例:
1 |
|
输出:
1 | 1 2 3 |
当然你使用for 或者 for_each 循环遍历库容器也是ok的。
小结
-
遍历数组、库容器等可以使用for循环、for_each循环以及迭代器(基于for循环)。
-
库容器都支持迭代器,因此对于库容器,使用for循环+迭代器更好(复杂的循环最好的做法是结合库函数使用,比如
std::sort,2.3.3节介绍)。
2.3.2 使用更好的数组:array&vector
在前面我们详细讨论了固定数组和动态数组,尽管两者都内置于 C++ 语言中,但它们都有缺点:
- 固定数组衰减为指针,这样做时会丢失数组长度信息;
- 动态数组存在混乱的释放问题,并且难以无误地调整大小。
因此我们说使用array&vector替代C++内置数组,是更好的编程实践。
std::array:替代静态数组
std::array 提供固定的数组功能,当传递给函数时不会衰减,而且超出范围时会自行清理。
声明和使用一个std::array变量很简单:
1 |
|
注意到std::array 和普通数组差别很大(可以重新赋值):
1 | my_array = {3,4,5}; // 重新赋值,内置的数组更像是个常量指针,一旦初始化不能重新赋值 |
验证一下std::array 作为函数参数不会退化为指针。
1 |
|
输出:
1 | 9 7.2 5.4 3.6 1.8 |
优化:使用模板让函数支持任意类型的参数、长度的数组。
1 | template <typename T, std::size_t size> |
这涉及到模板相关知识,暂不细表。
当然,std::array不限于数字作为元素,可以在常规数组中使用的每种类型都可以在std::array中使用。
请看下面的结构数组。
注意相比普通结构体数组,array结构体数组初始化还要多一对大括号。
1 |
|
输出:
1 | House number 13 has 120 rooms |
std::array有用的方法。
公共代码:
1 |
|
-
获取大小
1
myArray.size(); // 5
-
排序
2.3.3节有详细的介绍。
1
2
3
std::sort(myArray.begin(), myArray.end());
小结:std::array 声明时必须要指定长度有点笨拙,但它有很多优点----比如不会退化为指针、不用手动释放内存,标准库众多函数支持。所以尽可能地去使用它替代普通静态数组吧。
std::vector:替代动态数组
相比std::array 提供固定的数组 ,std::vector 同样会自动管理数组内存,不衰减为指针。
而且 std::vector 还支持可变的数组,也就是动态数组。
一个简单例子,注意到 std::vector声明时不必指明长度(动态数组特性):
1 |
|
类似的,std::vector 作为函数参数不会退化为指针,这里不再重复验证。
std::vector有用的方法。
公共代码:
1 |
|
-
获取大小
1
my_array.size(); // 5
-
调整大小
调大后多余空间默认用
0填充。1
2
3
4my_array.resize(8);
for (int i : my_array)
std::cout << i << ' '; // 1 2 3 4 5 0 0 0向下调整,只打印resize后长度包含的元素。
1
2
3
4my_array.resize(3);
for (int i : my_array)
std::cout << i << ' '; // 1 2 3
小细节:
std::vector中容量和长度并不相等。
长度是数组中使用了多少元素,而容量是在内存中分配了多少元素。
为了避免频繁的resize分配空间(调整数组大小通常代价比较昂贵),std::vector 中长度和容量不一定相等。
下面代码看起来好像一切正常。
1 | std::vector<int> array2 = { 9, 7, 5, 3, 1 }; |
输出:
1 | 5 |
但是我们如果进行resize后再看 :
1 | array2.resize(3); |
输出:
1 | 3 |
容量依旧是5 并没有随之改变,即预留了一些空间,这样如果再次发生resize<=5可以不用重新分配空间。
1 | array2.resize(4); |
输出:
1 | 4 |
leetcode神器:
std::vector还有一大用途是作为堆栈使用。
一个简单的小例子。
1 |
|
有两个细节需注意:
- 容量经过:0–>1–>2–>4,四次调整容量,比较影响性能;
- 当
vector被调整大小时,可能会分配比需要的更多的容量(第三次push进1后,容量从2–>4,而不是2–>3)。
为了避免容量被频繁调整,我们可以提前分配一定容量(leetcode避免超时)。
1 | // 添加到代码14行处 |
再次打印出容量变化:
1 | (cap 5 length 0) |
perfect~整个过程除了第一次调整过容量,便没有再次调整过了。
2.3.3 多使用标准库算法
前面我们说到,库容器std::array、std::vector一大好处就是被标准库支持很多相关算法。
-
对于新手程序员玩家来说,自己写循环遍历数组是经常需要做的事。简单的可能只是为了打印下数组,复杂点可能还要去处理数组排序、查找、计数等。
-
但如果我们使用的库容器,就可以很好配合C++标准库函数,轻松地完成复杂的循环处理操作(大佬预先帮你写好接口不舒服嘛?)。
C++标准库提供的函数功能分为三类:
- Inspectors :检查器,仅只读容器中的数据,比如搜索和计数;
- Mutators :修改器,修改容器中数据,比如排序或分发;
- Facilitators:促进器,根据数据成员的值生成结果。
本节将介绍常用的一些算法,虽然只是一小部分,但是大部分算法工作方式相似。关键在于了解其工作原理,就可以轻松使用其它算法。
遍历:std::for_each
std::for_each简介:
- 输入:列表,每个列表元素的操作规则;
- 输出:指定操作后的列表;
- 应用:当我们希望对列表执行相同操作时。
举例说明:对列表每个元素超级加倍。
1 |
|
输出:
1 | 2 4 6 8 |
相比之下似乎内置的for_each 循环还能实现得更简单?这个例子没看到相比for 循环有什么优势?
- 相比for 循环,for_each 能更清晰表达我们的意图也更不容易出错(不用定义额外的索引变量
i); std::for_each支持并行化,更适合大项目/大数据。
排序:std::sort
std::sort简介:
- 输入:列表,两个元素比较规则;
- 输出:排序后的列表;
- 应用:当我们希望对列表进行排序时。
std::sort 排序实例。
1 |
|
输出:
1 | 99 90 80 40 13 5 |
好消息,因为降序排序很普遍,C++大开方便之门提供了自定义类型std::greater ,而不用我们自己写一个比较函数。
1 | std::sort(arr.begin(), arr.end(), std::greater<int>()); |
注意到,std::greater 调用有点奇怪,因为它是个模板类(参数类型要求是函数指针):1)<int> 传入模板参数,2)类中重载了操作符() ,返回一个函数对象。
查找:std::find & std::find_if
std::find简介:
- 输入:列表,被查找的元素;
- 输出:(找到时)元素的指针,(未找到时)尾元素的指针;
- 应用:当我们希望查找某个元素时时。
下面代码展示:找到容器指定的某个元素,并进行修改替换。
1 |
|
输出:
1 | [root@roy-cpp test]# ./test.out |
如果还希望更灵活去自定义查找规则,请使用std::find_if 。
std::find_if简介:
- 输入:列表,列表每个元素的查找规则;
- 输出:(找到时)元素的指针,(未找到时)尾元素的指针;
- 应用:当我们希望自定义查找某个元素时时。
一个示例,std::find_if查找子字符串“nut”:
1 |
|
输出:
1 | 找到了: walnut |
本来至少需要三个循环,使用标准库函数只用几行代码就完成了。
统计:std::count & std::count_if
std::count和std::count_if统计指定元素或满足自定义的查找规则的元素出现次数。
在下面的示例中,我们将计算有多少元素包含子字符串“nut”:
1 |
|
输出:
1 | 共计:2 nut(s) |
2.3.X 最佳实践
- 善于使用容器+算法库中的函数,而不是编写自己的函数来做同样的事情,这可以使我们的代码更简单、更健壮。
- 具体来说,数组立马想到
std::array、std::vector;简单循环立马想到for_each 或者 std::for_each ;循环还需要结合复杂的操作,请尽量使用std::sort等标准库算法。
更新记录
- 修改智能指针相关描述
- 第一次更新
参考资料
 微信
微信 支付宝
支付宝

